






 博客围绕Elasticsearch展开,介绍了其倒排索引,底层基于Netty;阐述了数据存储概念;讲解了Kibana操作;还说明了其内部管理集群的方式,对比了Solr,提及ik分词器、命令查看信息和锁等内容。
博客围绕Elasticsearch展开,介绍了其倒排索引,底层基于Netty;阐述了数据存储概念;讲解了Kibana操作;还说明了其内部管理集群的方式,对比了Solr,提及ik分词器、命令查看信息和锁等内容。
**
倒排索引
底层基于netty
**
根据文本找id
**
数据存储的概念
**
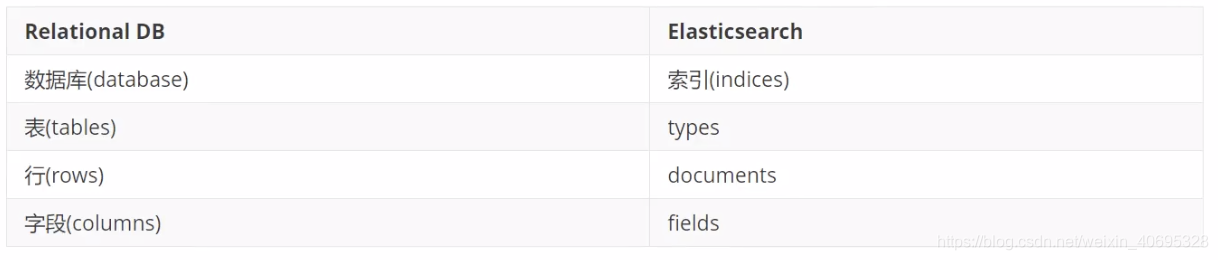
Relationnal DB -> Databases -> Tables -> Rows -> Columns
elasticsearch - > indices -> Types ->Doucments -> Fields
**
kibana操作
**
存入文档
PUT /indices/Types/1
{
"name":"aaa",
"age":22,
"subject":"cccc",
"dept":"aaaa"
}
检索:
GET /indices/Types/1 查询id为1的
GET /indices/Types/_search 查询全部
GET /indices/Types/_search?q=name:aa 查询名字有aa的
DSL检索:
GET /indices/Types/_search
{
"query": {
"match": {
"subject": "human"
}
}
}
模糊查询:能容忍查询的某些字母不一样
GET /indices/Types/_search
{
"query": {
"fuzzy": {"subject": "homan"}
}
}
查询前过滤: 比查询后过滤好 因为先过滤掉会减少查询 而且elasticsearch的过滤有缓存 对日后的查询也会起到帮助
bool可以用来多条件查询, or 查询 must mustnot查询
GET /indices/Types/_search
{
"query": {
"bool": {
"filter": {"term": {
"age": "30"
}}
, "must": [
{"match": {
"subject": "human"
}}
]
}
}
}
查询后过滤:
GET /indices/Types/_search
{
"query": {
"match": {
"subject": "human"
}
}
, "post_filter": {
"term": {
"emp_age": "30"
}
}
}
根据范围过滤:
GET /indices/Types/_search
{
"query": {
"bool": {
"filter": {
"range": {
"age": {
"gt": 20,
"lt": 50
}
}
}
}
}
}
排序:
GET /indices/Types/_search
{
"query": {
"match": {
"name": "tom jerry"
}
}
, "sort": [
{
"age": {
"order": "asc"
}
}
]
}
分页查询:
GET /indices/Types/_search
{
"query": {
"match_all": {}
}
, "from": 1
, "size": 1
}
投影查询:只查询出部分的字段
GET /indices/Types/_search
{
"query": {
"match_all": {}
}
, "_source": ["age","name"]
}
高亮查询:
GET /indices/Types/_search
{
"query": {
"match": {
"subject": "human"
}
}
, "highlight": {
"fields": {"emp_subject": {}}
, "pre_tags": ["<span style='color:red'>"]
, "post_tags": ["</span>"]
}
}
聚合查询: 查询后 基于某个不分词的字段进行分组
GET /indices/Types/_search
{
"aggs": {
"自定义名字": {
"terms": {
"field": "emp_dept.keyword", keyword表示不进行分词
"size": 10
}
}
}
}
在聚合基础上求平均值并且进行排序:
GET /indices/Types/_search
{
"aggs": {
"自定义名字": {
"terms": {
"field": "emp_dept.keyword",
"size": 10,
"order": {
"avg_score": "desc"
}
},
"aggs": {
"avg_score": {
"avg": {
"field": "emp_age"
}
}
}
}
}
}
获取数据字段的数据类型
GET /indices/_mapping/Types
PUT /indices的时候可以指定mapping 在配置了中文分词后可以选择分词库
分词器:中文分词 扩展辞典 远程词典 停止词典
7.x的es慢慢废弃types了 可以不写 不写默认是_doc
总结:
query match 匹配是否包含
from size分页
bool 使用and or must mustnot操作
想查询同个字段的多个条件 直接空格即可 不要bool
filter 过滤 查询区间
term 直接查询精确的 并且通过倒排索引指定的词条进行精确查找
match 会使用分词器解析
**
elasticsearch内部管理集群的方式
**
一个或者多个节点组成一个集群 具有相同的cluster。name
我们访问的节点负责收集各节点返回的数据 ,最后一起返回给客户端
集群健康度:
green 所有主要分片和复制分片都可用
yellow 所有主要分片可用 但不是所有复制分片可用
red 不是所有主要分片可用
底层是按照分片存储的,当有更多节点的时候 主分片会进行复制分片
下图配置了3个主分片并且每个主分片各有一个复制分片
```
对比solar
1对单纯的对已有的数据进行搜索的时候 solar更快
2建立索引后 solar会产生io阻塞 查询性能差 使用es更好
3数据量变大的时候 solar搜索效率就变低了 es没明显变化 更适合大数据
和关系型数据库的对比 面向文档! 索引和搜索的最小单位就是文档!就是一条条数据
es在后台把每个索引划分成多个分片 每个分片在集群中的不同服务器间迁移
一个es索引库是由多个lucene倒排索引构成的 所以是把lucene索引的功能并且进行聚合

ik分词器
中文分词器
ik_smart 做最粗粒度的划分
ik_max_word 穷尽所有的可能
可以配置自己的dic进行分词
通过命令查看信息
获取健康值
GET _cat/health GET _Cat命令可以获得很多信息
查看索引库
GET _cat/indices?v
锁
可以通过es的更新命令 更改了version 去充当乐观锁

















 3044
3044

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









