







 本文详细记录了在Windows 10系统下,使用Anaconda安装gensim和word2vec过程中遇到的兼容性问题及解决方案。作者分享了如何正确安装gensim、numpy、scipy等库,并提供了下载特定版本whl文件的网站链接。
本文详细记录了在Windows 10系统下,使用Anaconda安装gensim和word2vec过程中遇到的兼容性问题及解决方案。作者分享了如何正确安装gensim、numpy、scipy等库,并提供了下载特定版本whl文件的网站链接。
关于anaconda安装gensim和word2vec过程报错问题经验小谈
环境:window10 64位 python3.7 anaconda最新版
1、下载安装anaconda,可以去官网下载:
https://www.anaconda.com/distribution/#download-section
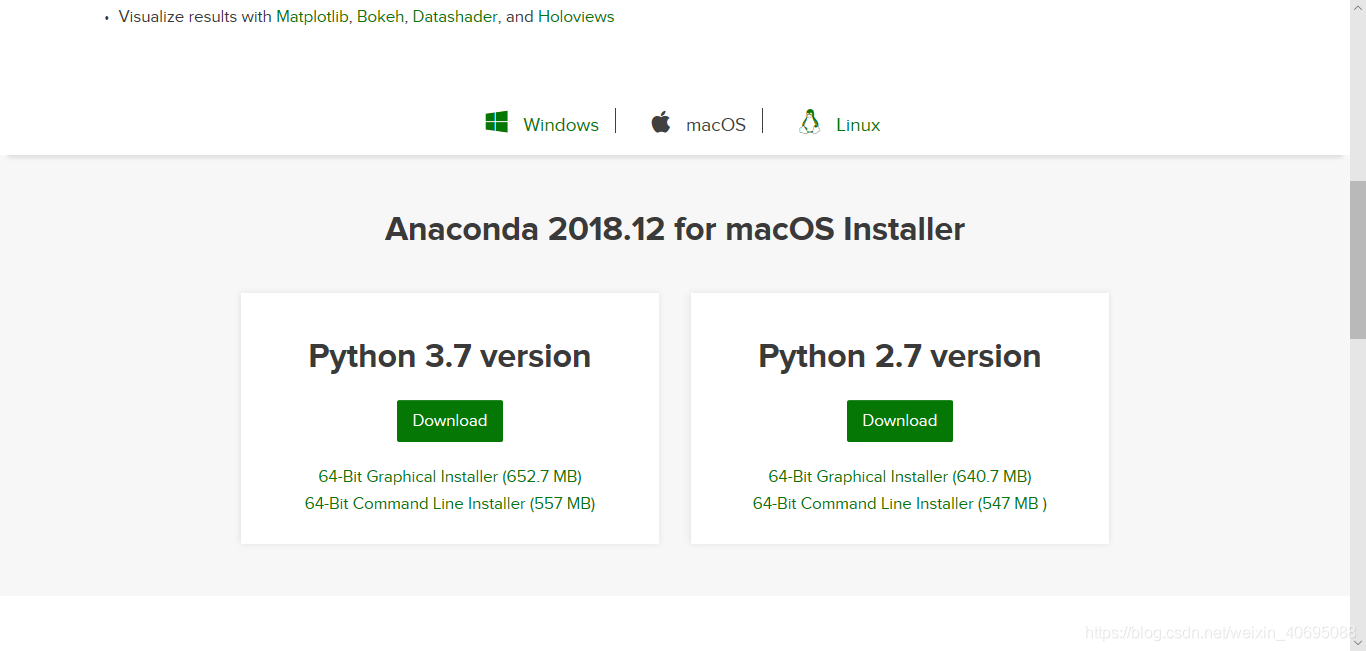
有Mac,window,和Linux三种系统的,python3.7和2.7的,根据自己电脑的系统
和python的版本选择安装。
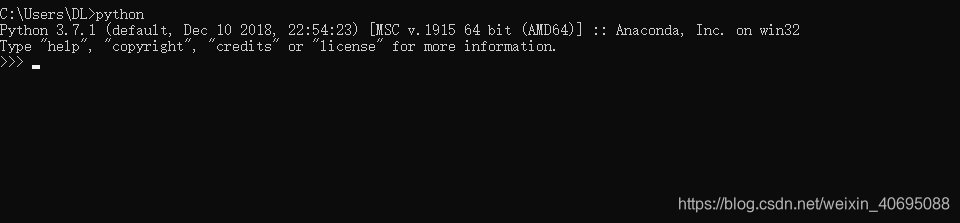
如果在cmd窗口下输入python命令提示类似下方的图片则证明安装成功
2.1安装gensim
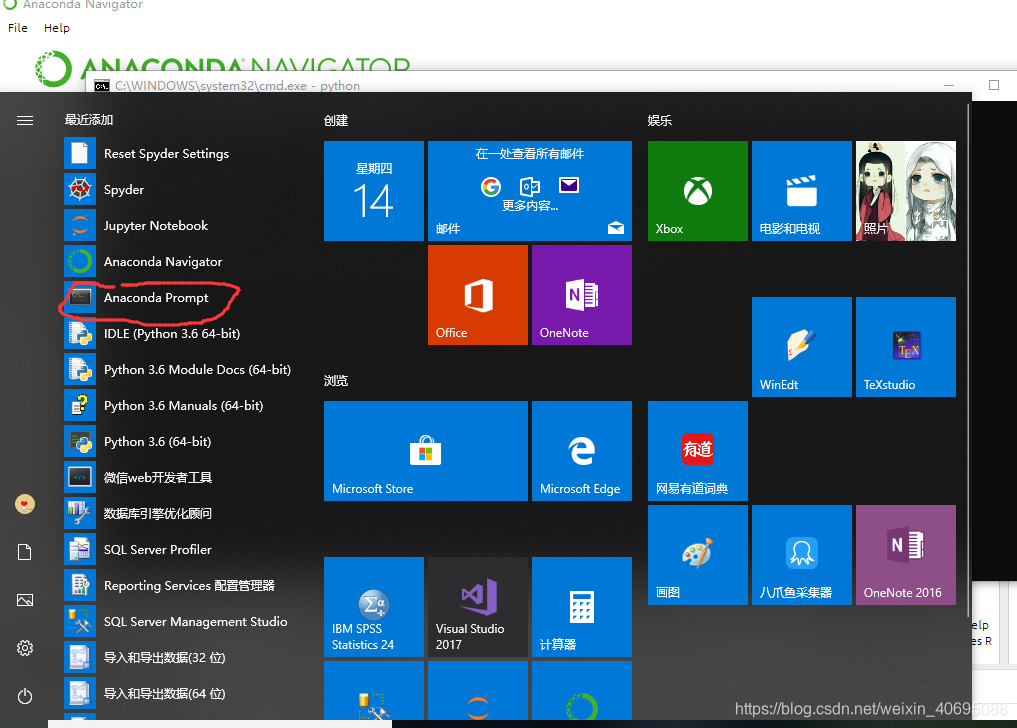
找到anaconda prompt(划红色圈的东东)
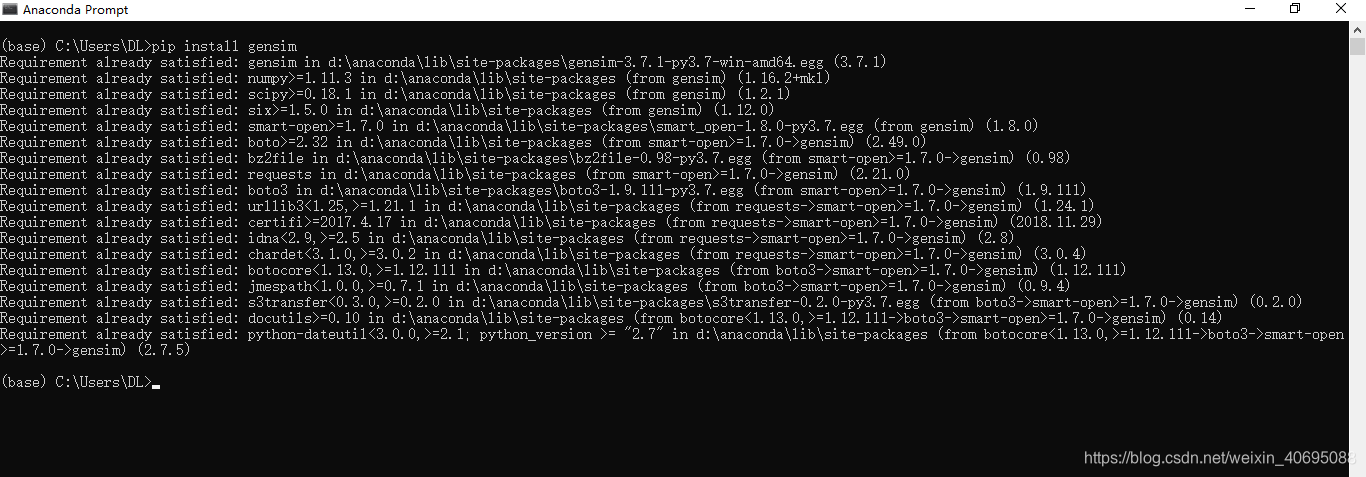
直接输入pip install gensim 命令,等待安装,我之前是安装成功过了,所以页面显
