







1 hive架构
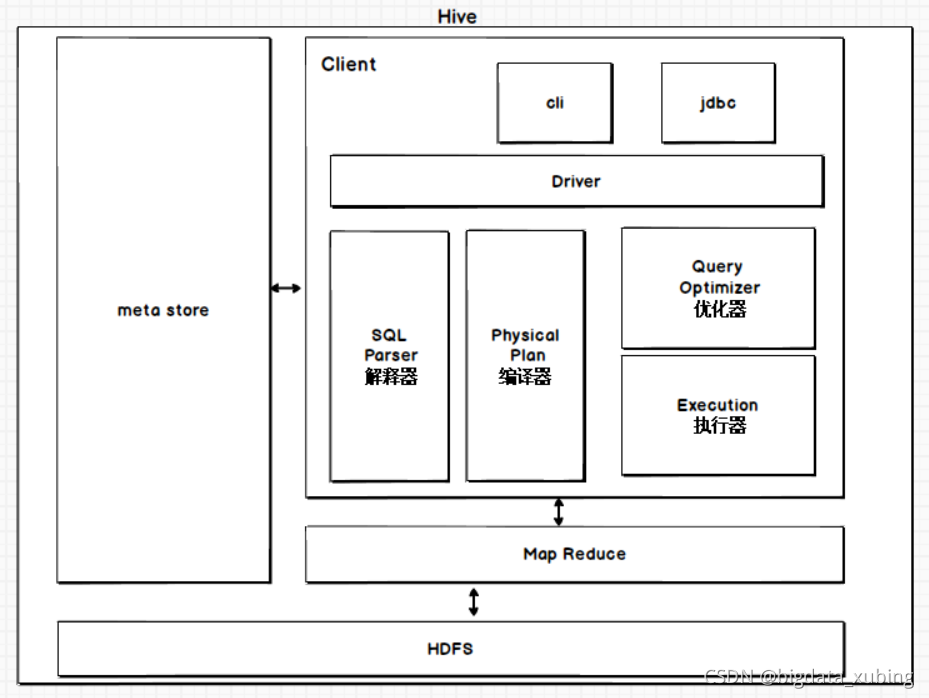
1.1 组成及作用
- 用户接口:
- clientcli(hive shell)、jdbc/ODBC(java访问hive) 、webUI(浏览器访问hive)
- 元数据meta store
- 表所属的数据库
- 表名
- 列、分区字段
- 表的类型
- 表所在的数据目录
- 注:默认存储在自带的Derby数据库中,一般使用mysql出处Metastore
- 底层存储: HDFS
- 计算:MapReduce
- 驱动器Driver:接收/响应客户端请求
- 解释器 SQL Parser: 将SQL文本转化为AST抽象语法树,对AST进行语法分析,比如表、字段是否存在、SQL语义是否错误
- 编译器 Physical Plan:将AST编译生成逻辑执行计划
- 优化器 Query Optimizer: 对逻辑执行计划进行优化
- 执行器 Execution : 将逻辑计划转化成可执行的物理计划。对hive来说就是 mr、spark
2 hive工作原理
- 用户创建数据库、表信息,存储在元数据库中
- 向表中加载数据,元数据记录hdfs存储路径与表之间的映射关系
- 执行查询语句,首先经过 解释器、编译器、优化器、执行器,将指令翻译成MapReduce,提交到yarn上执行,最后将执行结果输出到用户交互接口


















 1155
1155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









