







EFK日志收集-Fluentd
简介
此处EFK指的是Elasticsearch+Fluentd+Kibana,主要用于收集宿主机日志。
组件介绍
Elasticsearch + Fluentd + Kibana(通常简称为EFK)是一个流行的日志管理和分析堆栈,它结合了Elasticsearch的强大搜索和分析能力、Fluentd的高效日志收集以及Kibana的数据可视化功能。
- Elasticsearch:
- 一个开源的搜索引擎,基于Lucene构建,用于存储、搜索和分析大量数据。
- 提供了强大的全文搜索能力,以及复杂的搜索和分析功能。
- 数据以JSON文档的形式存储,易于扩展和分布式部署。
- Fluentd:
- 一个开源的数据收集器,用于统一日志收集。
- 通过插件系统支持多种数据源和输出,可以轻松地收集和转发日志数据。
- 高效的数据处理能力,以及低资源消耗,使其成为日志收集的理想选择。
- Fluentd通常用作日志收集的“胶水”,因为它能够将来自不同来源的数据统一格式化并转发到各种后端系统。
- Kibana:
- 一个开源的数据可视化和仪表盘工具,与Elasticsearch紧密集成。
- 允许用户创建可视化的仪表盘,以直观地展示和分析存储在Elasticsearch中的数据。
- 提供了丰富的可视化选项,包括图表、地图、热图等。
工作流程
- 日志收集:Fluentd部署在应用程序服务器上,负责收集日志数据。它可以配置为监控特定的日志文件,或者直接从应用程序中捕获日志。
- 数据转发:收集到的日志数据被Fluentd处理并转发到Elasticsearch集群。在这个过程中,Fluentd可以根据需要转换和格式化数据。
- 数据存储和分析:Elasticsearch接收来自Fluentd的数据,并将其索引存储起来。这使得数据可以快速检索和分析。
- 数据可视化:Kibana连接到Elasticsearch集群,允许用户通过创建仪表盘和可视化来探索和分析数据。
示意图
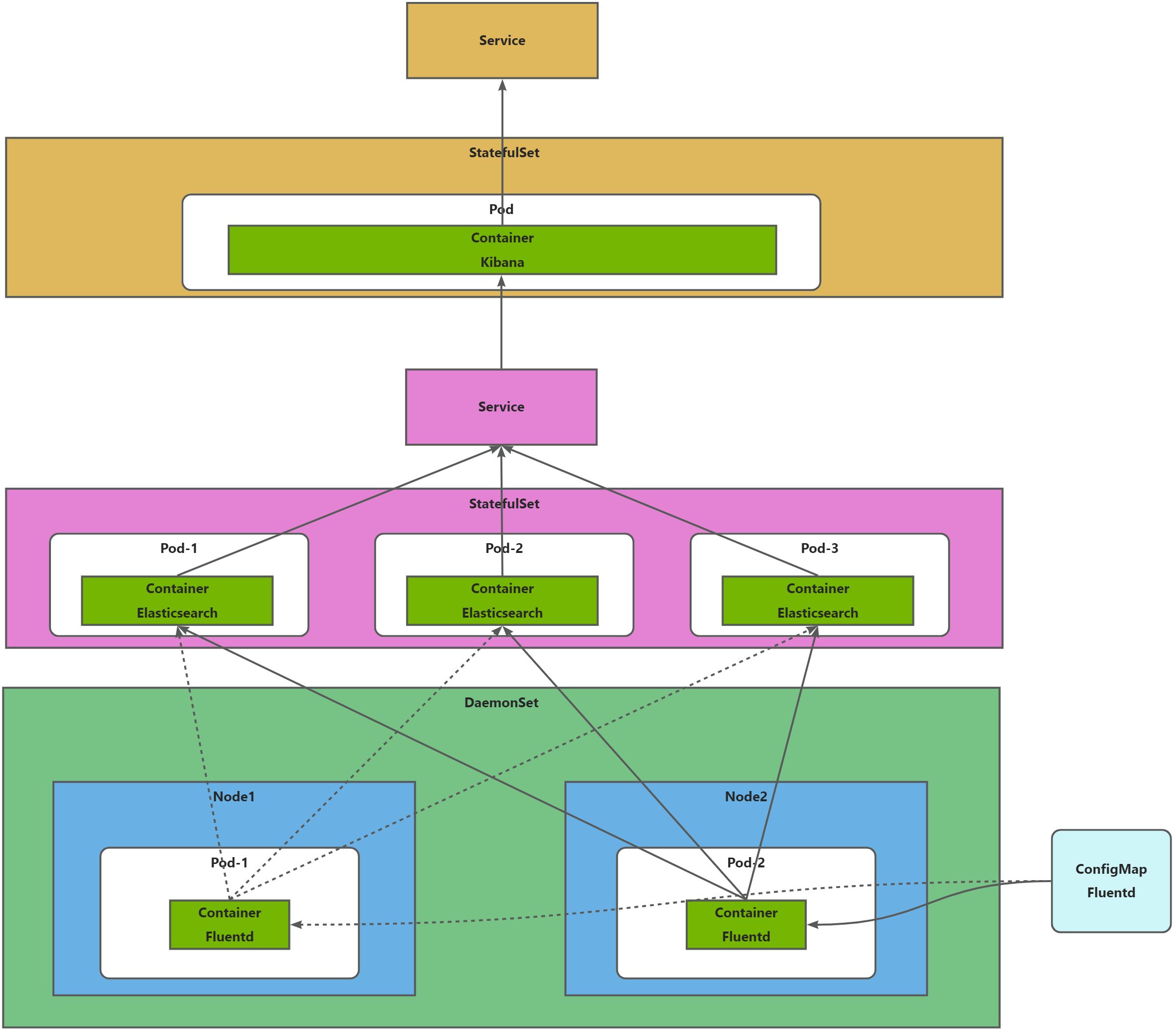
部署
创建EFK目录
mkdir -p /data/efk
下载yaml
yaml参考文件,需要酌情修改
- Elasticsearch
es-service.yaml
es-statefulset.yaml
- Kibana
kibana-service.yaml
kibana-deployment.yaml
- Fluentd
fluentd-es-configmap.yaml
fluentd-es-daemonset.yaml
调整yaml
- 一定要根据先前学习内容调整yaml配置,如:
- 根据需要调整NameSpace;
- 根据需要调整镜像地址;
- 根据需要调整存储方式;
- 根据需要调整Pod名称;
- 调整Kibana可以外网访问;
- 调整Kibana的SERVER_BASEPATH为注释;
部署EFK服务
cd /data/efk/
kubectl create -f es-service.yaml -f es-statefulset.yaml
kubectl create -f kibana-service.yaml -f kibana-deployment.yaml
kubectl create -f fluentd-es-configmap.yaml -f fluentd-es-daemonset.yaml
查看EFK服务
- 查看Estaticsearch
kubectl get pod -n efk-logs | grep estaticsearch
- 查看Kibana
kubectl get pod -n efk-logs | grep kibana
- 查看fluentd
kubectl get pod -n efk-logs | grep fluentd
EFK日志收集-Filebeat
简介
此处EFK指的是Elasticsearch+Filebeat+Kibana,主要用于收集容器日志。
组件介绍
Elasticsearch + Filebeat + Kibana(通常简称为EFK或EFKB)是另一个流行的日志管理和分析堆栈,它结合了Elasticsearch的搜索和分析能力、Filebeat的轻量级日志转发功能以及Kibana的数据可视化。
- Elasticsearch:
- 一个开源的搜索引擎,基于Lucene构建,用于存储、搜索和分析大量数据。
- 提供了强大的全文搜索能力,以及复杂的搜索和分析功能。
- 数据以JSON文档的形式存储,易于扩展和分布式部署。
- Filebeat:
- 一个轻量级的日志转发器,属于Elastic Stack中的Beats系列。
- 专为转发日志文件而设计,可以监控指定的日志文件或目录,并将日志事件发送到Elasticsearch或Logstash。
- 由于其轻量级特性,Filebeat对系统资源的占用很小,非常适合部署在生产和边缘服务器上。
- Filebeat具有模块化的设计,可以快速配置来收集特定应用程序的日志,如Apache、Nginx、MySQL等。
- Kibana:
- 一个开源的数据可视化和仪表盘工具,与Elasticsearch紧密集成。
- 允许用户创建可视化的仪表盘,以直观地展示和分析存储在Elasticsearch中的数据。
- 提供了丰富的可视化选项,包括图表、地图、热图等。
