






第五课 序列模型(Sequence Models)
第一周 循环序列模型(Recurrent Neural Networks)
1.1 为什么选择序列模型?(Why Sequence Models)
循环神经网络(RNN)
在进行语音识别时,给定一个 输入音频片段 x x x, 要求输出 对应的文字记录 y y y
这个例子里输入和输出数据都是序列模型,因为 x x x 是一个按时播放的音频片段,输出 y y y 是一系列单词
1.2 数学符号(Notation)
如果你想建立一个序列模型,它的输入语句是这样的:
Harry Potter and Herminoe Granger invented a new spell
-
这个输入数据是 9 个单词组成的序列,所以最终我们会有 9 个特征集和 来 表示这9个单词
按照序列中的位置进行索引: x < 1 > 、 x < 2 > 、 x < 3 > . . . . . . . x < 9 > {x^{ < 1 > }}、{x^{ < 2 > }}、{x^{ < 3 > }}.......{x^{ < 9 > }} x<1>、x<2>、x<3>.......x<9>,我们将用 x < t > {x^{ < t > }} x<t>来索引这个序列的中间位置
-
输出数据也一样
用 、 、 、 、 、 、 y < 1 > 、 y < 2 > 、 y < 3 > . . . . . . . 、、、、、、{y^{ < 1 > }}、{y^{ < 2 > }}、{y^{ < 3 > }}....... 、、、、、、y<1>、y<2>、y<3>.......表示输出数据
-
用 T x T_x Tx表示输入序列的长度, T y T_y Ty表示输出序列的长度
-
x ( i ) x^{(i)} x(i)表示第 i i i个样本,所以训练样本i的序列中第t个元素用 x ( i ) < t > x^{(i)<t>} x(i)<t>表示
-
如果 T x T_x Tx是序列长度,那么你的训练集里不同的训练样本就会有不同的长度,所以 T x ( i ) T_x^{(i)} Tx(i)就代表第 i i i个训练样本的输入序列长度; T y ( i ) T_y^{(i)} Ty(i)表示第 i i i个训练样本的输出序列的长度
所以这个例子中, T x ( i ) = 9 T_x^{(i)}=9 Tx(i)=9,但如果另一个样本是由 15 个单词组成的句子,那么多余这个训练样本来说, T x ( i ) = 15 T_x^{(i)}=15 Tx(i)=15
怎样表示一个序列里单独的单词, x < 1 > x^{<1>} x<1>实际代表什么?
- 如果想要表示一个句子里的单词,第一件事情是做一张词表,也称词典
- 用one-hot表示词典里的每个单词
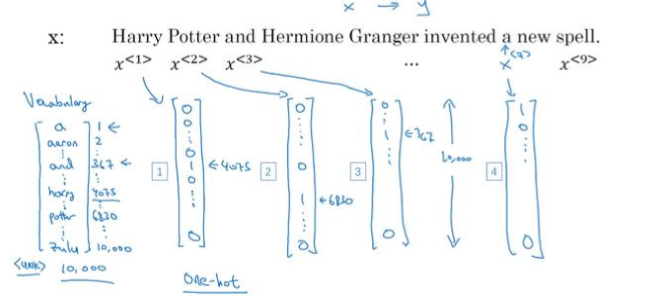
举个例子, x < 1 > x^{<1>} x<1>表示 Harry 这个单词,它就是一个第1075行是1,其余值都是0的向量。因为 Harry 在这个词典里的位置
- 所以这种表示方法中, x < t > x^{<t>} x<t>指代句子里的任意词,它就是 one-hot 向量
目的是用这样的表示方式表示 X X X,用序列模型在 X X X 和 目标输出 Y Y Y 之间建立一个映射
- 如果遇到一个不在词表中的单词,答案就是创建一个新标记, 也就是一个叫做 Unknow Word的伪单词,用 < U n k > <Unk> <Unk>作为标记
1.3 循环神经网络模型(Recurrent Neural Network Model)
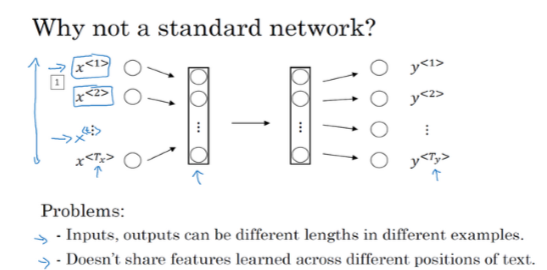
怎样建立一个神经网络学习 X X X到 Y Y Y的映射?
使用标准神经网络,将它们输入到标准神经网络中,经过一些隐藏层,最终会输出9个为0/1的值,它表明每个输入单词是否是人名的一部分。
但这样做有两个问题:
- 输入和输出数据在不同例子中有不同的长度,不是所有的例子都有着同样的 输入长度 T x T_x Tx 或者 同样的输出长度 T y T_y Ty;
- 这样单纯的神经网络结构,它并不共享从文本的不同位置学到的特征。具体说,如果神经网络学习到了再位置 1 出现的 Harry 可能是人名的一部分,那么如果 Harry 出现在其他位置,比如 x < t > x^{<t>} x<t>时,它就不奏效。
- 之前我们提到过那些: 、 、 、 、 、 、 x < 1 > 、 x < 2 > 、 x < 3 > . . . . . . . x < 9 > 、、、、、、{x^{ < 1 > }}、{x^{ < 2 > }}、{x^{ < 3 > }}.......{x^{ < 9 > }} 、、、、、、x<1>、x<2>、x<3>.......x<9>都是 10,000 维的 one-hot 向量,因此这回事十分庞大的输入层。如果总的输入大小是 最大单词书x10000,那么第一层的权重矩阵就会有着巨量的参数
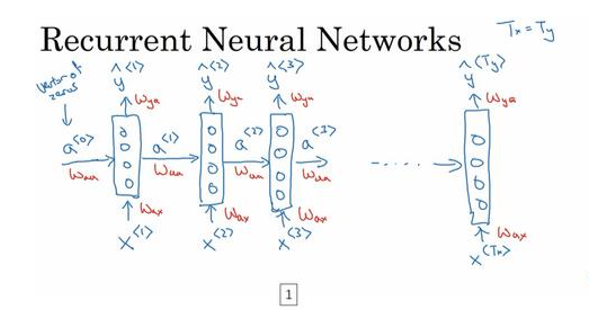
- 从左到右的顺序读这个句子,第一个单词,也就是 x < 1 > x^{<1>} x<1>,要做的就是将第一个词输入一个神经层, 可以让神经网络尝试预测输出,判断是否是人名的一部分
- 循环神经网络读到句子中的第二个单词时,假设是 x < 2 > x^{<2>} x<2>,它不是仅用 x < 2 > x^{<2>} x<2>就预测出 y ^ < 2 > {{\hat y}^{ < 2 > }} y^<2>,它会输入一些来自时间步 1 的信息;具体说:时间步1的激活值会传递到时间步 2
