







 本文深入探讨InnoDB存储引擎中的主键与索引概念,包括查看索引的方法、explain语句解析、多列索引使用、null值处理、全文索引原理及应用场景,帮助读者全面理解InnoDB索引机制。
本文深入探讨InnoDB存储引擎中的主键与索引概念,包括查看索引的方法、explain语句解析、多列索引使用、null值处理、全文索引原理及应用场景,帮助读者全面理解InnoDB索引机制。
InnoDB默认主键与索引
1.InnoDB中主键与聚簇索引的必要性
- When you define a PRIMARY KEY on your table, InnoDB uses it as the clustered index.
- If you do not define a PRIMARY KEY for your table, MySQL picks the first UNIQUE index that has only NOT NULL columns as the primary key and InnoDB uses it as the clustered index.
- If there is no such index in the table, InnoDB internally generates a clustered index where the rows are ordered by the row ID that InnoDB assigns to the rows in such a table. The row ID is a 6-byte field that increases monotonically as new rows are inserted. Thus, the rows ordered by the row ID are physically in insertion order.
翻译过来就是:
- 如果表中定义了PRIMARY KEY,InnoDB会将其用作聚集索引;
- 如果表中没有定义主键,mysql会选择第一个为unique且not null的索引作为表的主键,并将其作为聚簇索引;
- 如果表中没有unique¬ null的索引,InnoDB会自动生成一个自增主键,并将其作为聚簇索引。
1. 查看索引的语句
-- 查询数据库的信息(列名等)
desc '表名';
-- 查询某个表中的所有列
show colunms from '表名';
-- 查询某个表的索引,注意,主键也是索引的一种,或者说在主键上面默认建立了聚簇索引(但是不能查到隐藏的自增主键)
show index from '表名';
1)建立有主键的表,
create table test(
id int not null,
primary key(id)); # 主键
建表后查询索引:
mysql> show index from test;
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| test | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | | YES | NULL |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
2)再试试用多列索引
drop table test;//先删掉刚刚的test表
create table test(
id1 int not null,
id2 int not null,
primary key(id1,id2) );
建表后查询索引:
mysql> show index from test;
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| test | 0 | PRIMARY | 1 | id1 | A | 0 | NULL | NULL | | BTREE | | | YES | NULL |
| test | 0 | PRIMARY | 2 | id2 | A | 0 | NULL | NULL | | BTREE | | | YES | NULL |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
2. explain的用法
官方文档
MySQL优化——看懂explain
需要注意的是,对于同一个查询语句,如果表中的数据不一样,explain的结果可能会不一样,也就是说,explain的结果不是绝对的,这取决于MYSQL的判断。先看一个例子:
mysql> explain select * from muti_keys_index where last_name='Widenius';
+----+-------------+-----------------+------------+------+---------------+------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------+------------+------+---------------+------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | muti_keys_index | NULL | ref | name | name | 90 | const | 1 | 100.00 | Using index |
+----+-------------+-----------------+------------+------+---------------+------+---------+-------+------+----------+-------------+
各个字段的意思:
1.id
select识别符,即查询序列号;
2.select_type
| 取值 | 描述 |
|---|---|
| SIMPLE | 简单select,不使用union或子查询 |
| PRIMARY | 最外层的select |
| UNION | UNION中的第二个或后面的SELECT语句 |
| SUBQUERY | 子查询中的第一个SELECT |
| … | … |
3.table
输出的行所引用的表。
4.type
描述如何联接表,下面显示了从最差到最好类型排序,注意:一般保证查询至少达到range级别,最好能达到ref。
| 取值 | 描述 |
|---|---|
| ALL | 遍历全表以找到匹配的行 |
| index | 与ALL类似,区别是index只需要遍历索引树 |
