







需求:
在word写作中将两个或以上的references合并:[1],[2] 变为 [1,2]
步骤:
-
先将两个引用插入得到下图:
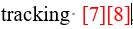
-
选中引用,然后右键选择”切换域代码“(Toggle Field Codes),会得到如下一串
{REF _Ref63434721 \r \h}{REF _Ref63434721 \r \h}
- 分别在第一个引用\h后加入
\#"[0", 第二个引用后加入\#"0]", 在两段代码之间加入 ‘,’ 即可。最后右键选中代码,选择更新域(Update Field)即可实现。
{REF _Ref63434721 \r \h\#"[0"},{REF _Ref63434721 \r \h\#"0]"}
- 最终结果
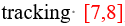

















 8820
8820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