- 在下一个时间步,循环神经网络输入单词 x < 3 > x^{<3>} x<3>,然后它预测出了预测结果 y ^ < 3 > {{\hat y}^{ < 3 > }} y^<3>…等等抑制到最后一个时间步,输入了 x < T x > {x^{ < {T_x} > }} x<Tx>,然后输出了 y < T y > {y^{ < {T_y} > }} y<Ty>
- 至少在这个例子中 T x = T y T_x=T_y Tx=Ty,如果不相等,这个结构需要作出一些改变
- 所以在每一个时间步中,循环神经网络传递一个激活值到下一个时间步中用于计算
- 循环神经网络是从做到右扫描数据的,同时每个时间步的参数都是 共享的,我们用** W a x W_{ax} Wax表示管理着 x < 1 > x^{<1>} x<1>到隐藏层的连接的一系列参数,每个时间步使用着相同的参数 W a x W_{ax} Wax**。
- 而激活值,也就是水平联系是由参数 W a a W_{aa} Waa决定的,同时每个时间步使用的都是相同的参数 W a a W_{aa} Waa。
- 输出结果由 W y a W_{ya} Wya决定

详细讲述这些参数如何起作用
在这个循环神经网络中,意思是在预测 y ^ < 3 > {{\hat y}^{ < 3 > }} y^<3>时候,不仅要使用 x < 3 > x^{<3>} x<3>的信息,还要使用来自 x < 1 > x^{<1>} x<1>和 x < 2 > x^{<2>} x<2>的信息
前向传播过程
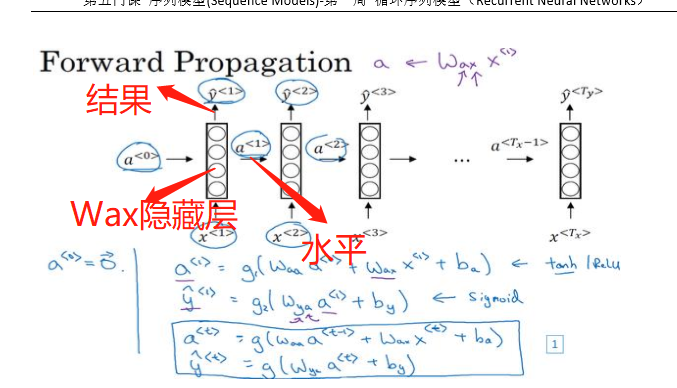
-
首先输入 a < 0 > a^{<0>} a<0>,它是一个零向量
-
接着计算前向传播过程,先计算激活值 a < 1 > a^{<1>} a<1>,然后再计算 y < 1 > y^{<1>} y<1>
a < 1 > = g 1 ( W a a a < 0 > + W a x x < 1 > + b a ) y ^ < 1 > = g 2 ( W y a a < 1 > + b y ) \begin{array}{l} {a^{ < 1 > }} = {g_1}\left( {{W_{aa}}{a^{ < 0 > }} + {W_{ax}}{x^{ < 1 > }} + {b_a}} \right)\\ {{\hat y}^{ < 1 > }} = {g_2}\left( {{W_{ya}}{a^{ < 1 > }} + {b_y}} \right) \end{array} a<1>=g1(Waaa<0>+Waxx<1>+ba)y^<1>=g2(Wyaa<1>+by) -
循环神经网络中的激活函数经常是tanh,也可以是Relu。选用哪个激活函数取决你的输出 y y y
更一般的情况,在t时刻
a
<
t
>
=
g
1
(
W
a
a
a
<
t
−
1
>
+
W
a
x
x
<
t
>
+
b
a
)
y
^
<
t
>
=
g
2
(
W
y
a
a
<
t
>
+
b
y
)
\begin{array}{l} {a^{ < t > }} = {g_1}\left( {{W_{aa}}{a^{ < t - 1 > }} + {W_{ax}}{x^{ < t > }} + {b_a}} \right)\\ {{\hat y}^{ < t > }} = {g_2}\left( {{W_{ya}}{a^{ < t > }} + {b_y}} \right) \end{array}
a<t>=g1(Waaa<t−1>+Waxx<t>+ba)y^<t>=g2(Wyaa<t>+by)
为了帮我们建立更复杂的神经网络,实际要将这个符号简化一下:
W
a
a
a
<
t
−
1
>
+
W
a
x
x
<
t
>
>
>
>
>
a
<
t
>
=
g
1
(
W
a
[
a
<
t
−
1
>
,
x
<
t
>
]
+
b
a
)
{{W_{aa}}{a^{ < t - 1 > }} + {W_{ax}}{x^{ < t > }}}>>>>{a^{ < t > }} = {g_1}\left( {{W_a}[{a^{ < t - 1 > }},{x^{ < t > }}] + {b_a}} \right)
Waaa<t−1>+Waxx<t>>>>>a<t>=g1(Wa[a<t−1>,x<t>]+ba)
定义
W
a
W_a
Wa的方式是将矩阵
W
a
a
W_{aa}
Waa和矩阵
W
a
x
W_{ax}
Wax水平并列放置:
[
W
a
a
⋮
W
a
w
]
=
W
a
\left[ {{W_{aa}} \vdots {W_{aw}}} \right] = {W_a}
[Waa⋮Waw]=Wa
举个例子,如果
a
a
a是100维的,
x
x
x是10000维,那么
W
a
a
W_{aa}
Waa是个(100,100)维的矩阵,
W
a
x
W_{ax}
Wax是(100,10000)维矩阵,因此将两个矩阵堆起来,
W
a
W_a
Wa就会是个(100, 10100)维的矩阵
另外
[
a
<
t
−
1
>
,
x
<
t
>
]
{[{a^{ < t - 1 > }},{x^{ < t > }}]}
[a<t−1>,x<t>]意思是将两个向量堆在一起,用这个符号表示,即:
KaTeX parse error: Unknown column alignment: * at position 24: …{\begin{array}{*̲{20}{c}} {{a^{ …
所以变成了:
KaTeX parse error: Unknown column alignment: * at position 185: …{\begin{array}{*̲{20}{c}} {{a^{ …
对于
y
^
<
t
>
=
g
2
(
W
y
a
a
<
t
>
+
b
y
)
=
g
2
(
W
y
a
<
t
>
+