| range | 使用索引选择行,仅检索给定范围内的行,key列显示了哪个索引; 在将键列与常量进行比较时可以使用range;例如使用=、<=>、>、>=、<、<= 、is NULL、BETWEEN、IN |
| index_subquery | |
| unique_subquery | |
| index_merge | 使用了索引合并优化方法 |
| ref_or_null | 类似于ref,但是除此之外,MYSQL还会额外搜索包含NULL值的行 |
| ref | 非唯一性索引扫描,返回符合条件的多行,本质上也是索引访问; 使用场景:1)值只用多列索引的最左前缀;2)索引不是unique或者primary key; |
| eq_ref | … |
| const | 最多匹配一行,用于比较primary key或者unique索引,只匹配一行数据 |
| system | 该表只有一行(=system table),是const的一种特例,很难达到 |
5.possible_keys
可能应用到的索引。
6.key
实际应用的索引,需要注意,type = index时,也应用到了索引,尽管是扫描整个索引树。
7.key_len
表示索引中使用的字节数,在不损失精度的情况下越短越好。
8.ref
表示索引的哪一列被使用了。
9.rows
根据表的统计信息及索引的统计情况,大致估算找出所需记录需要读取的行数。
10.extra
extra列包含有关MYSQL如何解析查询的补充信息。
| 取值 | 描述 |
|---|---|
| Using index | 在查找过程中,仅在索引树中进行查找,无需进行其他测试就读取实际的行数据 |
| Using index condition | 首先从索引树上读取索引元组,然后对其进行测试,根据测试结果决定是否读取实际的行数据 |
| Using where | 使用where进行过滤,决定哪些行将被发送给客户端 |
| … | … |
多列索引
举例子来说明,创建多列索引name(last_name,first_name),当查询条件为last_name,或者为last_name and first_name时索引发挥作用。
CREATE TABLE muti_keys_index (
id INT NOT NULL,
last_name CHAR(30) NOT NULL,
first_name CHAR(30) NOT NULL,
PRIMARY KEY (id),
INDEX name (last_name,first_name)
);
insert into muti_keys_index values(1,"aaa","bbb");
insert into muti_keys_index values(2,"aaa","bbc");
insert into muti_keys_index values(3,"aaa","bbd");
insert into muti_keys_index values(4,"aab","bbb");
insert into muti_keys_index values(5,"aab","bbb");
以下情形会用到name索引:
SELECT * FROM muti_keys_index WHERE last_name='Widenius';
SELECT * FROM muti_keys_index WHERE last_name='Widenius' AND first_name='Michael';
SELECT * FROM muti_keys_index WHERE last_name='Widenius' AND (first_name='Michael' OR first_name='Monty');
SELECT * FROM muti_keys_index WHERE last_name='Widenius' AND first_name >='M' AND first_name < 'N';
以下情形不会使用name索引:
SELECT * FROM muti_keys_index WHERE first_name='Michael';
SELECT * FROM muti_keys_index WHERE last_name='Widenius' OR first_name='Michael';
3. explain实例
在刚刚建立的表上进行explain分析:
1)查询条件id = 2,type字段是const,即唯一性索引的单独值比较:
mysql> explain select id from muti_keys_index where id = 2;
+----+-------------+-----------------+------------+-------+----------------+---------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------+------------+-------+----------------+---------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | muti_keys_index | NULL | const | PRIMARY,id_idx | PRIMARY | 4 | const | 1 | 100.00 | Using index |
+----+-------------+-----------------+------------+-------+----------------+---------+---------+-------+------+----------+-------------+
2)查询条件last_name='Widenius',type字段是ref,即非唯一性索引的单独值比较:
mysql> explain select * from muti_keys_index where last_name='Widenius';
+----+-------------+-----------------+------------+------+---------------+------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------+------------+------+---------------+------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | muti_keys_index | NULL | ref | name | name | 90 | const | 1 | 100.00 | Using index |
