







 本文详细介绍了词向量表示方法,从统计语言模型到神经网络语言模型(NNLM),重点探讨了基于Hierarchical Softmax和Negative Sampling的CBOW与Skip-Gram模型。讲解了这些模型如何解决词向量表示问题,以及它们在降低维度和捕获语义相似性方面的优势。
本文详细介绍了词向量表示方法,从统计语言模型到神经网络语言模型(NNLM),重点探讨了基于Hierarchical Softmax和Negative Sampling的CBOW与Skip-Gram模型。讲解了这些模型如何解决词向量表示问题,以及它们在降低维度和捕获语义相似性方面的优势。
首先计算机只认识01数字,要对文本进行处理就需要将单词进行向量化
单词的向量化表示方法
-
独热表示one-hot
最早对于单词向量化使用的是独热表示。每个单词对应一个向量,这个向量维度等于词汇表的大小,也就是说我有一个词汇表,里面有一万个单词,那么单词的独热表示向量维度就是一万维,对于词汇表中的每个具体的词,只需将其对应的位置置为1,其他位置置0。例子:我们有5个词组成的词汇表,词”Queen”在词汇表中的序号为2, 那么它的词向量就是(0,1,0,0,0)。同样的道理,词”Woman”是序号3,词向量就是(0,0,0,1,0)。
One hot representation用来表示词向量非常简单,但是却有很多问题。1、任意两个词之间都是孤立的,根本无法表示出在语义层面上词与词之间的相关信息,比如苹果、香蕉都是水果,他们之间肯定有相似性,one-hot却无法表达,而这一点是致命的。2、我们的词汇表一般都非常大,比如达到百万级别,这样每个词都用百万维的向量来表示简直是内存的灾难。能不能把词向量的维度变小呢?
-
词的分布式表示 distributed representation
Dristributed representation可以解决One hot representation的问题,它的思路是通过训练,将每个词都映射到一个低维向量上。所有的这些向量就构成了向量空间,进而可以用普通的统计学的方法来研究词与词之间的关系,向量维度一般需要我们在训练时自己来指定。
统计语言模型
如何计算一段文本序列在某种语言下出现的概率?之所为称其为一个基本问题,是因为它在很多NLP任务中都扮演着重要的角色。例如,在机器翻译的问题中,如果我们知道了目标语言中每句话的概率,就可以从候选集合中挑选出最合理的句子做为翻译结果返回。
统计语言模型给出了这一类问题的一个基本解决框架。对于一段文本序列,我们可以认为是一句话:
![]()
它的概率可以表示为:
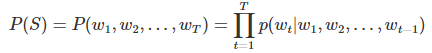
即将序列的联合概率转化为一系列条件概率的乘积,也就是我们认为第t个单词的出现是依赖前t-1个单词的,那么问题变成了如何去预测这些给定t-1个单词的条件下的预测第t个单词的概率:
![]()
如果我们将所有的文本序列都这样处理,那么它的参数空间将是巨大的,这样一个模型在实际中并没有什么用。我们采用其简化版本——Ngram模型:
![]()
我们认为第t个单词,只与其前n-1个单词相关,常见的如bigram模型(N=2)和trigram模型(N=3)。事实上,由于模型复杂度和预测精度的限制,我们很少会考虑N>3的模型。
我们可以用最大似然法去求解Ngram模型的参数——等价于去统计每个Ngram的条件词频。
词向量( word embedding),基于神经网络的分布表示
-
Neural Network Language Model 神经网络语言模型
2003年,Bengio等人提出NNLM模型,模型的基本思想可以概括如下:
- 假定词表中的每一个word都对应着一个连续的特征向量;
- 假定一个连续平滑的概率模型,输入一段词向量的序列,可以输出这段序列的联合概率;
- 同时学习词向量的权重和概率模型里的参数。
值得注意的一点是,这里的词向量也是要学习的参数。
假设训练集为w1,...,wT的单词序列,单词wt∈V,V是大量且有限的词汇集。目标是学习一个模型f,使得:
![]()
![]() ,模型的约束
,模型的约束 ![]()
模型采用了一个简单的前馈神经网络 【注意这里是f,不是p,f相当于整个网络结构,最终输出的是一个概率向量,对应的是词表中每个单词在给定的n-1个单词条件下的概率】 来拟合一个词序列的条件概率
。整个模型的网络结构见下图:
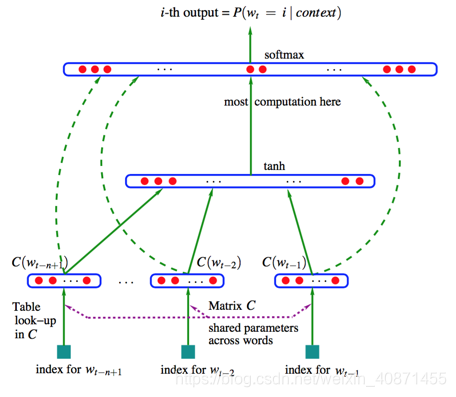
我们可以将整个模型拆分成两部分加以理解:
-
矩阵C∈
,即可以把V中任意一个词i映射为一个实值向量C(i)∈
,它表示的就是单词i的分布式特征向量(distributed feature vector)。在实践中,C被表示成一个|V|×m的矩阵,即矩阵的每一行C(i)代表一个词的词向量,每个向量的维度为m这些向量作为模型的输入
-
其次是一个简单的前馈神经网络g。它由一个tanh隐层和一个softmax输出层组成。通过一个函数g把输入的上下文单词的特征向量