b
y
)
\begin{array}{l} {{\hat y}^{ < t > }} = {g_2}\left( {{W_{ya}}{a^{ < t > }} + {b_y}} \right)\\ = {g_2}\left( {{W_y}{a^{ < t > }} + {b_y}} \right) \end{array}
y^<t>=g2(Wyaa<t>+by)=g2(Wya<t>+by)
现在
W
y
W_y
Wy表明它是计算
y
y
y类型的量的权重矩阵,而
W
a
W_a
Wa和
b
a
b_a
ba表示这些参数用来计算a类型或者激活值
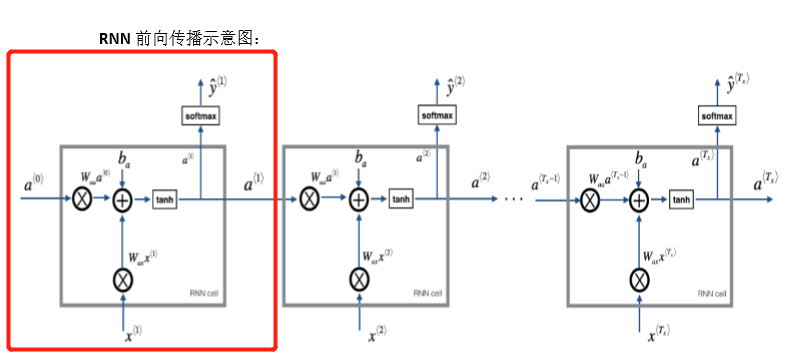
1.4 通过实践的反向传播(Backpropagation through time)
前向传播过程
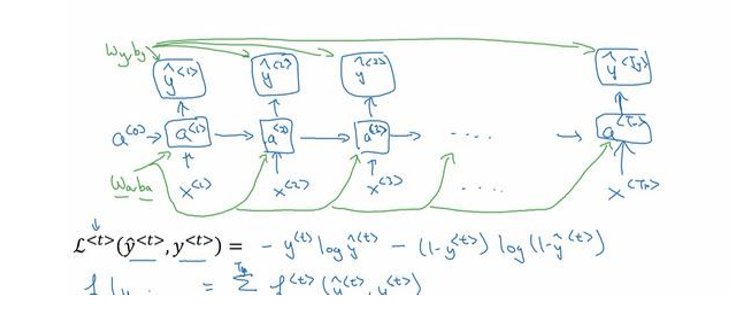
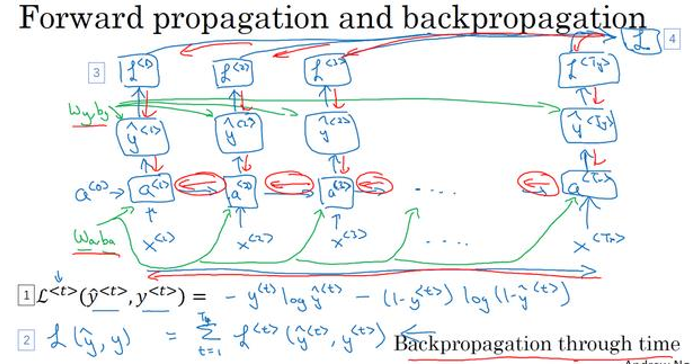
损失函数
-
元素损失函数
L < t > ( y ^ < t > , y < t > ) = − y < t > log y ^ < t > − ( 1 − y ^ < t > ) l o g ( 1 − y ^ < t > ) {L^{ < t > }}\left( {{{\hat y}^{ < t > }},{y^{ < t > }}} \right) = - {y^{ < t > }}\log {{\hat y}^{ < t > }} - (1 - {{\hat y}^{ < t > }})log\left( {1 - {{\hat y}^{ < t > }}} \right) L<t>(y^<t>,y<t>)=−y<t>logy^<t>−(1−y^<t>)log(1−y^<t>)
如果它是某个人的名字,则 y < t > = 1 y^{<t>}=1 y<t>=1,然后神经网络输出的预测值 y ^ < t > {{{\hat y}^{ < t > }}} y^<t>是这个词是名字的概率值,比如0.1 -
整个序列的损失函数
L ( y ^ , y ) = ∑ t = 1 T x L < t > ( y ^ < t > , y < t > ) L\left( {\hat y,y} \right) = \sum\limits_{t = 1}^{{T_x}} {{L^{ < t > }}\left( {{{\hat y}^{ < t > }},{y^{ < t > }}} \right)} L(y^,y)=t=1∑TxL<t>(y^<t>,y<t>)
在这个计算图中,通过 y ^ < 1 > {\hat y^{ < 1 > }} y^<1>可以计算计算出第一个时间步的损失函数,然后计算第二个,最后加起来即是总体损失函数.
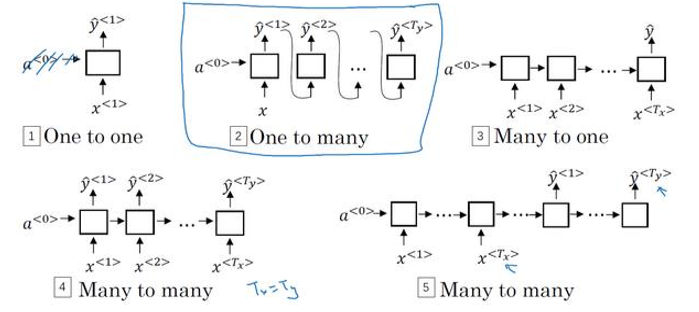
1.5 不同类型的循环神经网络(Different types of RNNs)
基本的RNN结构中 T x T_x Tx和 T y T_y Ty相等:
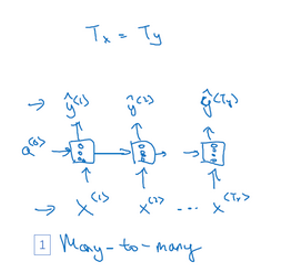
RNN结构中 T x T_x Tx和 T y T_y Ty不一定相等
-
**多对一(many-to-one)**情感分类问题
x x x可能是一段文本,比如一个电影的评论“There is nothing to like in this movie”,所以 x x x是一段 序列,而 y y y可能是1-5之间的数字
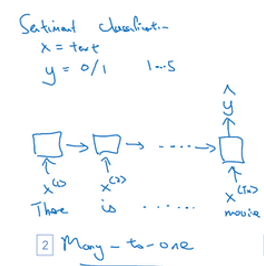
1. 多对一(many-to-one)
我们简化神经网络的结构,输入 、 、 、 x < 1 > 、 x < 2 > 、、、x^{<1>}、x^{<2>} 、、、x<1>、x<2>,一次输入一个单词,我们不再在每个时间上都有输出了,而是让这个 RNN 读入整个句子,然后再最后一个时间上的得到输出.
另外补充一个**一对一(one-to-one)**结构,这就是一个小型的标准的神经网络.
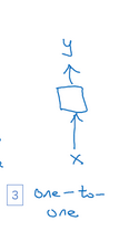
-
**一对多(one-to-many)**音乐生成
目标是使用一个神经网络输出一些音符。对于一段音乐,输入 x x x可以是一个整数(表示你想要的音乐类型或者是你想要的音乐的第一个音符,并且如果你什么也不想输入, x x x可以是一个空的输入,可设置为0向量).
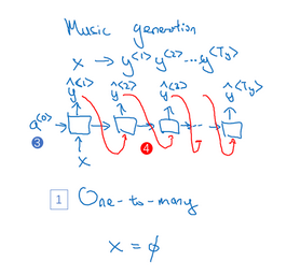
首先是输入 x x x,然后得到 RNN 的输出,第一个值。然后就没有输入了,再得到第二个输出,接着第三个,直到合成出这个音乐作品的最后一个音符。第一个输入写成 a < 0 > a^{<0>} a<0> (编号3) .另外生成序列时,通常会把第一个合成的输出也喂给下一层 (编号4)
-
多对多-输入和输出长度不一样机器翻译
输入句子的单词的数量,比如说一个法语的句子;输出单词的数量,比如说翻译成英语;这两个句子的长度可能是不同的。所以需要一个新的网络结构:
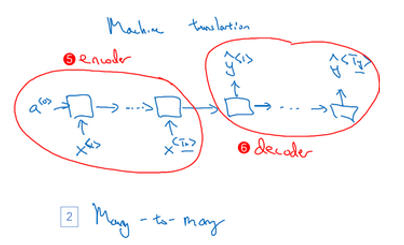
首先读入这个句子,获取输入(5 encoder编码器),然后(6 decoder解码器) 输出翻译结果.有了这种结构, T x T_x Tx和 T y T_y Ty就可以是不同的长度了
总结
1.6 语言模型和序列生成(Language model and sequence generation)
什么是语言模型呢?比如说做一个语音识别系统,你听到一个句子**“The apple and pear(pair) salad was delicious.”**,比如我究竟说了什么?
