







元组
元组的声明方法,元组与列表的比较,
元组的遍历,元组的切片,元组的基本方法
1、元组的声明
tupleA = (1,2,3,‘string’,True,3.14)
listA = [1,2,3,‘string’,True,3.14]
元组的特点:
不支持修改(元组是固定的);
元组所占用的内存空间比列表小
注意:元组是静态的,列表是动态的
print(tupleA +(1,2,3))——相当于创建了一个新的元组,本来的元祖不会改变
print(tupleA) ——与上边对比一下,打印结果是不一样的
换一下形式
tupleB = tupleA +(1,2,3)
print(tupleB) ——
tupleA = tupleA + (1,2,3)
print(tupleA)
tupleA叫做变量的名字:代表的是一段内存空间;
tupleA = tupleA+(1,2,3)时,在赋值符号的右边的tupleA是去调用内存中所存在的元组,
赋值符号的左边tupleA是指向了,由(1,2,3,‘string’,True,3.14)与(1,2,3)所占空间进行了合并的操作,
并不是对元组本身进行了修改或增加,是内存与内存之间的合并,产生新的地址。
查看所占内存空间大小的魔术方法:sizeof()
每次将tupleA、listA增加2个整型
print(tupleA.__sizeof__())
print(listA.__sizeof__())
结果变化:
72 -88 -> +16(88) - +16(104) -> +16(104) - +16(120)
根据结果,得出结论:
列表比元组多16位的存储空间,用来增加或减少元素
2、元组的遍历
第一种:利用索引
for index in range(len(tupleA)):
print(tupleA[index])
第二种:直接打印变量
for element intupleA:
print(element)
3、元组的切片
print(tupleA[0:3]) ——0,3表示索引
注意:
字符串切出来的是字符串;
列表。。。。。。列表
元组。。。。。。元组
print(tupleA[::-1])——可以倒过来打印结果
同一类的错误
print(‘ ’.join(tupleA[::-1])) ——报错
print(‘ ’.join(listA[::-1])) ——报错:数据类型不同,不只有字符串;不同数据类型之间不能加
print(‘str001’ + 1)——报错
-1 表示步长
4、元组的基本方法
n = tupleA.index(‘string’,0,len(tupleA)-1)
#0为起始索引
print(n)
m = tupleA.count(1) #统计1的个数,1包括true
print(m)
注意;元组主要用来声明固定的数据类型,因为节省内存空间
用途
isinstance(variable,(str,int))
if type(variable) in (str,int,float):
5、字典
优先级:()->[]->{}
字典声明方式:
key:value(最小的元素是:键值对)
第一种方式
sidamingji = {‘桃花源记’:‘陶渊明’,‘岳阳楼记’:‘范仲淹’,‘西游记’:‘吴承恩’}
print(sidamingji)
print(sidamingji,type(sidamingji))——‘dict’的格式
第二种方式
ips = dict([(‘192.168.161.100’,20),(‘1.1.1.1’,32),(‘2.2.2.2’,35),(‘3.3.3.3’,89)])——[]里是多个元组
print(ips) ——用dict函数将list列表转为字典
现在把2.2.2.2 改为1.1.1.1
这时候只会输出3个,因为键是惟一的
注意:键是惟一的,具有唯一性。
如何让一个键有多个值?