+----+-------------+-----------------+------------+------+---------------+------+---------+-------+------+----------+-------------+
3)查询条件last_name = 'abs' and first_name = 'abs',type也是ref(同上),此外,mysql会自动调整关键字的顺序:
mysql> explain select id from muti_keys_index where last_name = 'abs' and first_name = 'abs';
+----+-------------+-----------------+------------+------+---------------+------+---------+-------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------+------------+------+---------------+------+---------+-------------+------+----------+-------------+
| 1 | SIMPLE | muti_keys_index | NULL | ref | name | name | 180 | const,const | 1 | 100.00 | Using index |
+----+-------------+-----------------+------------+------+---------------+------+---------+-------------+------+----------+-------------+
# 交换first_name 与last_name的位置,结果不变
mysql> explain select id from muti_keys_index where first_name = 'abs'and last_name = 'abs';
+----+-------------+-----------------+------------+------+---------------+------+---------+-------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------+------------+------+---------------+------+---------+-------------+------+----------+-------------+
| 1 | SIMPLE | muti_keys_index | NULL | ref | name | name | 180 | const,const | 1 | 100.00 | Using index |
+----+-------------+-----------------+------------+------+---------------+------+---------+-------------+------+----------+-------------+
4)查询条件first_name = 'abs',type字段变成了index,说明索引未命中,但是遍历的是索引树而不是数据表;
mysql> explain select * from muti_keys_index where first_name = 'abs';
+----+-------------+-----------------+------------+-------+---------------+------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------+------------+-------+---------------+------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | muti_keys_index | NULL | index | name | name | 180 | NULL | 1 | 100.00 | Using where; Using index |
+----+-------------+-----------------+------------+-------+---------------+------+---------+------+------+----------+--------------------------+
5)查询条件id>2,type字段是range,即利用索引进行范围查找:
mysql> explain select id from muti_keys_index where id > 2;
+----+-------------+-----------------+------------+-------+---------------------+--------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------+------------+-------+---------------------+--------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | muti_keys_index | NULL | range | PRIMARY,name,id_idx | id_idx | 4 | NULL | 3 | 100.00 | Using where; Using index |
+----+-------------+-----------------+------------+-------+---------------------+--------+---------+------+------+----------+--------------------------+
4. null相关
NULL columns require additional space in the rowto record whether their values are NULL. For MyISAM tables, each NULL columntakes one bit extra, rounded up to the nearest byte.
- NULL所在列需要额外的空间来记录其值是否为NULL(上面的翻译结果);
- mysql难以优化包含null值的列查询,null会使索引,索引统计更加复杂;
- null还容易出错;
