







sqoop
1 采用map-reduce计算框架进行导入导出,采用map-reduce框架同时在多个节点进行import或者export操作
2 用于 关系型数据库和hadoop组件之间进行数据迁移 , 不支持hadoop相关库组件、rdbms之间数据抽取操作
3 对hadoop支持度好
4 sqoop只支持官方提供的指定几种关系型数据库和hadoop组件之间的数据交换
5 数据库同步两种方式,1,JDBC的连接 √ 2,使用数据库提供的工具
JDBC:
数据分片采用通用方式,用count聚合函数获取需要同步的数据量nums,获取设置的map数m,nums/m就是每个map需要同步的数据量
6 同步过程分为三个步骤:1,对数据分片;2,读取数据;3,写入数据
7 速度比单节点运行多个并行导入导出效率高,同时提供了良好的并发性和容错性
datax
1 仅仅在运行datax的单台机器上进行数据的抽取和加载
2 用于 异构库之间的数据抽取 关系型数据库和hadoop组件之间、关系型数据库之间、hadoop组件之间的数据迁移
3 datax中,用户只需根据自身需求修改文件,生成相应rpm包,自行安装之后就可以使用自己定制的插件
4 支持数据不落地的并行导入导出
5 支持从一个HDFS集群到另一个HDFS集群之间的数据导入导出
6 数据的传输全部依赖内存,实现基本原理类似flume,memorychanne
区别
1 sqoop采用map-reduce计算框架进行导入导出,而datax仅仅在运行datax的单台机器上进行数据的抽取和加载,速度比sqoop慢了许多
2 sqoop的direct模式的性能会比datax更高,而且sqoop是站在大象的肩膀上,稳定性会比单机版的datax来得高
sqoop架构图
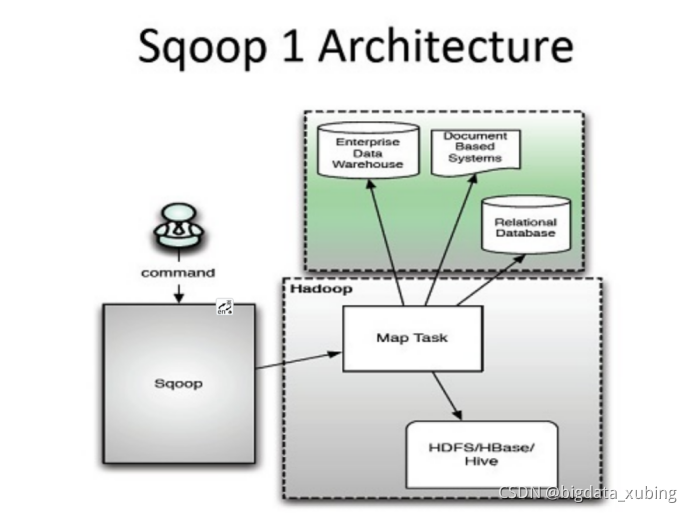
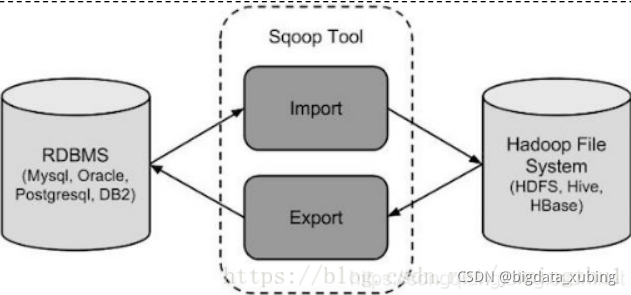
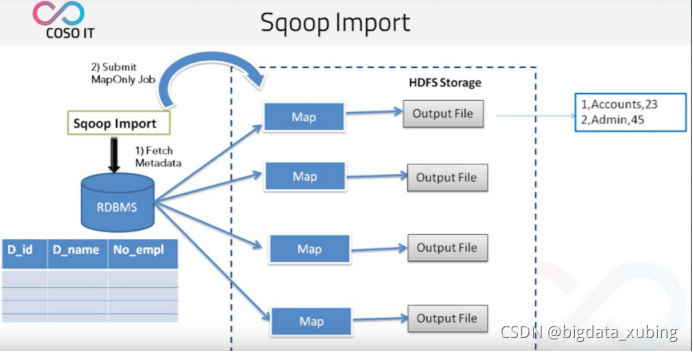
Sqoop 如何抽取数据:
1. 首先 Sqoop 去 rdbms 抽取元数据。
2. 当拿到元数据之后将任务切成多个任务分给多个 map。
3. 然后再由每个 map 将自己的任务完成之后输出到文件。
datax架构图:
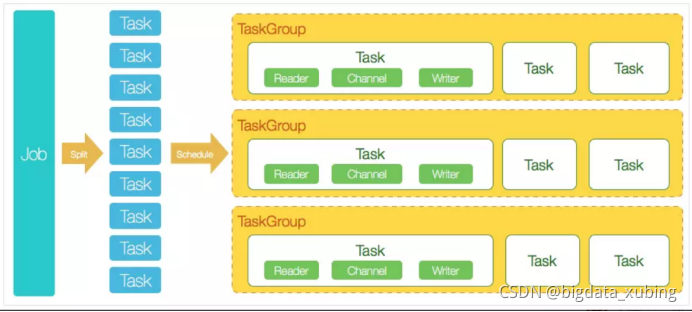

















 3964
3964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