- The apple and pear salad was delicious?
- The apple and pair salad was delicious?
如果让语音识别系统去选择第二个句子的方法就是使用一个语言模型,它能计算出这两句话各自的可能性。
例如,语音识别模型可能算出
第一句话概率:P(The apple and paid salad) = 3.2 × 1 0 ( − 13 ) 3.2\times10^{(-13)} 3.2×10(−13)
第二句话概率:P(The apple and pair salad) = 5.7 × 1 0 ( − 10 ) 5.7\times10^{(-10)} 5.7×10(−10)
比较这两句话,显然我我说的话更像是第二种,这就是为什么语音识别系统能够在这两句话中作出选择。语言模型所做的是,它会告诉你某个特定的句子它出现的概率是多少。它是两种系统的基本组成部分:
- 语音识别系统
- 机器翻译系统
语言模型做的最基本的工作就是输入一个句子,准确说是一个文本序列, 、 一 直 到 、 一 直 到 、 一 直 到 y < 1 > 、 y < 2 > 一 直 到 y < T y > 、一直到、一直到、一直到y^{<1>}、y^{<2>}一直到y^{<T_y>} 、一直到、一直到、一直到y<1>、y<2>一直到y<Ty>.对于语言模型来说,用 y y y来表示这些序列比用 x x x表示更好,然后语言模型会估计某个句子序列中各个单词出现的可能.
如何建立语言模型
为了使用 RNN 建立这样的模型,首先需要 一个训练集,包含一个很大很大的英文文本语料库(corpus).

假如说,你再训练集中得到这么一句话:“Cats average 15 hours of skeep a day”.
- 你要做的第一件事情就是将这个句子标记化,也就是建立字典,将每个单词转换成对应的one-hot向量,也就是字典的索引.
- 句子的结果,一般增加一个额外的标记,叫做 EOS,可以被附加到训练集中每一个句子的结尾,如果你想要的模型能够准确识别句子结尾的话.
- 另外如果训练集中有一些单词并不在你的字典里,可以标记为 UNK
完成标识化的过程后,一维着输入的句子都映射到了各个标志上,需要将** 设 置 为 设 置 为 设 置 为 x < t > 设 置 为 y < t > 设置为设置为设置为x^{<t>}设置为y^{<t>} 设置为设置为设置为x<t>设置为y<t>**
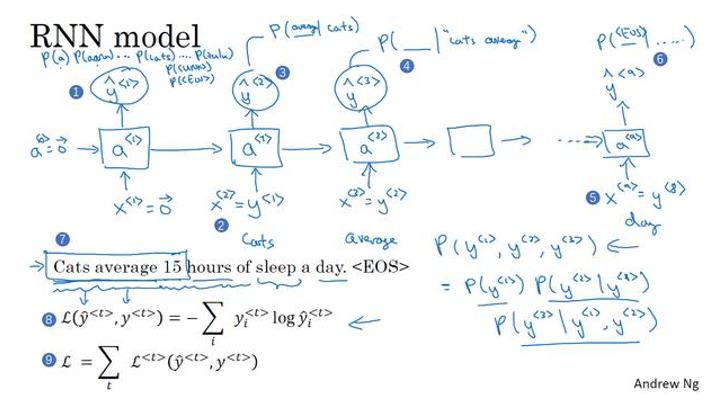
我们来建立 RNN 模型,继续使用“Cats average 15 hours of sleep a day.”,看上图所示
- 在第0个时间步,计算激活值
a
<
1
>
a^{<1>}
a<1>
- 它以 x < 1 > x^{<1>} x<1>作为输入的函数而 x < 1 > x^{<1>} x<1>会被设置为全为 0 的向量,也就是 0向量;
- 之前 a < 0 > a^{<0>} a<0>按照惯例也设置为 0 向量
- 于是 a < 1 > a^{<1>} a<1>做的就是它会通过 softmax 进行预测来计算下一个词可能是什么,其结果就是 y ^ < 1 > {\hat y^{ < 1 > }} y^<1>.这一步其实是通过一个 softmax 层来预测字典中的任意单词会是第一个词的概率.所以其只是预测第一个词的概率,而不去管结果是什么.
- 在这个例子中,最终会得到单词Cats,所以softmax层输出10000种结果,或者10,002个结果(假如了未知词和句子结尾这两个额外的标志)
- RNN 进入下个时间步,在下一时间步中,仍然使用激活项
a
<
1
>
a^{<1>}
a<1>,这一步要计算出第二个词会是什么
- 现在我们传递给他正确的第一个词,我们会告诉它第一个词就是 Cats,也就是 y < 1 > y^{<1>} y<1>,这就是为什么 y < 1 > = x < 2 > {y^{ < 1 > }} = {x^{ < 2 > }} y<1>=x<2>. (编号2)
- 输出结果同样经过 softmax 层进行预测, RNN 的职责就是预测这些词的概率 (编号3),而不去管结果是什么
- 再进行 RNN 的下一个时间步,现在要计算
a
<
3
>
a^{<3>}
a<3>
- 为了预测第三个词,也就是15,我们现在给它之前两个词,告诉它 Cats average 是句子的前两个词,所以这是下一个输入. y < 2 > = x < 3 > {y^{ < 2 > }} = {x^{ < 3 > }} y<2>=x<3>
- 输入 average以后,现在要计算出序列中下一个词是什么
- 以此类推,最后停在第 9 个时间步
- 将 x < 9 > x^{<9>} x<9>也就是 y < 8 > y^{<8>} y<8>传给它,也就是单词 day.这里是 a < 9 > a^{<9>} a<9>,它会输出 y ^ < 9 > {\hat y^{ < 9 > }} y^<9>,最后得到结果会是 EOS 标志.
- 在这一步中,不论前面的单词时什么,我们希望能预测出 EOS 句子结尾标志的概率会很高
所以 RNN 中每一步都会考虑前面得到的句子,比如给它前 3 个单词,让它给出下一个词的分布,这就是RNN如何学习从左到右预测一个词
损失函数
损失元素:在某个时间步t,真正的词是
y
<
t
>
y^{<t>}
y<t>,而神经网络的 softmax 层预测结果是
y
^
<
t
>
{\hat y^{ < t > }}
y^<t>,那么就是 softmax 损失函数
L
(
y
^
<
t
>
,
y
<
t
>
)
=
−
∑
i
y
i
<
t
>
log
y
^
i
<
t
>
L\left( {{{{\rm{\hat y}}}^{ < t > }},{y^{ < t > }}} \right) = - \sum\limits_i {y_i^{ < t > }\log } \hat y_i^{ < t > }
L(y^<t>,y<t>)=−i∑yi<t>logy^i<t>
总体损失: 也就是把所有单个预测的损失函数相加起来
L
=
∑
t
L
<
t
>
(
y
^
<
t
>
,
y
<
t
>
)
L = \sum\limits_t {{L^{ < t > }}\left( {{{\hat y}^{ < t > }},{y^{ < t > }}} \right)}
L=t∑L<t>(y^<t>,y<t>)
预测
如果你用很大的训练集来训练这个 RNN,你就可以通过一系列单词像是 cars average 15 或者 cars average 15 hours of 来预测之后单词的概率.
