




 文章探讨了ShardingSphere在高并发场景下的IN查询性能问题,发现其执行时进行了全表扫描。通过分析源码,作者提出了并行单条查询和使用ForkJoinPool进行优化的方法,有效减少了数据库CPU的占用。优化后,即使在50并发情况下,数据库仍能处理每秒2.3万次请求,CPU占用降至40%。
文章探讨了ShardingSphere在高并发场景下的IN查询性能问题,发现其执行时进行了全表扫描。通过分析源码,作者提出了并行单条查询和使用ForkJoinPool进行优化的方法,有效减少了数据库CPU的占用。优化后,即使在50并发情况下,数据库仍能处理每秒2.3万次请求,CPU占用降至40%。
背景
上游系统进行并发压测批量查询接口,每次按照50个ID进行IN查询用户信息(10个库20张表),在并发量并不大的情况导致数据库CPU达到100%并且重启。
ShardingSphere的版本为4.0.0
分析ShardingSphere的IN查询
- 通过下面测试发现shardingsphere的IN查询存在性能损耗
1.1 期望现象:最多两次查询并且指定条件List<Long> oneIdList = new ArrayList<>(); oneIdList.add(3305095L); oneIdList.add(8867290L); List<User> userList = userMapper.selectBatchIds(oneIdList);
1.2 实际现象:四次全条件查询Actual SQL: ds0 ::: SELECT one_id,channel_id,channel_user_id,scene_code,channel_user_nick_name,master_one_id,member_channel_id,member_no,union_id,disabled_type,birth_day,dept_id,enrollment_time,channel_user_information,version,create_time,update_time FROM t_user_info_10 WHERE one_id IN ( ? , ? ) ::: [3305095, 8867290] Actual SQL: ds0 ::: SELECT one_id,channel_id,channel_user_id,scene_code,channel_user_nick_name,master_one_id,member_channel_id,member_no,union_id,disabled_type,birth_day,dept_id,enrollment_time,channel_user_information,version,create_time,update_time FROM t_user_info_15 WHERE one_id IN ( ? , ? ) ::: [3305095, 8867290] Actual SQL: ds2 ::: SELECT one_id,channel_id,channel_user_id,scene_code,channel_user_nick_name,master_one_id,member_channel_id,member_no,union_id,disabled_type,birth_day,dept_id,enrollment_time,channel_user_information,version,create_time,update_time FROM t_user_info_10 WHERE one_id IN ( ? , ? ) ::: [3305095, 8867290] Actual SQL: ds2 ::: SELECT one_id,channel_id,channel_user_id,scene_code,channel_user_nick_name,master_one_id,member_channel_id,member_no,union_id,disabled_type,birth_day,dept_id,enrollment_time,channel_user_information,version,create_time,update_time FROM t_user_info_15 WHERE one_id IN ( ? , ? ) ::: [3305095, 8867290] - 源码浅析IN查询
2.1 执行器ShardingPreparedStatement执行的SQL的流程