4.1 不使用NULL的理由
1.所有使用NULL值的情况,都可以通过一个有意义的值的表示,这样有利于代码的可读性和可维护性,并能从约束上增强业务数据的规范性;
2.NULL值到非NULL值的更新通常无法做到原地更新,容易发生索引分裂,影响性能;
3.NULL值在timestamp类型下容易出问题,特别是没有启用参数;
4.null在查询中容易出错,先建立表:
-- 一个允许null的表
CREATE TABLE `not_null_2` (
`id` int(11) NOT NULL,
`user_name` varchar(20)
);
create index index1 on not_null_2(user_name);
insert into not_null_2 values(1,"aa"),(2,"ab"),(3,"cc"),(4,"dc"),(5,null);

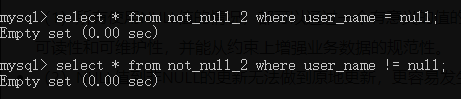
1)正确的null值查询方法是is null和is not null,因此如果误用= null或者 != null就会得到空集:
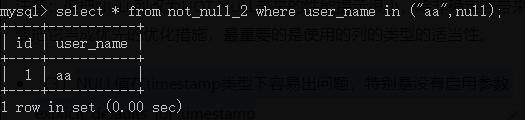
2)使用in 和not in容易产生奇怪的结果,个人理解,in和not in的本质就是 = 或 !=:in (value1,value2) 等价于 = value1 or = value2 , not in (value1,value2)等价于 != value1 and != value2,因此,以下语句的结果就能解释得通了:
user_name in ("aa",null) 相当于 user_name = "aa" or user_name = null :
3)user_name not in (null) 等价于 user_name != null,因此结果为空:

4)同3),user_name not in ("aa",null)返回user_name != "aa" and user_name != null,而user_name != null 是任意一行都无法满足的,因此最终结果为空:

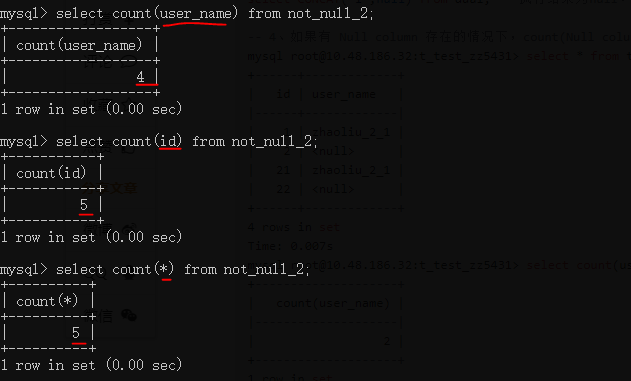
5)在null值列进行count()统计,null值不参与统计:
5.null值列会占用更多的空间,先建立一个不允许null的表便于对比:
-- 一个不允许null的表
CREATE TABLE `not_null_1` (
`id` int(11) NOT NULL,
`user_name` varchar(20) NOT NULL
);
create index index1 on not_null_1(user_name);
1)在not_null_1表中,user_name列是not null的,观察user_name索引,可以看到key_len为62,其中2个字节是varchar用来储存长度的,剩下60个字节是储存20个char字符的(每个char字符占3字节)。
mysql> explain select * from not_null_1 where user_name = "aa";
+----+-------------+------------+------------+------+---------------+--------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+------+---------------+--------+---------+-------+------+----------+-------+
| 1 | SIMPLE | not_null_1 | NULL | ref | index1 | index1 | 62 | const | 1 | 100.00 | NULL |
+----+-------------+------------+------------+------+---------------+--------+---------+-------+------+----------+-------+
2)在not_null_2表中,user_name列是允许null的,观察user_name索引,可以看到key_len为63,多出来的一位就是用来标记为null的:
mysql> explain select * from not_null_2 where user_name = "aa";
+----+-------------+------------+------------+------+---------------+--------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+------+---------------+--------+---------+-------+------+----------+-------+
| 1 | SIMPLE | not_null_2 | NULL | ref | index1 | index1 | 63 | const | 1 | 100.00 | NULL |
+----+-------------+------------+------------+------+---------------+--------+---------+-------+------+----------+-------+
4.2 null值与索引
- null值的定义:null值被定义为最小的值,对于有null值的索引而言,null值应该是储存在B+树的最左边。
We define the SQL null to be the smallest possible value of a field.
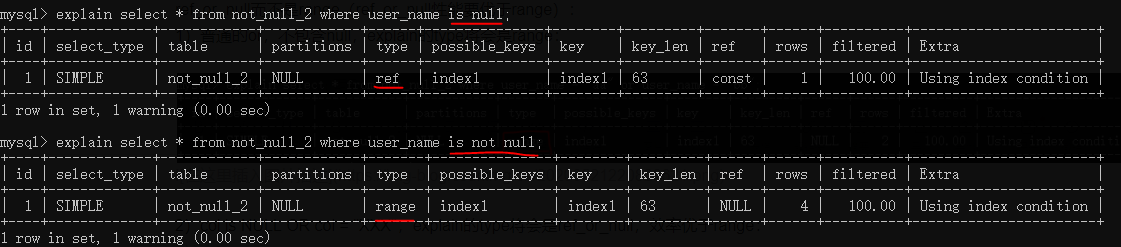
- 需要认识到,null值是支持索引的,例如is null 和 is not null都可以覆盖索引,值得注意的是:
- null值还可能有优化,在允许null值的列上,如果查询语句为col_name = expr OR col_name is NULL,那么将会被优化,explain的type为ref_or_null而不是range(ref_or_null性能要优于range):
1)普通的or,不包含null,explain的type将会是range:

2)col is NULL OR col = “XXX”,explain的type将会是ref_or_null,效率优于range:

5. 全文索引
https://www.cnblogs. . .
https://wenku.baidu.com. . .