现在有一个新句子,它是 、 、 、 、 、 、 y < 1 > 、 y < 2 > 、 y < 3 > 、、、、、、y^{<1>}、y^{<2>}、y^{<3>} 、、、、、、y<1>、y<2>、y<3>,只包含3个单词
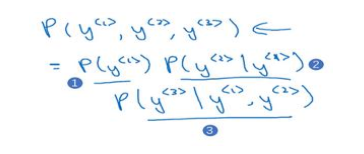
现在要计算出整个句子中各个单词的概率,方法
- 第一个softmax层会告诉你 y < 1 > y^{<1>} y<1>的概率,这也是第一个输出(编号1)
- 第二个softmax层会告诉你在考虑 y < 1 > y^{<1>} y<1>的情况下, y < 2 > y^{<2>} y<2>的概率(编号2)
- 第三个softmax层会告诉你在考虑 、 、 、 y < 1 > 、 y < 2 > 、、、y^{<1>}、y^{<2>} 、、、y<1>、y<2>情况下 y < 3 > y^{<3>} y<3>的概率(编号3)
把三个概率相乘,最后得到这个含3个词的整个句子的概率.
1.7 对新序列采样(Sampling nover sequences)
在在你训练一个序列模型之后,想要了解到这个模型学到了什么,一个非正式的方法就是进行一次新序列采样。
一个序列模型模拟了任意特定单词序列的概率,我们要做的就是对这些概率分布进行采用来生成一个新的单词序列
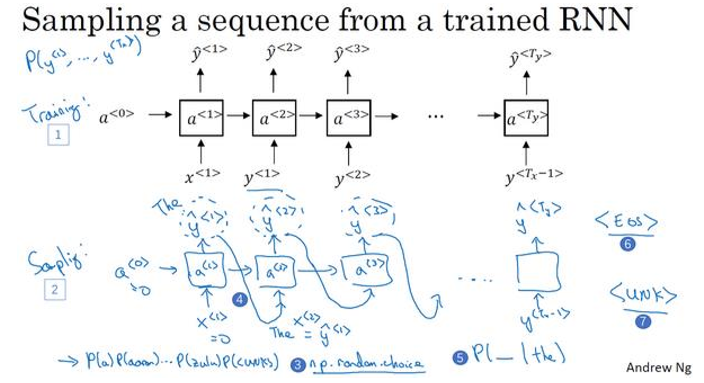
下图编号1所示的网络已经被上方所展示的结构训练过了,而了进行采样,下图编号2所示网络,你要做一些截然不同的事情
-
第一步,对你想要模型生成的第一个词进行采样,于是你输入 x < 1 > = 0 , a < 0 > = 0 x^{<1>}=0,a^{<0>}=0 x<1>=0,a<0>=0.现在第一个时间步得到的是所有可能输出是经过 softmax 层后得到的概率
-
然后根据这个 softmax 的分布进行随机采样,softmax分布给你的信息就是第一个词a的概率是多少,第一个词是aaron的概率是多少,还有这个词是 UNK 的概率是多少,这个标识可能代表句子的结尾
-
然后对这个概率使用例如
np.random.choice,来根据向量中这些概率的分布进行采样,这样就对第一个词进行采样 -
然后继续下一个时间步,记住第二个时间步需要 y ^ < 1 > {\hat y^{ < 1 > }} y^<1>作为输入,现在要做的事把刚刚采样得到的 y ^ < 1 > {\hat y^{ < 1 > }} y^<1>放到 a < 2 > a^{<2>} a<2>(上图编号4所示)中,作为下一个时间步的输入。所以不管你在第一个时间步得到的是什么单词,都需要把它传递到下一个位置作为输入,然后把它传递到下一个位置作为输入,然后softmax就会预测 y ^ < 2 > {\hat y^{ < 2 > }} y^<2>是什么
-
如何知道一个句子结束了?
- 你可一直采样得到 EOS 标记,则代表已经抵达结尾
- 如果你的字典中没有这个词,可以一直采样直到达到所设定的时间步
-
采样过程中会出现未知标识,如何解决
可以一旦出现 UNK,则重新采样,直到得到下一个不是未知标识的词
展示
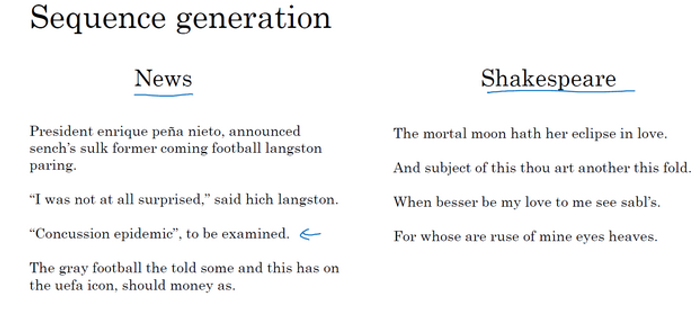
这些就是基础的 RNN 结构和如何建立一个语言模型去使用它,对于训练处的语言模型进行采样。
上面就是 RNN 如何工作,如何应用到具体问题上,比如命名实体识别,比如语言模型,也看到了怎么把反向传播用于 RNN.
1.8 循环神经网络的梯度消失(Vanishing gradients with RNNs)
基本的 RNN 存在不擅长捕获长期以来以及梯度消失的问题,先看图:
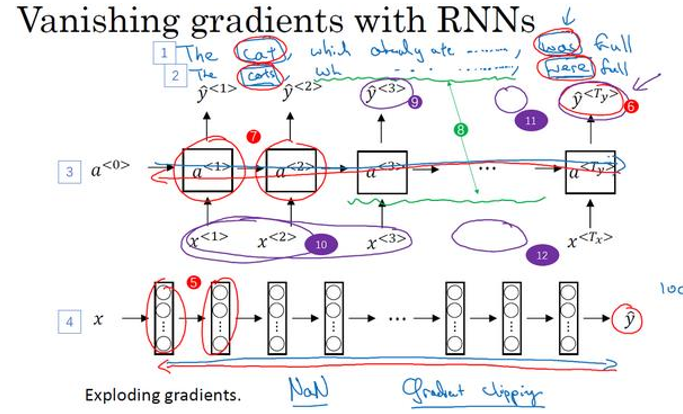
长期依赖
cat是单数,所以用was;cats是复数,所以用were。这个句子有长期的依赖,最前面的句子对句子后面的单词有影响。
梯度消失
对 RNN 来说,首先从左到右向前传播,然后反向传播。但是反向传播会很困难,同样因为梯度消失的问题,后面层的输出误差(编号6)很难影响前面层 (编号7) 的计算。
基本的 RNN 模型会有很多局部影响,一个数值主要与附近的输入有关,因此编号6的输出基本上很难受到序列靠前的输入的影响,也因此很难调整序列前面的计算。
梯度爆炸
梯度裁剪: 观察梯度向量,如果它大于某个阀值,缩放梯度向量保证它不会太大
如果处理一个1000个时间序列的数据集,这就是1000层神经网络,这样的网络会出现梯度消失问题
1.9 GRU单元(Gated Recurrent Unit(GRU))
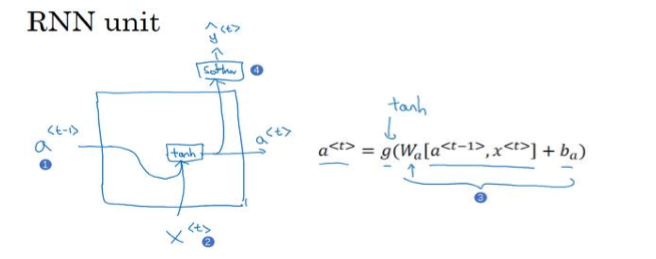
RNN基本公式
a
<
t
>
=
g
(
W
a
[
a
<
t
−
1
>
,
x
<
t
>
]
+
b
a
)
{a^{ < t > }} = g\left( {{W_a}\left[ {{a^{ < t - 1 > }},{x^{ < t > }}} \right] + {b_a}} \right)
a<t>=g(Wa[a<t−1>,x<t>]+ba)
.
