









背景
做项目经常会对基础地理数据、业务数据等shp发geoserver服务,常规发服务需要将矢量数据导入到数据库中,然后通过手工操作geoserver一个一个的设置参数,发服务。由于矢量图层文件较多,手动发布费时费力,同时反复设置相同的参数不胜其烦。
通过研究参考相关文献,翻遍全网没有找到一个比较好的方法,通过自己研究并实现批量发布geoserver服务的方法,现分享出来,解决大家体力劳动,因非计算机专业,有不对支持多包涵。
1、环境
1)python3.9版本;
2)geoserver 2.21版本;
3)第三方包geoserver-restconfig 2.0.7版本;第三方包地址(https://pypi.org/project/geoserver-restconfig), 连接有帮助和说明;
pip install geoserver-restconfig 2.0.72、实现思路
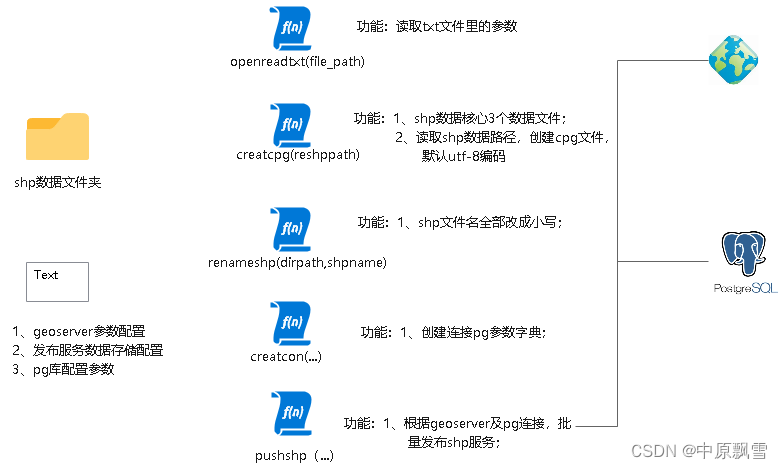
图1

