







 本文详细介绍了基于深度学习的Facenet和MTCNN在人脸识别中的应用。Facenet利用embedding和triplet loss实现特征提取和对比,MTCNN则通过多任务级联卷积网络进行人脸检测与对齐。重点讲解了triplet loss的工作原理和网络结构,包括离线与在线的triplet mining策略。同时,文章还提供了MTCNN的模型结构和训练细节,如损失函数、多任务训练和难例挖掘。
本文详细介绍了基于深度学习的Facenet和MTCNN在人脸识别中的应用。Facenet利用embedding和triplet loss实现特征提取和对比,MTCNN则通过多任务级联卷积网络进行人脸检测与对齐。重点讲解了triplet loss的工作原理和网络结构,包括离线与在线的triplet mining策略。同时,文章还提供了MTCNN的模型结构和训练细节,如损失函数、多任务训练和难例挖掘。
论文_2015cvpr:FaceNet: A Unified Embedding for Face Recognition and Clustering
facenet史上最全代码详解:https://blog.youkuaiyun.com/u013044310/article/details/79556099
triplet loss 代码解析:https://blog.youkuaiyun.com/u011918382/article/details/79006782
三元组博客 :https://zhuanlan.zhihu.com/p/35560666
一、MTCNN
一、主要思想:
embedding映射关系:将特征从原来的特征空间映射到一个新的特征空间上,新的特征就称原来的特征嵌入,卷积末端全连接层输出为的特征映射到一个超球面上,使其特征二范数归一化。
通过 CNN人脸图像特征映射到欧式空间的特征向量上,计算不同图片人脸特征的距离,通过相同个体的人脸的距离,总是小于不同个体的人脸这一先验知识训练网络。测试时只需要计算人脸特征,然后计算距离使用阈值即可判定两张人脸照片是否属于相同的个体。识别:如每个人抽取512或者256维度,将维度上的值进行欧式距离计算,小于一个阈值则判定是同一个人,否者不是同一人。
亮点: embedding 嵌入层 特征提取 128 256 512 特征向量
triplet loss 用于粒度比较小的粒度。
二、网络结构:
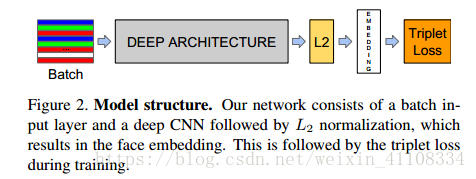
网络结构:传统的卷积神经网络,然后在求L2范数之前进行归一化,就建立了这个嵌入空间(512/256/128维),最后损失函数。
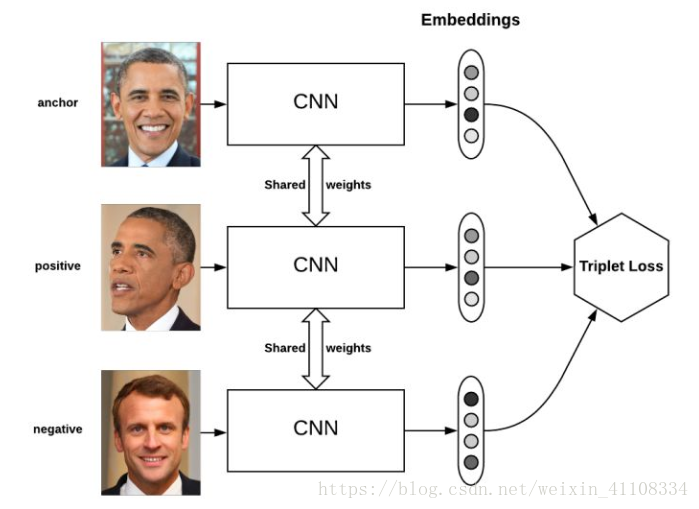
triplet loss 将嵌入层输出 例如:40postive 5个negative mini-batch 选出一个 hard 三元组 然后计算损失 反复 更新参数 更新 嵌入层embedding
三、triplet loss
1、三元组概念
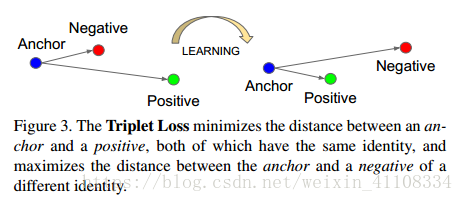
triplet loss 损失函数,用于训练差异性较小的样本
在有监督的机器学习领域,通常有固定的类别,这时就可以使用基于softmax的交叉熵损失函数进行训练。但有时,类别是一个变量,此时使用triplet loss就能解决问题。在人脸识别,Quora question pair任务中,triplet loss的优势在于细节区分,即当两个输入相似时,triplet loss能够更好地对细节进行建模,相当于加入了两个输入差异性差异的度量,学习到输入的更好表示,从而在上述两个任务中有出色的表现。当然,triplet loss的缺点在于其收敛速度慢,有时不收敛。
Triplet loss的motivation是要让属于同一个人的人脸尽可能地“近”(在embedding空间里),而与其他人脸尽可能地“远”。
anchor 为锚点 negative positive,经过learning使得离positive正 距离变小,negative负 距离变大,用于训练差异性较小的样本,
2、三元组定义
triplet loss的目标是:
两个具有同样标签的样本,他们在新的编码空间里距离很近。
两个具有不同标签的样本,他们在新的编码空间里距离很远。
进一步,我们希望两个positive examples和一个negative example中,negative example与positive example的距离,大于positive examples之间的距离,或者大于某一个阈值:margin。
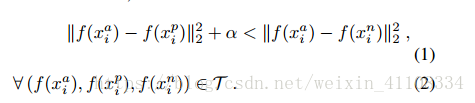
3、LOSS function

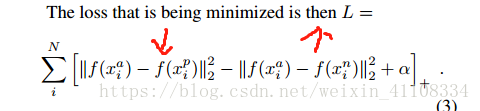 /
/
4、三元组分类 :
为了保证训练的收敛速度,选择距离最远的相同人像hard-positive,和最近的不同人像训练hard negative,在mini-batch中进行选择.

- easy triplets(简单三元组): triplet对应的损失为0的三元组,形式化定义为d(a,n)>d(a,p)+margin。
- hard triplets(困难三元组): negative example 与anchor距离小于anchor与positive example的距离,形式化定义为 d(a,n)<d(a,p)。
- semi-hard triplets(一般三元组): negative example 与anchor距离大于anchor与positive example的距离,但还不至于使得loss为0,即d(a,p)<d(a,n)<d(a,p)+margin。
上述三种概念都是基于negative example与anchor和positive距离定义的。类似的,可以根据上述定义将negative examples分为3类:hard negatives, easy negatives, semi-har
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 759
759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









