







 本文介绍了使用Python爬虫抓取知乎问题下所有回答的实战过程,包括分析请求参数、解析JSON数据以及处理HTML内容。抓取的数据包括回答的作者、粉丝数、内容、时间、评论数、赞同数和链接。爬虫的意义在于数据的横向对比和潜在的词频分析。
本文介绍了使用Python爬虫抓取知乎问题下所有回答的实战过程,包括分析请求参数、解析JSON数据以及处理HTML内容。抓取的数据包括回答的作者、粉丝数、内容、时间、评论数、赞同数和链接。爬虫的意义在于数据的横向对比和潜在的词频分析。
好久不见,工作有点忙...虽然每天都是在写爬虫,也解锁了很多爬虫实战新技能,但由于工作里是用 NodeJS,已经好久没动手写 Python 了。
对于解决需求问题来说,无论 Python 还是 NodeJS 也只不过是语法和模块不同,分析思路和解决方案是基本一致的。
最近写了个简单的知乎回答的爬虫,感兴趣的话一起来看看吧。

需求

抓取知乎问题下所有回答,包括其作者、作者粉丝数、回答内容、时间、回答的评论数、回答赞同数以及该回答的链接。
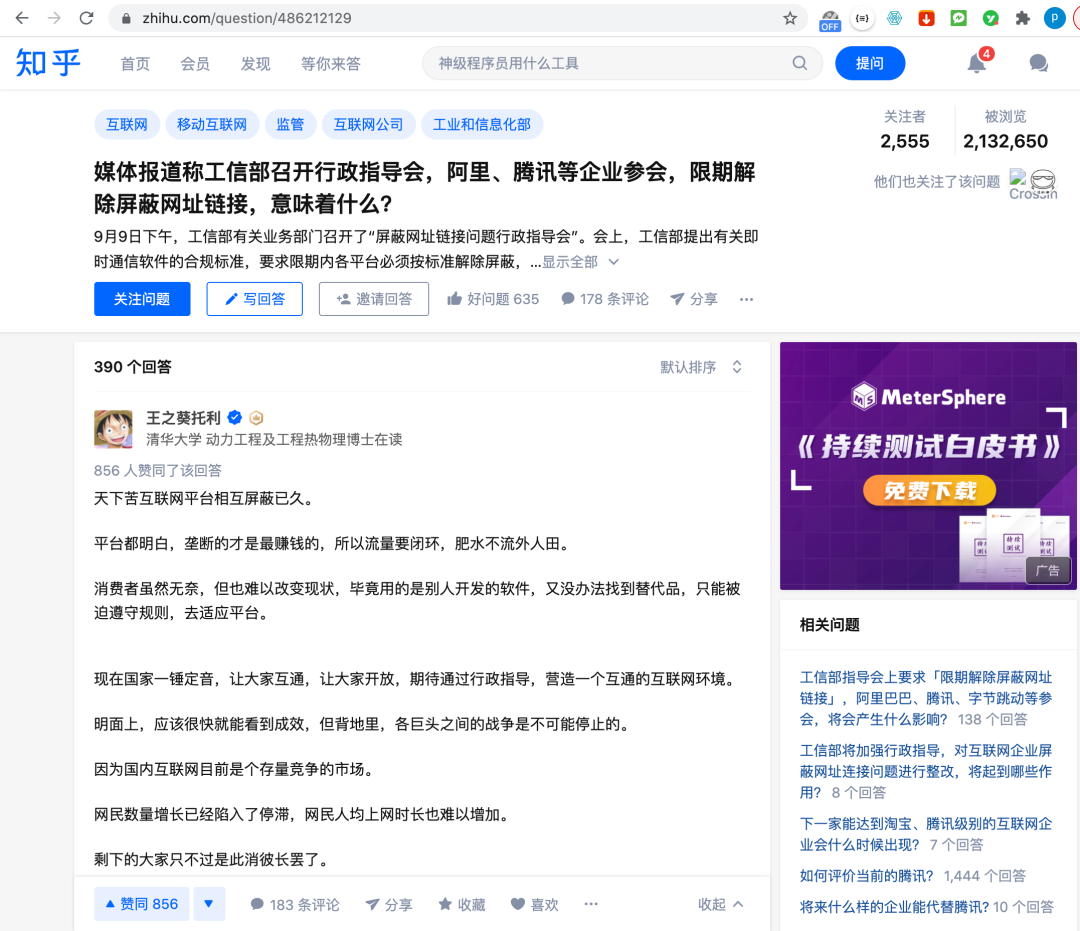


分析

以上图中问题为例,想要拿到回答的相关数据,一般我们可以在 Chrome 浏览器下按 F12 来分析请求;但借助Charles抓包工具可以
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1194
1194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