示是这样的
与此同时需要安装numpy和scipy这两个库,安装命令是一样的,pip install XXX
当窗口提示安装完成后,在jupyter notebook里输入import gensim,提示错误消息
是“ImportError: No module named gensim.models”,即模块不存在。根据
我找的一些网上的资料,这是因为gensim、numpy和scipy这三个库的兼容性问
题,所以需要下载满足计算机系统的相应版本的三个库。
2.2解决安装gensim后不能导入模板的问题
首先查看自己电脑的python当前版本支持包格式,还是在anaconda prompt窗口中中敲
入命令
(base) C:\Users\DL>python
>>>import pip
>>>print(pip.pep425tags.get_supported())
有的电脑会报错:
Traceback (most recent call last):
File “”, line 1, in
AttributeError: module ‘pip’ has no attribute ‘pep425tags’
这时可以改用输入以下命令:
(base) C:\Users\DL>python
>>> import pip._internal
>>> print(pip._internal.pep425tags.get_supported())
应该就能够看到以下信息了:
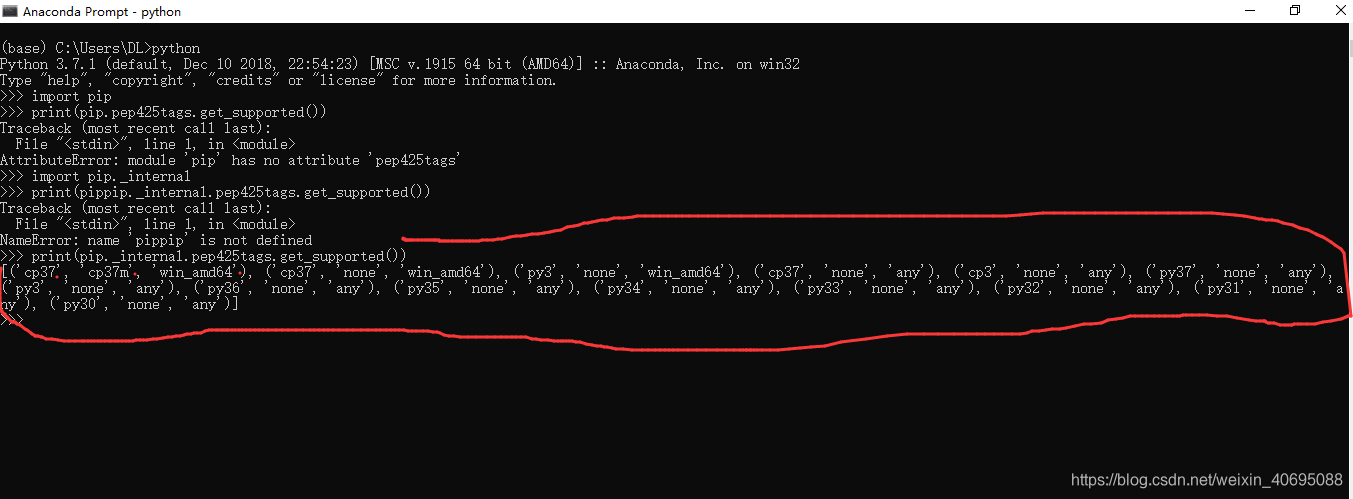
这上面红色圈的就是对应的版本号,例如,我的电脑就可以安装-cp37-cp37m-
win_amd64版本的gensim、numpy+mkl和scipy这三个whl文件。下载这三个库的