图2 配置参数
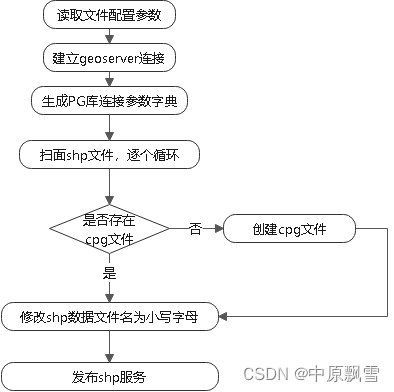
图3
1、现在还没学会python的界面开发,需要设置的参数较多,故单独创建一个text文件用于灵活配置参数;
2、已对程序打包成一个单独的exe文件,脱离开发环境也能运行,text配置文件配置参数更方便;
3、有需要留言交流。
# -*- coding: utf-8 -*-
import os
from geoserver.catalog import Catalog
###############################
tt='config.txt' #主程序同目录下的参数配置文件名称
data=[] #用于存储从text文件获取的参数
geourl=''
geouser=''
geopassword =''
geoworkspace=''
geodatastore= ''
shppath=''
postgreshost=''
postgreport=''
postgredatabase=''
postgreuser=''
postgrepassword=''
postgreschema=''
###############################################################################
##打开同目录下的Text文件,循环读取每行数据,根据=号进行分解
##并将等号后的参数追加到dataL列表里
##############################################################################
def openreadtxt(file_name):
file = open(file_name,'r') #打开文件
#print(file)
while True:
line = file.readline()
if not line:
break
line = line.strip('\n') # 删除指定字符,strip('\n')删除换行符
#print (line)
a,b=line.split('=')
data.append(b)
#print(b)
file.close()
################################################################################
##根据传入路径参数,新建cpg文件
###############################################################################
def creatcpg(reshppath): #批量创建cpg
file = reshppath+".cpg"
#print(file)
isExists=os.path.exists(file) #判读cpg文件是否存在
if not isExists:
with open(file, "w") as file:
file.write('utf-8') #向cpg文件里写入UTF-8编码
else:
return
###################################################################################
##根据传入的路径及文件名,对大写的文件名重命名小写
###################################################################################
def renameshp(dirpath,shpname):
newshpname=shpname.lower()
oldshp = dict((ext, dirpath+"\\"+shpname+"."+ext) for ext in ["shp", "prj", "shx", "dbf","cpg"]) #构建文件后缀为键,文件全路径为键值的字典
newshp = dict((ext, dirpath+"\\"+newshpname+"."+ext) for ext in ["shp", "prj", "shx", "dbf","cpg"])
os.rename(oldshp['shp'],newshp['shp'])
os.rename(oldshp['prj'],newshp['prj'])
os.rename(oldshp['shx'],newshp['shx'])
os.rename(oldshp['dbf'],newshp['dbf'])
os.rename(oldshp['cpg'],newshp['cpg'])
#print(newshp)
###############################################################################################
##根据传入的postgres数据库参数创建后面用于数据库连接参数的字典
###################################################################################
def creatcon(postgreshost,postgreport,postgredatabase,postgreuser,postgrepassword,postgreschema):
thisdict = {
'Evictor run periodicity': 300,
'Estimated extends': 'true',
'schema': "public",
'fetch size': 10000,
'encode functions': 'false',
'Expose primary keys': 'true',
'validate connections': 'true',
'Support on the fly geometry simplification': 'true',
'Method used to simplify geometries': 'FAST',
'Connection timeout': 10,
'create database': 'false',
'Batch insert size': 30,
'preparedStatements': 'true',
'min connections': 10,
'max connections': 100,
'Evictor tests per run': 3,
'Max connection idle time': 300,
'Loose bbox': 'true',
'Test while idle': 'true',
'host': "",
'port': "",
'database': "",
'user': "",
'passwod': "",
'dbtype': "postgis",
'schema': ""}
thisdict["host"]=postgreshost
thisdict["port"]=postgreport
thisdict["database"]=postgredatabase
thisdict["user"]=postgreuser
thisdict["passwd"]=postgrepasswd
thisdict["schema"]=postgreschema
return thisdict
##################################################################################
##传入geoserver连接,发布服务的工作空间及资源仓库,发布服务文件名,以及文件去后缀的路径
###################################################################################
def pushshp(cat,workspace,datastore,con,newshpname,newshpallpath):
ws = cat.get_workspace (workspace) #geoserver的工作空间
if ws is None:
ws = cat.create_workspace(workspace,workspace) #如果工作空间不存在创建工作空间
ds = cat.get_store (datastore, workspace) #获取资源仓库
if ds is None:
ds = cat.create_datastore(datastore, workspace) #如果资源仓库不存在创建资源仓库
ds.connection_parameters.update (con) #更新资源仓库的pg数据库连接参数
cat.save(ds)
shp = dict((ext,newshpallpath+"."+ext) for ext in ["shp", "prj", "shx", "dbf","cpg"]) #构建shp数据后缀为键,文件全路径为键值的字典
#print(shp)
print("正在发布"+ newshpname)
cat.add_data_to_store(ds,newshpname,shp) #构建shp数据后缀为键,文件全路径为键值的字典
print("发布成功" + newshpname)
#################################################
##运行主程序
#################################################
if __name__=="__main__":
openreadtxt(tt)
#assignment(data)
geourl,geouser,geopassword,geoworkspace,geodatastore,shppath,postgreshost,postgreport,postgredatabase,postgreuser,postgreword,postgreschema = data #将从text获取的参数赋值给全局变量
cat = Catalog(geourl,geouser,geopasswd)
con=creatcon(postgreshost,postgreport,postgredatabase,postgreuser,postgrepassword,postgreschema) #调用函数创建PG数据库连接字典
print ("连接geoseve服务成果"+str(cat))
print ("检查文件夹路径……")
if os.path.isdir(shppath) == False:
print ("输入的文件夹路径无效!")
print ("开始发布服务,请稍后.....")
for (dirpath, dirnames,filenames) in os.walk(shppath):
for file in filenames:
if file.endswith(".shp"): #查找后缀为shp的文件
shpname,filenamefix=os.path.splitext(file) #将文件分解为文件名及后缀
oldshpallpath = os.path.join(dirpath,shpname) #连接路径及文件名
#print(oldshpallpath)
creatcpg(oldshpallpath) #调用创建cpg文件函数
renameshp(dirpath,shpname) #将shp大写的命名为小写
newshpname=shpname.lower()
#print(newshpname)
newshpallpath = os.path.join(dirpath,newshpname) #用小写文件名组成新的路径
pushshp(cat,geoworkspace,geodatastore,con,newshpname,newshpallpath) #调用发布服务函数
else:
continue

















 7591
7591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