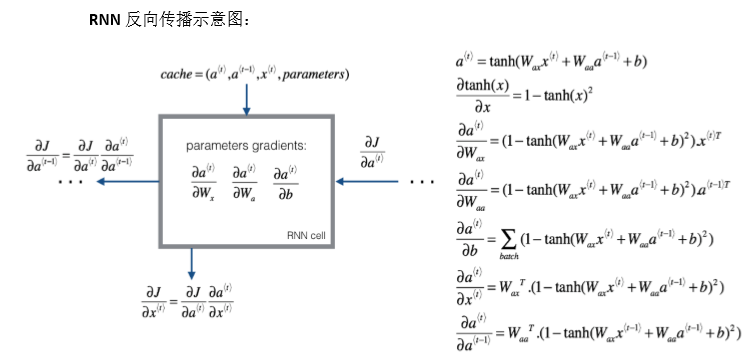
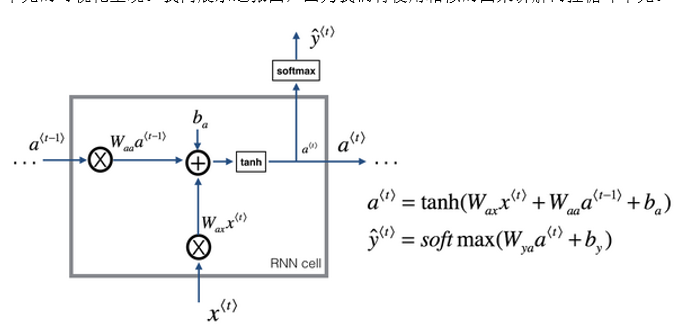
如图所示,在 RNN 的时间 t t t 处,计算激活值.
- 输入 a < t − 1 > ( 1 ) a^{<t-1>}(1) a<t−1>(1),即上一个时间步的激活值
- 再输出 x < t > ( 2 ) x^{<t>}(2) x<t>(2),再把这两个并起来,然后乘以权重项
- 在这个线性计算之后,如果 g g g是一个 tanh 激活函数,再经过 tanh 计算之后得到 a < t > a^{<t>} a<t>
- 激活值 a < t > a^{<t>} a<t>传递给 softmax 单元(4),产生 y ^ < t > {\hat y^{ < t > }} y^<t>
- 或者用于输出 y < t > y^{<t>} y<t>的东西
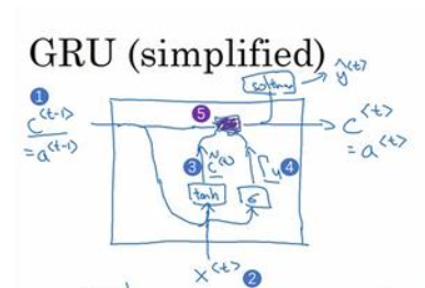
简单版门控循环单元(GRU)
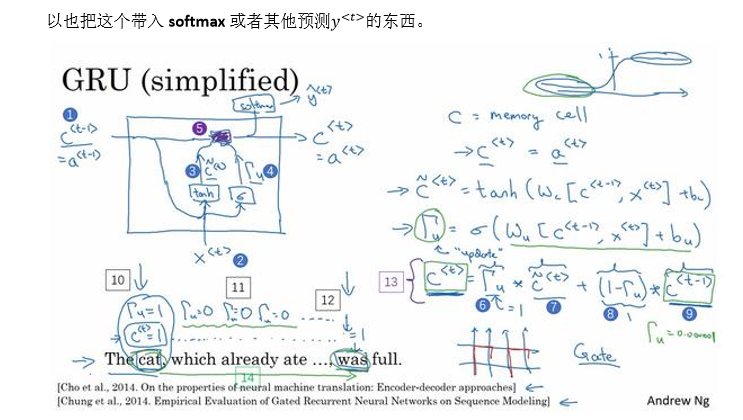
-
GRU 单元输入 c < t − 1 > c^{<t-1>} c<t−1>(编号1),对于上一个时间步,先假设它正好等于 a < t − 1 > a^{<t-1>} a<t−1>,因此把这个作为输入,然后将 x < t > x^{<t>} x<t>也作为输入(编号2),然后将这两个用合适的权重结合起来,再用 tanh计算,计算出 c ~ < t > {\tilde c^{ < t > }} c~<t>,即 c < t > {c^{ < t > }} c<t>的替代值
c ~ < t > = tanh ( W c [ c < t − 1 > , x < t > ] + b c ) {{\tilde c}^{ < t > }} = \tanh \left( {{W_c}\left[ {{c^{ < t - 1 > }},{x^{ < t > }}} \right] + {b_c}} \right) c~<t>=tanh(Wc[c<t−1>,x<t>]+bc) -
再用一个不同的参数集,通过 sigmoid 函数计算出 Γ u {\Gamma _u} Γu,即更新门:
Γ u = σ ( W u [ c < t − 1 > , x < t > ] + b u ) {\Gamma _u} = \sigma \left( {{W_u}\left[ {{c^{ < t - 1 > }},{x^{ < t > }}} \right] + {b_u}} \right) Γu=σ(Wu[c<t−1>,x<t>]+bu)
sigmoid函数在0-1之间,大多数输出总是非常接近0或者1 -
最后所有值通过:
c < t > = Γ u ∗ c ~ < t > + ( 1 − Γ u ) ∗ c < t − 1 > {c^{ < t > }} = {\Gamma _u}*{{\tilde c}^{ < t > }} + (1 - {\Gamma _u})*{c^{ < t - 1 > }} c<t>=Γu∗c~<t>+(1−Γu)∗c<t−1>
如(编号5)所示,也就是紫色方框。输入一个门值(编号6),以及新的候选值(编号7),再有一个门值(编号8)以及 c < t > c^{<t>} c<t>的旧值。一起产生记忆细胞的新值 c < t > {c^{ < t > }} c<t> -
所以 c < t > {c^{ < t > }} c<t>= a < t > a^{<t>} a<t>,或者把这个带入 softmax 或者其他预测 y < t > y^{<t>} y<t>的东西
完整GRU单元
-
要给记忆细胞的新候选值加上一个新的项,添加门$ {\Gamma _r} 你 可 以 认 为 ∗ ∗ r ∗ ∗ 代 表 相 关 性 。 你可以认为**r**代表相关性。 你可以认为∗∗r∗∗代表相关性。 {\Gamma _r} 告 诉 你 计 算 出 下 一 个 告诉你计算出下一个 告诉你计算出下一个c^{} 的 候 选 值 的候选值 的候选值{\tilde c^{ < t > }} 跟 跟 跟c^{}$有多大的相关性:
Γ c = tanh ( W c [ Γ r ∗ c < t − 1 > , x < t > ] + b c ) {\Gamma _c} = \tanh \left( {{W_c}\left[ {{\Gamma _r}*{c^{ < t - 1 > }},{x^{ < t > }}} \right] + {b_c}} \right) Γc=tanh(Wc[Γr∗c<t−1>,x<t>]+bc) -
计算$ {\Gamma _r} 需 要 一 个 新 的 参 数 矩 阵 需要一个新的参数矩阵 需要一个新的参数矩阵W_r$
Γ r = σ ( W r [ c < t − 1 > , x < t > ] + b r ) {\Gamma _r} = \sigma \left( {{W_r}\left[ {{c^{ < t - 1 > }},{x^{ < t > }}} \right] + {b_r}} \right) Γr=σ(Wr[c<t−1>,x<t>]+br)
总结一下:
Γ
r
=
σ
(
W
r
[
c
<
t
−
1
>
,
x
<
t
>
]
+
b
r
)
c
~
<
