






查找场景
设想一种场景,一种是需要在1亿行数据中查到相同的行。这么大的数据如果读入内存中进行计算,那么对机器的要求非常高非常耗费成本;其次,也有单点故障的风险。如果考虑用100台机器进行计算,可以采用下面的算法:
1)计算每行数据的哈希值,并用hash值为文件名创建文件;如果文件已经存在,则将改行数据追加到文件中
2)相同的行一定在同一个文件中,在同一个较小的文件中查找相同的行
因此1一亿数据查找的问题,转换为了再多个小文件中各自查找相同的行的问题。
组内无序,组间有序;2)组内有序,组间无序;
组内无序,组间有序
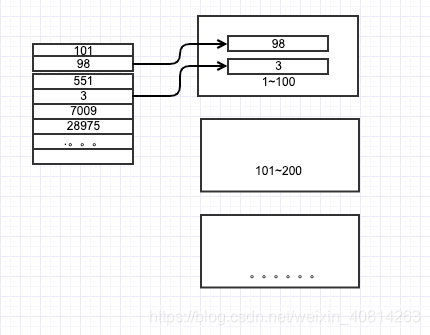
- 根据文件的大小,按梯度创建文件,比如1-100;201-200。。。然后将数据放到各自的所属的文件中;
2)因此外部文件级别已经有序了,需要对文件内部的数据进行排序即可
组内有序,组间无序
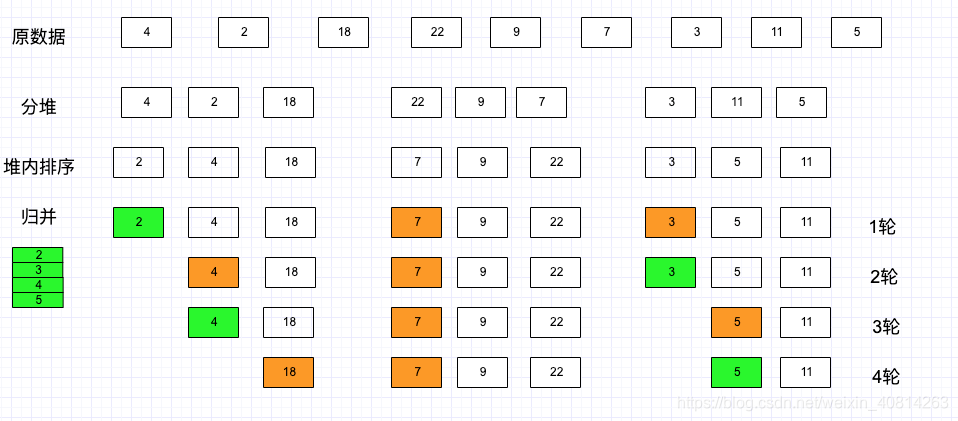
1)将数据划分为100堆,在每个堆的内部进行排序
2)堆内有序,堆外无序,再对这100堆采用归并排序算法
下面是先分堆再归并排序的示意图:
集群
采用单机的方式计算,都需要将大数据划分成小数据再计算,这样的话由于单机的算力有限,并且数据增长后算力也跟不上等问题,将这种问题化为集群的方式解决。比如有1T的数据,划分为2000个500M的数据,分发到2000个服务器上进行计算。有样计算:
优点:
1)每个服务器算500M的数据,可以并发2000个服务器计算,将几小时的任务在秒级完成
2)数据增加后,每个服务器可能增加以M为单位的数据,影响不大
问题:
需要考虑1T的数据切割并分发到2000个服务器的传输时间,可能会消耗几个小时。但是当数据量增加的时候只需要增量的下发数据即可。
集群的的关键点:
1)并行计算提高速度
2)分布式运行
3)计算与数据在一起
4)存+算:计算向数据移动(数据的移动耗时)
5)数据的规划管理,如何查找分发下去的数据,需要一个管理者来规划管理数据
Hadoop
存储模型
Hadoop 中一个文件必须以相同的大小划分成块(block),不同的文件每块的大小可以不同。默认情况下一个块的大小为128M,最小是1M,一个块的内容可以冗余到多个节点上,默认情况是3个节点。块大小和副本数可以自定义设置。块只支持一次写入多次读取,不能更改,但是可以在末尾追加数据。否则一个块的大小的变化会引起连锁反应所有的块都要变化。
架构模型
采用主从架构模型,即主节点和从节点。
主节点(NameNode):管理文件的 metadata( 元数据),切分的块的信息,eg,block 大小,块的地址,偏移量。
从节点(DateNode):负责存储在自己节点的要操作的文件数据,以及这些文件数据的计算。
Hadoop 1.0版本是一主多从,但是主一旦挂了,从也就没法访问了。DataNode主动向NameNode汇报自己的块信息,保持心跳。当客户端要写如数据的收,客户端访问NameNode,NameNode 将文件分块,并写入DataNode。 当客户端读取数据时,NameNode或返回客户端最近的数据地址,客户端自行访问DataNode,无需事事都通过NameNode来完成。DataNode采用服务器本地文件系统存储数据块。
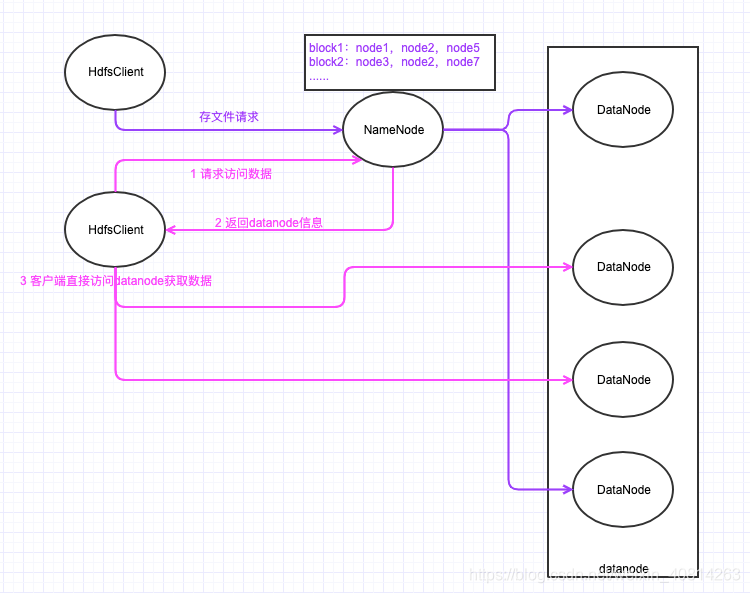
因为Hadoop 1.0单一主节点的问题,引入了 Secondary NameNode。 但是Hadoop 2.0后就没用Secondary NameNode了。
NameNode 持久化