例如:(‘192.168.161.100’,[20,23,24,34])
注意:
元组可以作字典的键(因为元组的不可变性)
列表不可以作键(因为列表具有可变性)
字典的遍历
三种方式:
遍历键
第一种
for keys in ips.keys():
print(keys)
第二种
for keys in ips:
print(keys)
遍历值
第一种
for keys in ips:
print(ips[keys]) 利用键,相当于索引
第二种
for values in ips.values():字典自带的方法
print(values)
遍历键值对
for items in ips.items(): ——把字典转化为了列表
print(items) ——实质上就是遍历列表,
ips.items()相当于把字典转化为了列表
字典的长度
可以根据逗号+1来看长度
print(len(ips))
字典中的key就是list中的索引,但是字典中的key具备可自定义性
ips01 = {0:1,1:2,2:3,3:4,4:5}
listB = [1,2,3,4,5]
print(ips01(0)) ——0表示的是键
注意:字典是可迭代对象,但是只有键可以被迭代
ips = {‘1.1.1.1’:23,‘2.2.2.2’:23,‘3.3.3.3’,32}
字典中增加键值对的操作:
方式一:
ips[‘4.4.4.4’] = 45 ——适用于对值的修改,因为可以实现自加
print(ips)
方式二:
ips.setdefault(‘5.5.5.5’,89)——适用于设置初始值,因为不可以自加
print(ips)
字典中删除键值
方式一:
ips.pop(‘1.1.1.1’)——尽量使用这个,好控制
print(ips)
方式二:
ips.popitem() ——从后往前删
print(ips)
字典的更改 -》更改健值对中的值
方式一:
ips[‘2.2.2.2’] = 2323
print(ips)
方式二:
for i in range(1,101):
ips[‘3.3.3.3’] += i ——最后加了5050
print(ips)
方式三
ips.update([(‘2.2.2.2’,23.45)])——添加一个可迭代对象
print(ips)
ips.update([(‘2.2.2.2’,23.45),(‘3.3.3.3’,56)])——修改多个
print(ips)
字典的查找
print(ips[‘2.2.2.2’]) ——根据键
print(ips.get(‘2.2.2.2’))
快速生成字典
ips01 = {}
ips01.fromkeys([x for x in range(100)])——快速生成字典,设置为键,但值为空
print(ips01.fromkeys([x for x in range(100)]))
思考题;
{‘1.1.1.1’:12,‘2.2.2.2’:5,‘3.3.3.3’:78,‘4.4.4.4’,34}
按照字典中每个键值对的值进行排序;要求从大到小;
ips = {'1.1.1.1':12,'2.2.2.2':5,'3.3.3.3':78,'4.4.4.4':34}
ips_list = []
for items in ips.items():
ips_list.append(items)
# print(ips_list)
for i in range(len(ips_list)):
for j in range(len(ips_list) - 1):
if ips_list[j][1] < ips_list[j+1][1]:
ips_list[j], ips_list[j+1] = ips_list[j+1], ips_list[j]
# print(ips_list)
print(dict(ips_list))
6、集合
集合的声明方式
setA = {1,2,3,4,1,2,3,4}
listA = {1,2,3,4,1,2,3,4}
print(setA)
print(listA)
print(setA[0]) ——报错,集合对象不支持索引
print(listA[0])
注意:
集合可以去重
集合不支持索引
对集合进行遍历
for element in setA:
print(element) ——集合是可迭代对象;不支持索引,只能对他本身进行遍历
集合的交集、并集
setA = {1,2,3,4}
setB = {3,4,5,6}
print(setA & setB) ——求交集
print(setA | setB) ——求并集
print(setA + setB) ——不支持加法