t
>
=
tanh
(
W
c
[
Γ
r
∗
c
<
t
−
1
>
,
x
<
t
>
]
+
b
c
)
Γ
u
=
σ
(
W
u
[
c
<
t
−
1
>
,
x
<
t
>
]
+
b
u
)
c
<
t
>
=
Γ
u
∗
c
~
<
t
>
+
(
1
−
Γ
u
)
∗
c
<
t
−
1
>
a
<
t
>
=
c
<
t
>
\begin{array}{l} {\Gamma _r} = \sigma \left( {{W_r}\left[ {{c^{ < t - 1 > }},{x^{ < t > }}} \right] + {b_r}} \right)\\ {{\tilde c}^{ < t > }} = \tanh \left( {{W_c}\left[ {{\Gamma _r}*{c^{ < t - 1 > }},{x^{ < t > }}} \right] + {b_c}} \right)\\ {\Gamma _u} = \sigma \left( {{W_u}\left[ {{c^{ < t - 1 > }},{x^{ < t > }}} \right] + {b_u}} \right)\\ {c^{ < t > }} = {\Gamma _u}*{{\tilde c}^{ < t > }} + (1 - {\Gamma _u})*{c^{ < t - 1 > }}\\ {a^{ < t > }} = {c^{ < t > }} \end{array}
Γr=σ(Wr[c<t−1>,x<t>]+br)c~<t>=tanh(Wc[Γr∗c<t−1>,x<t>]+bc)Γu=σ(Wu[c<t−1>,x<t>]+bu)c<t>=Γu∗c~<t>+(1−Γu)∗c<t−1>a<t>=c<t>
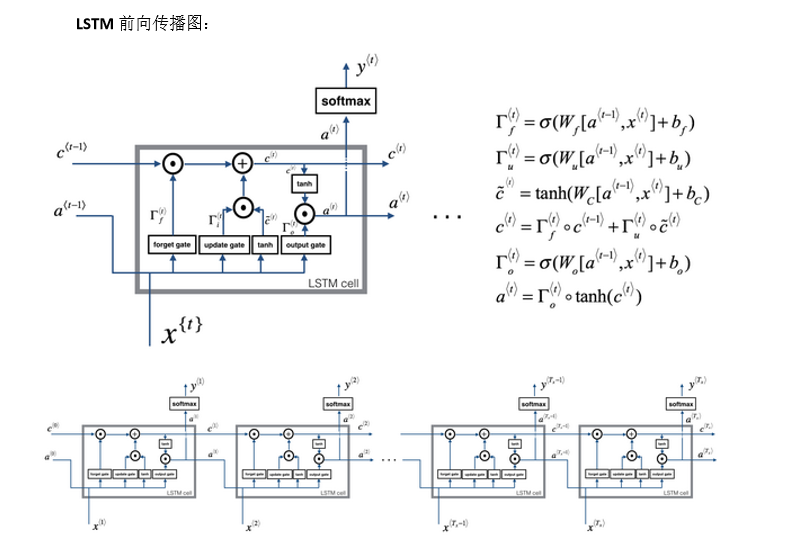
1.10 长短期记忆(LSTM)
LSTM公式
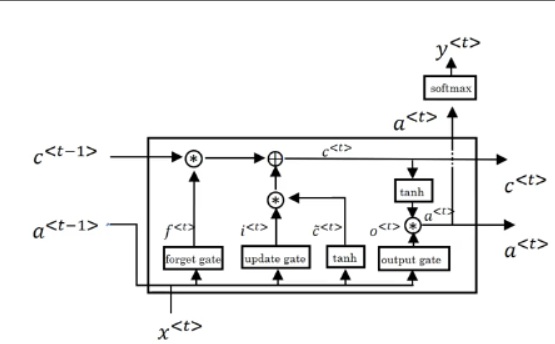
- ($ 1-{\Gamma _u} ) 遗 忘 门 )遗忘门 )遗忘门 {\Gamma _f}$:
Γ f = σ ( W f [ a < t − 1 > , x < t > ] + b f ) {\Gamma _f} = \sigma \left( {{W_f}\left[ {{a^{ < t - 1 > }},{x^{ < t > }}} \right] + {b_f}} \right) Γf=σ(Wf[a<t−1>,x<t>]+bf)
- 像以前那样有一个更新门$ {\Gamma _u} 和 表 示 更 新 的 参 数 和表示更新的参数 和表示更新的参数W_u$
Γ u = σ ( W u [ a < t − 1 > , x < t > ] + b u ) {\Gamma _u} = \sigma \left( {{W_u}\left[ {{a^{ < t - 1 > }},{x^{ < t > }}} \right] + {b_u}} \right) Γu=σ(Wu[a<t−1>,x<t>]+bu)
- 记忆细胞 c ~ < t > {\tilde c}^{ < t > } c~<t>,我们不再有 a < t > = c < t > a^{<t>}=c^{<t>} a<t>=c<t>的情况,现在专门使用 、 或 者 、 或 者 、 或 者 a < t > 、 或 者 a < t − 1 > 、或者、或者、或者a^{<t>}、或者a^{<t-1>} 、或者、或者、或者a<t>、或者a<t−1>:
c ~ < t > = tanh ( W c [ a < t − 1 > , x < t > ] + b c ) {{\tilde c}^{ < t > }} = \tanh \left( {{W_c}\left[ {{a^{ < t - 1 > }},{x^{ < t > }}} \right] + {b_c}} \right) c~<t>=tanh(Wc[a<t−1>,x<t>]+bc)
- 记忆细胞的更新值 c < t > c^{<t>} c<t>:
c < t > = Γ f ∗ c < t − 1 > + Γ u ∗ c ~ < t > {c^{ < t > }} = {\Gamma _f}*{c^{ < t - 1 > }} + {\Gamma _u}*{{\tilde c}^{ < t > }} c<t>=Γf∗c<t−1>+Γu∗c~<t>
所以这就给了记忆细胞选择权去维持旧的值 c < t − 1 > c^{<t-1>} c<t−1>或者加上新的值 c ~ < t > {\tilde c}^{ < t > } c~<t>。所以这里用了单独的遗忘门$ {\Gamma _f} 和 更 新 门 和更新门 和更新门 {\Gamma _u}$
-
最后输出门$ {\Gamma _o}$:
Γ o = σ ( W o [ a < t − 1 > , x < t > ] + b o ) {\Gamma _o} = \sigma \left( {{W_o}\left[ {{a^{ < t - 1 > }},{x^{ < t > }}} \right] + {b_o}} \right) Γo=σ(Wo[a<t−1>,x<t>]+bo) -
输出值: a t = Γ o ∗ c < t > a^{t}={\Gamma _o}*c^{<t>} at=Γo∗c<t>