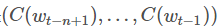 映射为下一个单词
映射为下一个单词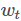 的条件概率分布函数,当然,这个单词在字典V中,g输出的的向量的第i个元素就是第i个单词的条件概率:
的条件概率分布函数,当然,这个单词在字典V中,g输出的的向量的第i个元素就是第i个单词的条件概率:
![]()
我们从图中可以看到,首先才词表矩阵C中查找每个单词对应的向量,然后进行拼接,形成一个(n−1)m维的列向量,经过隐含层tanh函数的激活,再经过softmax输出层的输出,这就得到了函数g的输出向量,需要注意的一点是:在输入层到输出层有直接相连的,这一层连接是可选的,也就是图中虚线的部分,下面讲述存在这一连接的情况:
目标函数的训练是最大化对数似然函数:
![]()
其中,θ为待训练参数,R(θ)为正则化项。而正则化项只约束于网络的权重和矩阵C,并不约束于偏置项
未经过softmax的归一化的输出的 向量为:
![]()
其中,![]() ,这个y就是一个|V|维的列向量
,这个y就是一个|V|维的列向量
然后softmax归一化:
我们是要训练参数,现在来看看参数集θ包含哪些参数项:
b (|V|维):隐层-输出层的bias
d (h维):输入-隐层的bias
U (|V|*h matrix):隐层-输出层的权重矩阵
H (h*(n-1)m matrix):输入-隐层的权重矩阵
C (|V|*m):词向量
则,θ:
通过SGD进行参数更新:
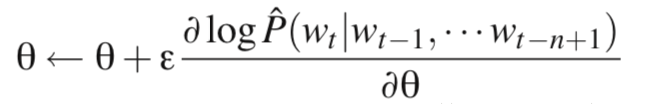
这就是完整的神经网络语言模型(NNLM)结构。
-
word2vec模型
Mikolov(2013)等人提出了一个新型的模型结构——word2vec模型,此模型的优点为能训练大量的语料,可以达到上亿的单词,并且可以使单词向量维度较低,在50-100之间。它能够捕捉单词之间的相似性,对单词使用代数运算就能计算相似的单词,例如:vector(“King”)-vector(“Man”)+vector(“Woman”)=vector(“Queen”)
word2vec模型结构
word2vec模型有两种方法来实现,一个是基于CBOW(continuous bag of word),另一个是基于skip-gram模型。这两种结构如下图:
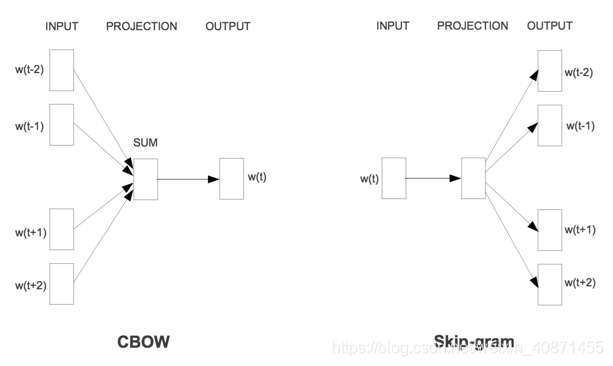
基于CBOW模型是根据目标单词的上下文经过映射来预测目标单词,而基于skip-gram模型刚好相反,使用目标单词经过映射层来预测上下文单词。 而这两个模型又可以使用两种方法实现,即使用hierachical softmax和negtive sampling来实现。
基于Hierarchical Softmax的模型
神经网络语言模型有三层,输入层(词向量),隐藏层和输出层(softmax层)。里面最大的问题在于从隐藏层到输出的softmax层的计算量很大,因为要计算所有词的softmax概率,再去找概率最大的值。
word2vec对这个模型做了改进,首先,对于从输入层到隐藏层的映射,没有采取神经网络的线性变换加激活函数的方法,而是采用简单的对所有输入词向量求和并取平均的方法。比如输入的是三个4维词向量:(1,2,3,4),(9,6,11,8),(5,10,7,12)那么我们word2vec映射后的词向量就是(5,6,7,8)。由于这里是从多个词向量变成了一个词向量。
第二个改进就是从隐藏层到输出的softmax层这里的计算量个改进。为了避免要计算所有词的softmax概率,word2vec采样了霍夫曼树来代替从隐藏层到输出softmax层的映射。关于霍夫曼树请参考博客:https://blog.youkuaiyun.com/itplus/article/details/37969979或者http://www.cnblogs.com/pinard/p/7160330.html,这里不再赘述
由于我们把之前所有都要计算的从输出softmax层的概率计算变成了一颗二叉霍夫曼树,那么我们的softmax概率计算只需要沿着树形结构进行就可以了。如下图所示,我们可以沿着霍夫曼树从根节点一直走到我们的叶子节点的词
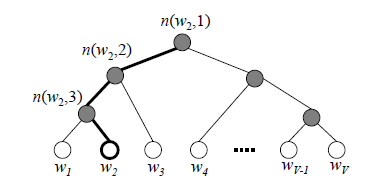
和之前的神经网络语言模型相比,我们的霍夫曼树的所有内部节点就类似之前神经网络隐藏层的神经元,其中,根节点的词向量对应我们的投影后的词向量,也就是我们上文提到的 向量,而所有叶子节点就类似于神经网络softmax输出层的神经元,叶子节点的个数就是词汇表的大小。在霍夫曼树中,隐藏层到输出层的softmax映射不是一下子完成的,而是沿着霍夫曼树一步步完成的,因此这种softmax取名为"Hierarchical Softmax"。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 701
701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