NameNode 的元数据都不与磁盘发生交互,都在内存中处理为了追求速度快。由于内存数据有掉电丢失的问题,所有内存数据库都需要做持久化。定时持久化与关系型数据库读取磁盘不同,持久化只是单向的将内存数据刷入磁盘,而关系型数据库则是当内存满了会将数据写入磁盘,再将磁盘数据读入内存,送到输出流返回客户端,是内存与磁盘的双向操作。持久化只有在故障或者重启服务停机后,才需要读取磁盘持久化的数据。
NameNode的主要功能有:
- 接收客户端的读写服务
- 收集DataNode汇报的Block列表信息。
NameNode保存的metadata信息包括:
- 文件的ownership和permission
- 文件的大小、时间
- Block列表,Block偏移量,位置信息(不会持久化,由DataNode上报)
如果持久化的话,一个DataNode给的位置信息持久化了,但是DataNode又挂了,会导致得到的块信息不准。
NameNode 持久化
- NameNode的metadata信息会在启动后加载到内存中
- NameNode存储到磁盘文件名称为“fsimage”(时点备份)
- Block信息不回存在fsimage
- edits记录对metadata的操作日志
fsimage:磁盘快照,当时的内存数据写入磁盘(序列化与反序列化操作)。序列化比较慢,但是反序列化写入内存比较快。
edits:将服务器的指令操作都写到log中,也是持久化操作,写的时候比较快,但是恢复的时候,会一条一条执行日志命令,会比较慢。
fsimage写入慢读入快;edits写入快读入满,综合使用两种方案,在Hadoop集群搭建完成之前,还未启动的时候会产生第一个fsimage文件,但是该fsimage为一个空文件,还没有客户端的输入。集群一旦启动起来会去读fsimage空文件,同时读空的edits文件。之后客户端的任何操作都写edits文件,它会一直膨胀。当达到了一定的时点或者触发一定条件后,fsimage与edits会合并成为新的文件。一直重复该过程。该合并工作由Secondary NameNode,它并不是第二个主节点,而是主要完成合并工作。
当edits触发checkpoint后,edits和原来的fsimage一起交给Secondary NameNode进行合并成新的fsimage。原来的edits同时清空继续记录新的指令。当Secondary NameNode合并完成后,将新的fsimage返还给Primary NameNode,Primary NameNode 持有了新的fsimage和一个清空了的edits继续接收命令,如此反复执行等待下一次合并。
当重新启动服务器时,先读大的fsimage,发序列化到内存中,再读一小块edits数据。
Secondary NameNode触发合并的时机:
- 定时合并:fs.checkpoint.period,默认3600秒,
- 定量合并:fs.checkpoint.size,规定edits文件最大值,默认64M
1.0版本中 Secondary NameNode 不能作为Primary NameNode的备份节点,它只是做合并的操作。
DataNode
- 本地磁盘目录存储数据(Block),文件格式
- 存储Block的元数据信息,MD5。
下载Block数据校验MD5验证数据完整性。 - 启动DataNode时向NameNode汇报block信息
- 通过向NameNode发送心跳保持与其联系(3秒一次),如果NN 10分钟没有收到DN的心跳,则认为其已经lost,并copy其上的block到其他DN
副本存储
一个block存放3个副本时,这三个副本的存放策略为:
1)第一个副本就近存储,如果上传的服务器刚好是一个datanode,则就存在该服务器上;
2) 第二个副本存放在与第一个副本不同机架的一个服务器上;
3)第三个副本存放在与第二个副本机架相同的不同服务器上。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