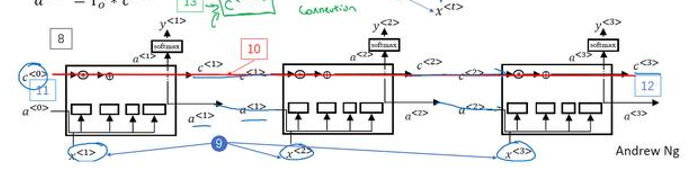
和 和 和 a < t > 和 c < t > 和和和a^{<t>}和c^{<t>} 和和和a<t>和c<t>都将作为下一个时间步的输入传入LSTM中
常用版本
门值步进取决于 a < t − 1 > a^{<t-1>} a<t−1>和 x < t > x^{<t>} x<t>,有时候还可以偷窥一下 c < t − 1 > c^{<t-1>} c<t−1>的值,这叫做偷窥孔连接(peephole connection),意思是门值步进取决于 a < t − 1 > a^{<t-1>} a<t−1>和 x < t > x^{<t>} x<t>,也取决于上一个记忆细胞的值 c < t − 1 > c^{<t-1>} c<t−1>

然后偷窥孔就可以结合这三个门进行( 、 、 、 、 、 、 Γ f 、 Γ u 、 Γ o 、、、、、、 {\Gamma _f}、{\Gamma _u}、{\Gamma _o} 、、、、、、Γf、Γu、Γo)计算,另外前一个 c < t − 1 > c^{<t-1>} c<t−1>值只能影响到 c < t > c^{<t>} c<t>计算.
前向传播
1.11 双向循环神经网络(Bidirectional RNN)
有两个方法可以构建更好的模型:
-
双向 RNN 模型
这个模型可以让你在序列的某点处不仅可以获取之前的信息,还可以获取未来的信息.
-
深层 RNN 模型
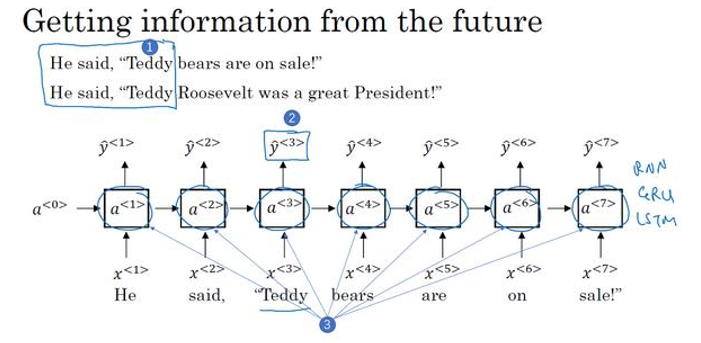
为了判断第三个词 Teddy 是不是人名的一部分,还需要结合后面的信息.

双向 RNN 原理
用4个输入或者说一个只有4个单词的句子, 、 、 、 、 、 、 、 、 、 x < 1 > 、 x < 2 > 、 x < 3 > 、 x < 4 > 、、、、、、、、、x^{<1>}、x^{<2>}、x^{<3>}、x^{<4>} 、、、、、、、、、x<1>、x<2>、x<3>、x<4>,
-
- 这里会有个前向循环单元,叫做 、 、 、 、 、 、 、 、 、 a ⃗ < 1 > 、 a ⃗ < 2 > 、 a ⃗ < 3 > 、 a ⃗ < 4 > 、、、、、、、、、{\vec a^{ < 1 > }}、{\vec a^{ < 2 > }}、{\vec a^{ < 3 > }}、{\vec a^{ < 4 > }} 、、、、、、、、、a<1>、a<2>、a<3>、a<4>,
- 向右的箭头代表前向的循环单元,它们这么连接(编号1).
-
- 我们增加一个反向循环层(编号2),左箭头
- 反向序列从右到左,计算反向的KaTeX parse error: Expected '}', got '\buildrel' at position 12: {{\mathord{\̲b̲u̲i̲l̲d̲r̲e̲l̲{\lower3pt\hbox…\scriptscriptstyle\leftarrowKaTeX parse error: Expected 'EOF', got '}' at position 1: }̲}\over a} }^{ <…等
-
- 这些激活值计算完了就可以计算预测结果了

举个例子,你的网络会有如
y
^
<
t
>
{{\hat y}^{ < t > }}
y^<t>:
KaTeX parse error: Expected '}', got '\buildrel' at position 79: … }},{{\mathord{\̲b̲u̲i̲l̲d̲r̲e̲l̲{\lower3pt\hbox…
1.12 深层循环神经网络(Deep RNNs)

这是一个有三个隐藏层的神经网络,激活值
a
[
2
]
<
3
>
{a^{\left[ 2 \right] < 3 > }}
a[2]<3>,它有两个输入:
a
[
2
]
<
3
>
=
g
(
W
a
[
2
]
[
a
[
2
]
<
2
>
,
a
[
1
]
<
3
>
]
+
b
a
[
2
]
)
{a^{\left[ 2 \right] < 3 > }} = g\left( {W_a^{\left[ 2 \right]}\left[ {{a^{\left[ 2 \right] < 2 > }},{a^{\left[ 1 \right] < 3 > }}} \right] + b_a^{[2]}} \right)
a[2]<3>=g(Wa[2][a[2]<2>,a[1]<3>]+ba[2])
其中
W
a
[
2
]
{W_a^{\left[ 2 \right]}}
Wa[2]和
b
a
[
2
]
{b_a^{[2]}}
ba[2]在这一层的计算都一样的,相应地,第一层也有自己的参数
W
a
[
1
]
{W_a^{\left[ 1 \right]}}
Wa[1]
对于 RNN 来说,有三层就已经不少了。由于时间的维度, RNN 网络会变得相当大,即使只有很少的几层,很少会看到这种网络堆叠到 100 层。
但有一种比较多见,在每一个上面堆叠循环层,没有水平方向上的连接

通常这些单元(编号3)没有必要时标准的 RNN,也可以是 GRU单元,或者LSTM单元,并且你可以构建深层的 双向RNN


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