5. 1 为什么需要全文索引
针对char,varchar和text类型的数据,我们可以建立普通的索引,当我们去查找其中的某些字符串时,如果能够命中索引(%前缀无法命中)那么效率并不差。但是在某些情况下普通索引往往无法命中,例如某个字段是一段话,我们需要从很多段话里面找到某个单词,相当于从整个文本中来找出某个单词,这时候就只能全文扫描,效率很低,因此引入全文索引来提高全文查找的效率。
5.2 定义
现在的MYISAM和INNODB引擎都支持全文索引,全文索引(fulltext)又被称为倒排索引。我们可以对某个字段建立,但是不可以对多个字段建立全文索引(待考证)。
5.3 原理
当我们在某个字段上面建立全文索引时,会将该字段所有文本中的单词及其所在行号(主键)形成一个倒排表,例如:

因此使用全文索引的查找过程就是:首先在全文索引的B+树上面查找对应的单词,找到之后再到该单词的倒排链表中拿到对应的主键号,然后再到聚簇索引上面找到相应的记录。
5.4 优缺点
- 相对于普通的二级索引来说,占有的储存空间大,如果内存不能一次加载整个全文索引,那么效率会比较差;
- 维护成本高,如果修改某一行该字段的10个单词,那么要修改的就是倒排链表的10个地方,而普通的索引只需要修改一个地方;
6. 一些问题
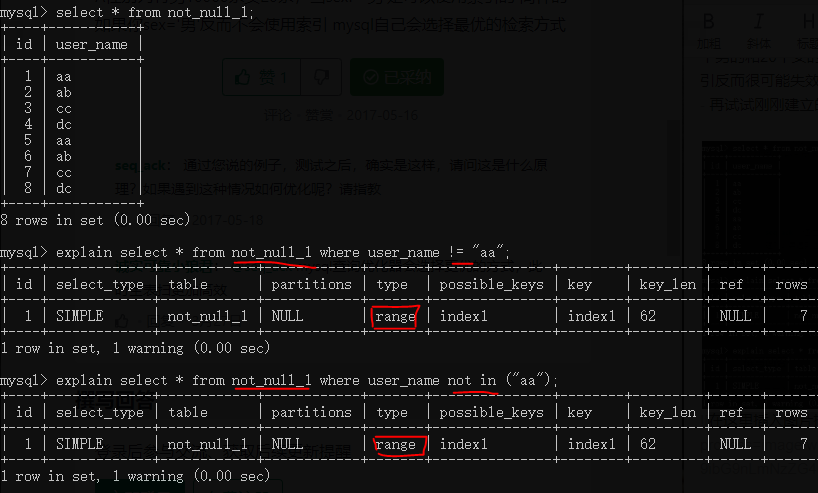
1.!= 、not in是否一定会导致索引失效?
- 首先,索引是否失效取决于mysql的判断,不是绝对的;
- not in或者!=不一定会导致索引失效,对于数据分布较为均匀的行容易失效,但是如果数据分布严重不均匀又可能会不失效。
- 举个例子,对于sex字段,假设有10000个男的和20个女的,那么查询条件为sex != '男’时就索引很可能生效;而使用sex = '男’时,索引反而很可能失效,转为全表扫描;
- 再试试刚刚建立的not_null_1表,explain查询语句
!= 和 not in,可以看到type为range,也就是说mysql选择了使用索引(这里不用纠结使用索引的效率好还是坏,因为mysql也不能确定每次选择的效率都是最高的)
TODO
0)多看官方文档。
1)理解B+树索引的工作过程。
2)可以看看这篇文章的后半部分
3)order by、distinct等对索引效率的影响。
4)间隙锁相关。

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









