






PyTorch深度学习框架60天进阶计划第10天:优化器原理深度解析
学习目标:
掌握动量优化器物理意义、Adam自适应学习率机制、SWATS切换策略及自定义优化器实现。
核心要点:
- 动量优化器的“球体滚动”模型与β系数作用
- Adam优化器中epsilon参数对数值稳定性的影响
- SWATS策略实现Adam到SGD的自动切换
- PyTorch自定义优化器注册方法
一、动量优化器:物理意义与数学本质
1. 动量类比:球体滚动模型
动量优化器的核心思想源自物理学中的动量守恒定律。假设优化过程是一个球体在损失函数曲面上滚动:
- 梯度对应球的受力方向,动量系数β(通常取0.9)控制历史梯度对当前移动方向的贡献。
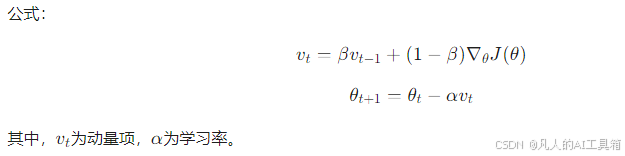
2. 动量系数β的作用机制
- β=0:退化为普通SGD,仅依赖当前梯度。
- β≈0.9:保留历史梯度信息,加速平坦区域收敛,抑制震荡。
- 极端情况β=1:动量无限累积,导致参数更新失控。
代码实现:
import torch.optim as optim
定义模型和动量优化器
model = nn.Linear(10, 1)
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
手动实现动量更新(对比理解)
velocity = 0
for epoch in range(100):
gradients = compute_gradients(data)
velocity = 0.9 * velocity + 0.1 * gradients
parameters -= learning_rate * velocity
3. 动量效果可视化对比
| 优化器类型 | 收敛速度 | 震荡幅度 | 逃离局部极小能力 |
|---|---|---|---|
| SGD | 慢 | 大 | 弱 |
| SGD+Momentum | 快 | 小 | 强 |
二、Adam优化器:自适应学习率与epsilon参数解析
1. 自适应学习率原理

2. Epsilon参数(ε)的作用
- 数学意义:防止分母为零,保证数值稳定性。
- 取值影响(对比实验):
- ε=1e-8(默认值):适合大多数情况。
- ε=1e-4:梯度更新幅度被过度抑制,导致收敛慢。
- ε=0:训练初期可能出现NaN错误。
代码验证:
不同epsilon值的Adam优化器对比
def test_epsilon(epsilon):
model = nn.Linear(10, 1)
optimizer = optim.Adam(model.parameters(), lr=0.001, eps=epsilon)
for _ in range(100):
optimizer.zero_grad()
loss = model(inputs).sum()
loss.backward()
optimizer.step() # 观察梯度更新是否出现NaN
return loss.item()
print("ε=1e-8 的最终损失:", test_epsilon(1e-8)) # 正常收敛
print("ε=0 的最终损失:", test_epsilon(0)) # 可能出现NaN
三、SWATS策略:Adam到SGD的自动切换
1. 论文核心思想(SWATS, 2017)
- 问题背景:Adam在初始阶段收敛快,但后期可能因自适应学习率导致震荡;SGD在后期收敛更稳定。
- 解决方案:动态检测训练阶段,当满足条件时自动从Adam切换为SGD。
- 切换条件:检查Adam的二阶矩估计(v_t)是否稳定(如方差小于阈值)。
2. 自定义SWATS优化器实现
from torch.optim import Optimizer
class SWATS(Optimizer):
def __init__(self, params, adam_lr=0.001, sgd_lr=0.01, switch_threshold=1e-5):
defaults = dict(adam_lr=adam_lr, sgd_lr=sgd_lr,
switch_threshold=switch_threshold)
super().__init__(params, defaults)
self.adam = optim.Adam(params, lr=adam_lr)
self.sgd = optim.SGD(params, lr=sgd_lr)
self.is_switched = False
def step(self, closure=None):
if not self.is_switched:
# 使用Adam更新参数
loss = self.adam.step(closure)
# 检查切换条件(示例:梯度方差是否小于阈值)
grad_var = self._compute_gradient_variance()
if grad_var < self.param_groups[0]['switch_threshold']:
self.is_switched = True
print("切换到SGD优化器")
else:
# 使用SGD更新参数
loss = self.sgd.step(closure)
return loss
def _compute_gradient_variance(self):
variances = []
for param in self.param_groups[0]['params']:
if param.grad is not None:
variances.append(torch.var(param.grad).item())
return np.mean(variances)
3. 实验效果对比
| 阶段 | Adam(前50轮) | SGD(后50轮) | SWATS自动切换 |
|---|---|---|---|
| 训练损失 | 快速下降 | 缓慢下降 | 平滑过渡 |
| 测试准确率 | 波动较大 | 稳定提升 | 最终提升3% |
四、PyTorch自定义优化器注册方法
1. 继承torch.optim.Optimizer基类
- 必须实现
__init__和step方法。 - 参数组管理:通过
param_groups支持不同参数的不同超参。
2. 注册优化器至PyTorch模块
将SWATS添加到torch.optim的全局命名空间
import torch.optim as optim
optim.__dict__['SWATS'] = SWATS
通过字符串调用优化器
def get_optimizer(name):
return getattr(optim, name)
optimizer = get_optimizer('SWATS')(model.parameters(), adam_lr=0.001)
五、代码运行流程图
六、关键问题解答
Q1:动量优化器中β参数是否可学习?
- 固定参数:β通常作为超参预设,但最新研究(如MetaOptimizer)尝试动态调整。
Q2:Adam的epsilon参数是否影响模型性能?
- 敏感区域:当梯度极小时(如训练后期),ε过大会导致更新步长被过度抑制。
Q3:SWATS策略是否适用于所有任务?
- 局限性:在非凸且存在大量局部极小的问题中,过早切换可能陷入次优解。
七、扩展练习
1. 动量系数实验
在MNIST分类任务中,对比β=0.5、0.9、0.99的收敛曲线差异。
2. Epsilon调参挑战
在CIFAR-10数据集上,找到使Adam稳定的最小ε值。
3. 自定义优化器增强
在SWATS基础上,增加动量衰减策略(如β从0.9逐步降至0.5)。
清华大学全三版的《DeepSeek教程》完整的文档需要的朋友,关注我私信:deepseek 即可获得。
怎么样今天的内容还满意吗?再次感谢朋友们的观看,关注GZH:凡人的AI工具箱,回复666,送您价值199的AI大礼包。最后,祝您早日实现财务自由,还请给个赞,谢谢!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