print(setA * 2) ——不支持乘法,因为集合具有不可变性
集合中常见的基本方法
setA.pop()
print(setA) ——从前开始删
setA.remove(3)
print(setA) ——精准删除
setA.add(1234) ——添加
print(setA)
注意:
集合具有无序性,因此当add多个元素时,添加的位置不知道
成员关系的判断
listA = [1,2,3.14,‘string’,True]
for element in listA:
if type(element) in {int,float}:
print(element)
7、读取文件以及写入文件的两种方式
读取文件内容,mode=‘r’
file = open(file = ‘/etc/passwd’,mode = ‘r’)
解释:
file= ‘/etc/passwd 表示路径
mode 表示模式,w表示写入,r表示读取
注意:
python里句柄泄露相当于linux里的发现交换文件(后缀.swp)
print(file.read()) ——输出整篇文章,全文输出
print(file.readline())——输出一行,如果输出10行,写10行这条命令
注意:生成器,每次调用都会打印出一行
print(file.readlines()) ——输出为列表,在列表中,每一行(\n结尾)都是元素
注意:输出一个把每一行作为元素的列表
关闭文件
file.close() ——相当于linux里的:wq
————————————————————————————————
写入内容到文件时,mode=‘w’ ,覆盖
files = open(file = ‘./fileIO.txt’,mode = ‘w’)
files.write(‘# file IO Opera’)——输入一行
files.write( ——输入多行
“”“
注意:
集合可以去重
集合不支持索引
”“”
)
注意:write覆盖
files.writelines(‘abcdefghijklmn’) ——常用的两种方法
files.writelines([‘abc\n’,‘bac\n’,‘jlk\n’])
注意;writelines 覆盖
注意: w 模式下都是覆盖
files.writable() ——会返回相应的bool值,用来判断文件的写入权限
查看用法:选中,Ctrl+b
files.close()
————————————————————————————————-——
追加内容到文件时,mode=‘a’
file = open(file = ‘./fileIO.txt’,mode = ‘a’)—— 模式a起追加作用
file.write( ——输入多行
“”“
注意:
集合可以去重
集合不支持索引
”“”
)
file.close()
8、联系文件上下文来打开文件,并对文件进行相应的操作
with open(file=‘./with_file.txt’,mode=‘a’) as filesss: ——as别名
pass
9、awk
在shell里
awk ‘{ ips[$1]++ }END{ for(ip in ips){ print ip, ips[ip] } }’ access_log | sort -k2 -rn |
图片文件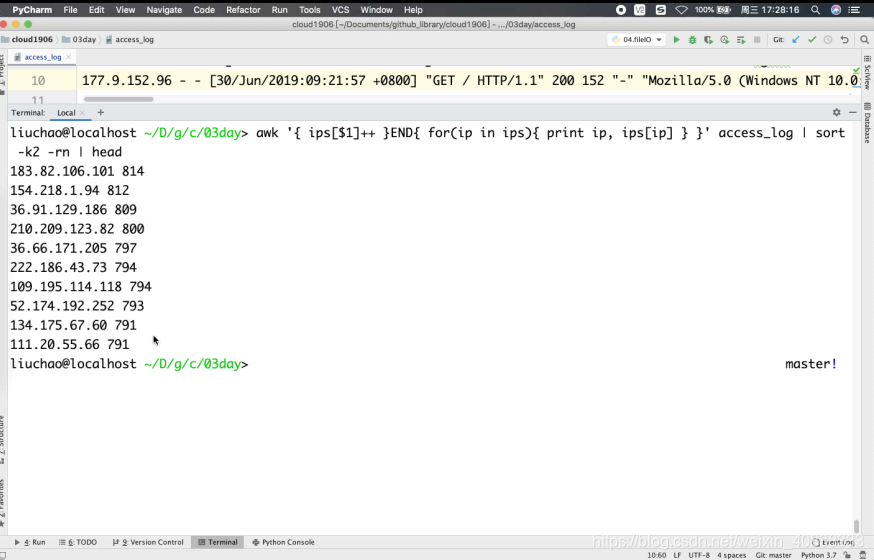
日志分析
ips = {}
with open(file=‘access_log’,mode=‘r’) as log:
for lines in log.readlines():
#lines.split()[0]
if not lines.split()[0] in ips.keys():
ips.setdefault(lines.split()[0],1)
else:
ips[lines.split()[0]] += 1
print(ips)
ips_list = []
for items in ips.items():
ips_list.append(items)
# print(ips_list)
for i in range(len(ips_list)):
for j in range(len(ips_list) - 1):
if ips_list[j][1] < ips_list[j+1][1]:
ips_list[j], ips_list[j+1] = ips_list[j+1], ips_list[j]
# print(ips_list)
print(dict(ips_list))
最后结果如下图:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