2.2 SQL路由:StandardRoutingEngine#route0public boolean execute() throws SQLException { try { clearPrevious(); // 将sql进行路由:StandardRoutingEngine#route0 shard(); initPreparedStatementExecutor(); // 执行SQL return preparedStatementExecutor.execute(); } finally { clearBatch(); } }
2.3 默认按照分库并行执行路由SQL:ShardingExecuteEngineprivate Collection<DataNode> route0(final TableRule tableRule, final List<RouteValue> databaseShardingValues, final List<RouteValue> tableShardingValues) { // 根据分片键获取分库:2个 Collection<String> routedDataSources = routeDataSources(tableRule, databaseShardingValues); Collection<DataNode> result = new LinkedList<>(); // 遍历分库,根据分片键获取分表。所以总共有4条路由:2x2 for (String each : routedDataSources) { result.addAll(routeTables(tableRule, each, tableShardingValues)); } return result; }private <I, O> List<O> parallelExecute(final Collection<ShardingExecuteGroup<I>> inputGroups, final ShardingGroupExecuteCallback<I, O> firstCallback, final ShardingGroupExecuteCallback<I, O> callback) throws SQLException { Iterator<ShardingExecuteGroup<I>> inputGroupsIterator = inputGroups.iterator(); ShardingExecuteGroup<I> firstInputs = inputGroupsIterator.next(); // 除去第一个其余的分库通过线程池异步执行,遍历分表进行循环查询:SQLExecuteCallback#execute0 Collection<ListenableFuture<Collection<O>>> restResultFutures = asyncGroupExecute(Lists.newArrayList(inputGroupsIterator), callback); // 第一个分库用主线程查询 return getGroupResults(syncGroupExecute(firstInputs, null == firstCallback ? callback : firstCallback), restResultFutures); }
并行流进行优化处理
- 通过并行单条查询减少不必要分表查询和条件查询
- 并行流优化demo代码
List<Long> oneIdList = new ArrayList<>(); oneIdList.add(3305095L); oneIdList.add(8867290L); // 注意list指定大小,防止出现数组越界的问题 List<User> userList = new ArrayList<>(oneIdList.size()); oneIdList.parallelStream().forEach(oneId->{ User user = userMapper.selectById(oneId); userList.add(user); }); - ForkJoinPool将一个大的任务,通过fork方法不断拆解,直到能够计算为止,之后,再将这些结果用join合并(通过ForkJoinTask#fork断点可以验证)
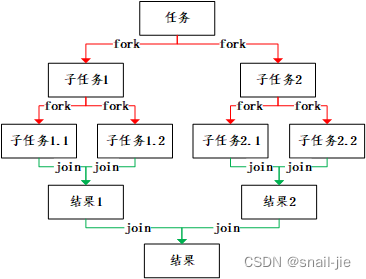
总结
- 通过5个并发用户进行线上压测(效果见下图),优化后对数据库CPU的损耗减少
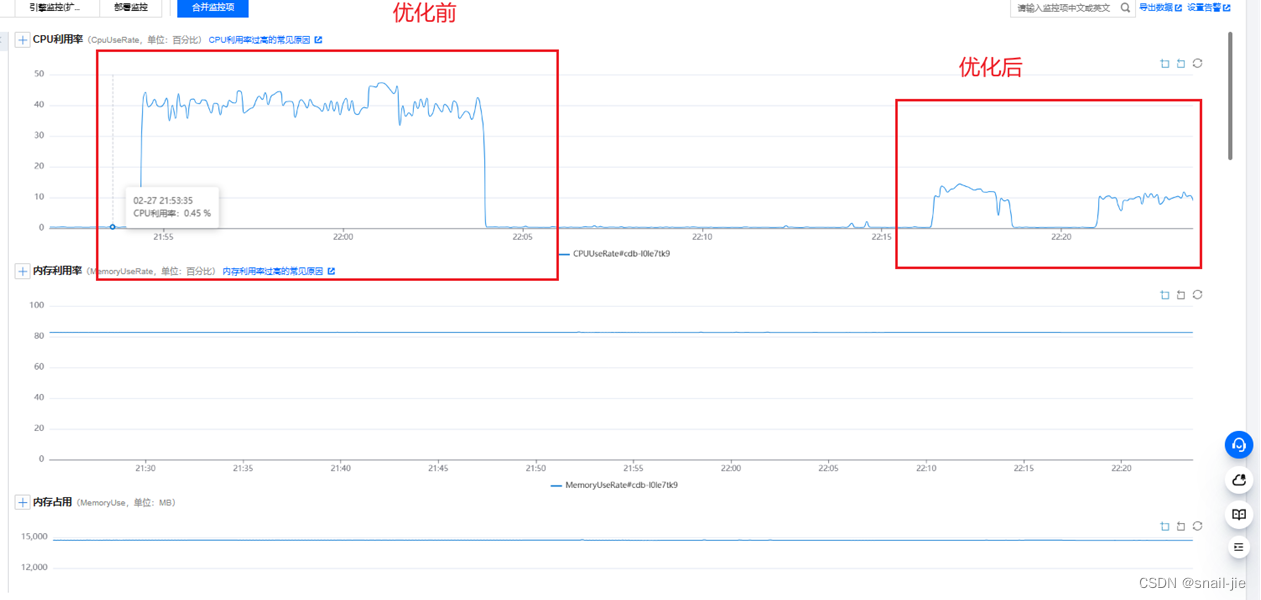
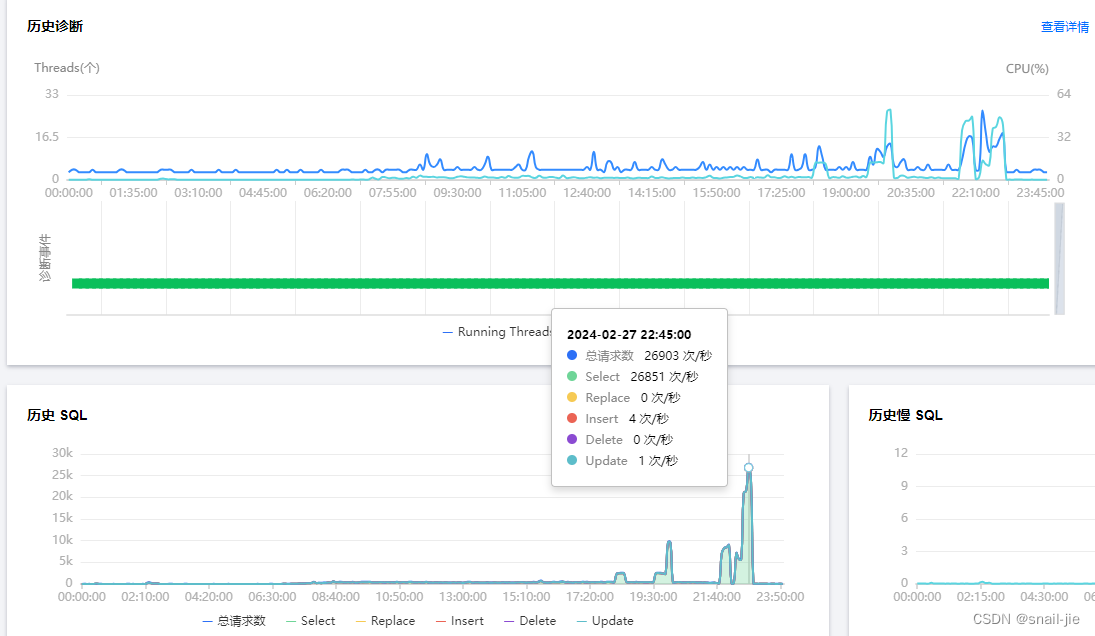
- 后来50个并发进行压测,数据库的达到每秒2.3w次请求,CPU也才40%


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