工作流程
- 日志收集:Filebeat部署在应用程序服务器上,负责收集日志文件中的数据。它可以配置为监控特定的日志文件或目录。
- 数据转发:Filebeat处理收集到的日志数据,并将其转发到Elasticsearch集群。在转发过程中,Filebeat会保留日志事件的元数据,如时间戳、标签和字段。
- 数据存储和分析:Elasticsearch接收来自Filebeat的数据,并将其索引存储起来,以便进行快速检索和分析。
- 数据可视化:Kibana连接到Elasticsearch集群,允许用户通过创建仪表盘和可视化来探索和分析数据。
示意图
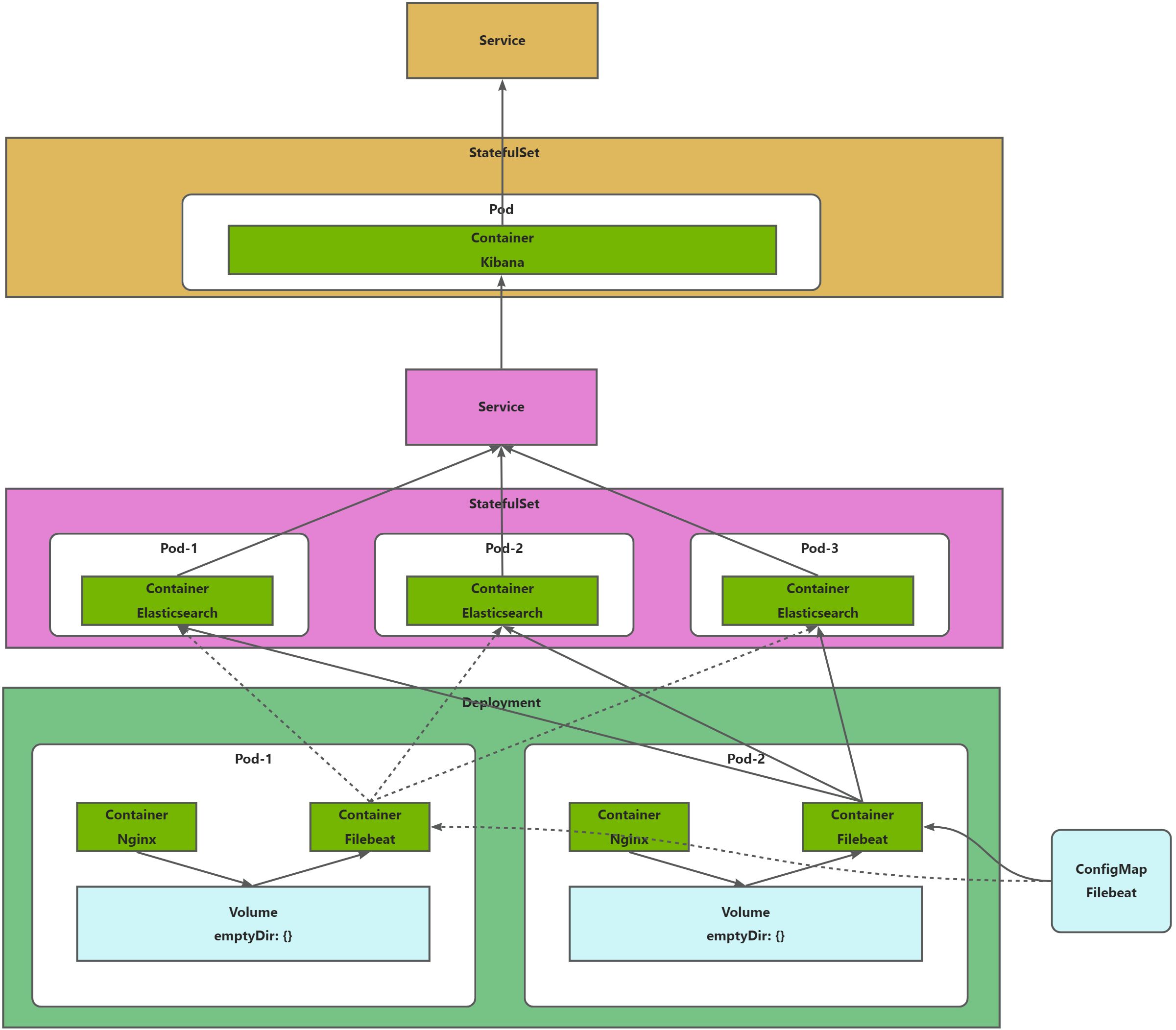
部署
创建EFK目录
mkdir -p /data/efk/
下载yaml
yaml参考文件,需要酌情修改
- Elasticsearch
es-service.yaml
es-statefulset.yaml
- Kibana
kibana-service.yaml
kibana-deployment.yaml
- Filebeat
filebeat-configmap.yaml
filebeat-app-deployment.yaml
调整yaml
- 一定要根据先前学习内容调整yaml配置,如:
- 根据需要调整NameSpace;
- 根据需要调整镜像地址;
- 根据需要调整存储方式;
- 根据需要调整Pod名称;
- 调整Kibana可以外网访问;
- 调整Kibana的SERVER_BASEPATH为注释;
部署EFK服务
cd /data/efk/
kubectl create -f es-service.yaml -f es-statefulset.yaml
kubectl create -f kibana-service.yaml -f kibana-deployment.yaml
kubectl create -f filebeat-configmap.yaml -f filebeat-app-deployment.yaml
查看EFK服务
- 查看Estaticsearch
kubectl get pod -n efk-logs | grep estaticsearch
- 查看Kibana
kubectl get pod -n efk-logs | grep kibana
- 查看fliebeat
kubectl get pod -n efk-logs | grep fliebeat


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









