 Ubuntu18.04部署Hadoop集群
Ubuntu18.04部署Hadoop集群








 本文详细介绍在Ubuntu18.04环境下搭建Hadoop集群的过程,包括Hadoop的安装、环境变量配置、各类配置文件的设置,如hadoop-env.sh、yarn-env.sh、core-site.xml等,以及格式化namenode和启动集群的方法。
本文详细介绍在Ubuntu18.04环境下搭建Hadoop集群的过程,包括Hadoop的安装、环境变量配置、各类配置文件的设置,如hadoop-env.sh、yarn-env.sh、core-site.xml等,以及格式化namenode和启动集群的方法。
Ubuntu18.04 部署Hadoop集群
1. Hadoop集群部署
下载地址:https://hadoop.apache.org/releases.html
集群配置
| master | 192.168.0.130 | namenode | resourcemanager |
| slave1 | 192.168.0.131 | datanode | nodemanager |
| slave2 | 192.168.0.132 | datanode | nodemanager |
1.1 安装Hadoop
解压 hadoop-3.1.2.tar.gz到 /opt 目录
sudo tar -zxvf hadoop-3.1.2.tar.gz /opt
sudo mv /opt/hadoop-3.1.2 /opt/hadoop
修改环境变量
sudo gedit /etc/profile
export HADOOP_HOME=/opt/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
刷新环境变量
source /etc/profile
1.2 配置Hadoop
1.2.1 配置 hadoop-env.sh
/opt/hadoop/etc/hadoop
添加JAVA_HOME
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
1.2.2 配置 yarn-env.sh
添加JAVA_HOME
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
1.2.3 配置 core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 指定hadoop临时目录,自行创建 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
<description>Allow the superuser oozie to impersonate any members of the group group1 and group2</description>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>master,slave1,slave2</value>
<description>The superuser can connect only from host1 and host2 to impersonate a user</description>
</property>
</configuration>
1.2.4 配置 hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/data/hadoop/hdfs/data</value>
</property>
</configuration>
1.2.5 配置 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:19888</value>
</property>
</configuration>
1.2.6 配置yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
1.2.7 配置worker
slave1
slave2
1.2.8 将上述所有文件复制一份到各节点
1.2.9 格式化namenode(初始化)
cd /opt/hadoop/bin/
./hdfs namenode -format
1.2.10 启动Hadoop集群
cd /opt/hadoop/sbin/
./ start-dfs.sh
./start-yarn.sh
启动成功,访问http://master:8088/cluster
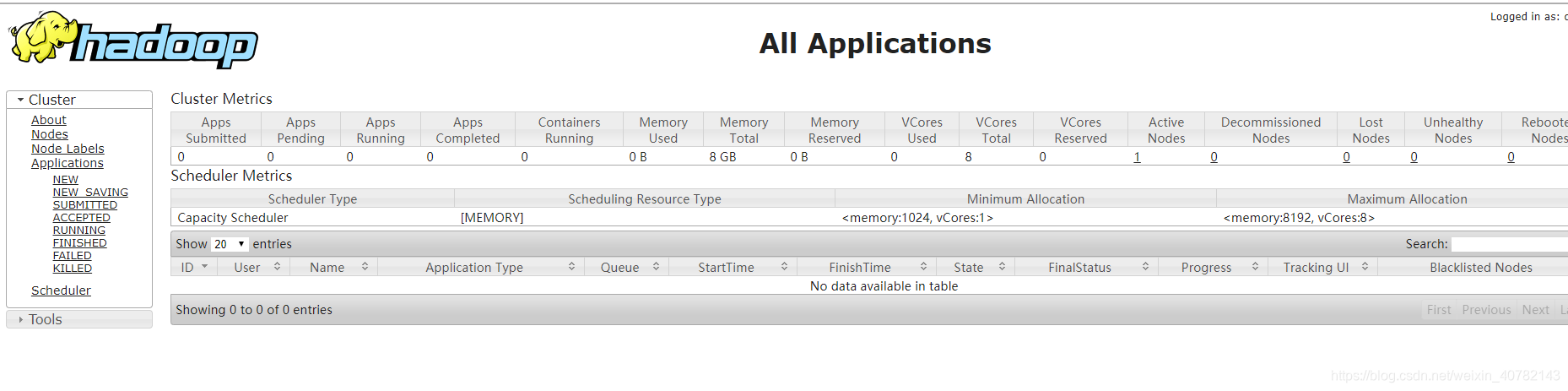

















 1488
1488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









