







 TextRank算法基于图论,将文本中的语法单元作为节点,通过共现关系建立边,通过迭代计算节点权重,权重高的节点被视为关键词。算法包括预处理、设置过滤器、迭代计算、关键词排序和后处理步骤。应用于关键词抽取时,构建无向有权图,通过迭代求得每个词的权重,输出最高权重的词汇作为关键词。
TextRank算法基于图论,将文本中的语法单元作为节点,通过共现关系建立边,通过迭代计算节点权重,权重高的节点被视为关键词。算法包括预处理、设置过滤器、迭代计算、关键词排序和后处理步骤。应用于关键词抽取时,构建无向有权图,通过迭代求得每个词的权重,输出最高权重的词汇作为关键词。
参考论文:Rada Mihalcea《TextRank:Bring Order into texts》。
TextRank将文本中的语法单元视作图中的节点,如果两个语法单元存在一定语法关系(例如共现),则这两个语法单元在图中就会有一条边相互连接,通过一定的迭代次数,最终不同的节点会有不同的权重,权重高的语法单元可以作为关键词。
节点的权重不仅依赖于它的入度结点,还依赖于这些入度结点的权重,入度结点越多,入度结点的权重越大,说明这个结点的权重越高;任两点 Vi , Vj 之间边的权重为 wji , 对于一个给定的点 Vi, in(Vi) 为 指 向 该 点 的 点 集 合 , Out(Vi) 为点 Vi 指向的点集合。
TextRank迭代计算公式为:
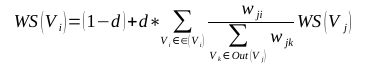
其中, d 为阻尼系数, 取值范围为 0 到 1, 代表从某一特定点指向其他任意点的概率, 一般取值为 0.85。使用TextRank 算法计算各点的得分时, 需要给图中的点指定任意的初值, 并递归计算直到收敛, 即任意一点的误差率小于给定的极限值时就可以达到收敛, 一般该极限值取 0.0001。算法通用流程:
TextRank用于"关键词抽取":
1.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 447
447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