网站地址是:
https://www.lfd.uci.edu/~gohlke/pythonlibs/
进去之后会有各种版本的各种库供选择,找到上面这三个库对应的版本下载,这个下载过程很慢,下载网速大概只有10~15KB吧,特别是numpy+mkl/这个文件大概200M左右,建议点击下载后就可以去睡觉了,明早再起来看。

下载之后放到一个文件夹,提前在anaconda prompt中卸载刚刚安装的gensim和
numpy,SciPy三个库,卸载命令为:pip uninstall XXX,注意可以多次重复卸载numpy
这个库,保证import numpy时找不到这个model
下一步是在prompt窗口中cd进入存放刚刚下载的三个whl文件的路径,使用pip install
numpy-1.14.2+mkl-cp36-cp36m-win_amd64.whl wheel(命令根据下载的不同版本文件
名进行调整)安装numpy库,用同样的方法安装SciPy和gensim两个库。安装成功后发
现现在jupyter notebook输入import gensim是不会报错的,但是当我们输入import
word2vec的时候又报错“ImportError: No module named gensim.models”,即模
块不存在。然后就很烦了。
3.安装word2vec
笔者还是耐着性子查找各种资料,有说在python中直接敲pip install word2vec的,但是一直报错,还需要配置C/C++编译环境,然后一直不成功,但是最后却突然找到一个很简单的方法成功了,就是直接在prompt窗口中敲conda install word2vec 竟然成功了。
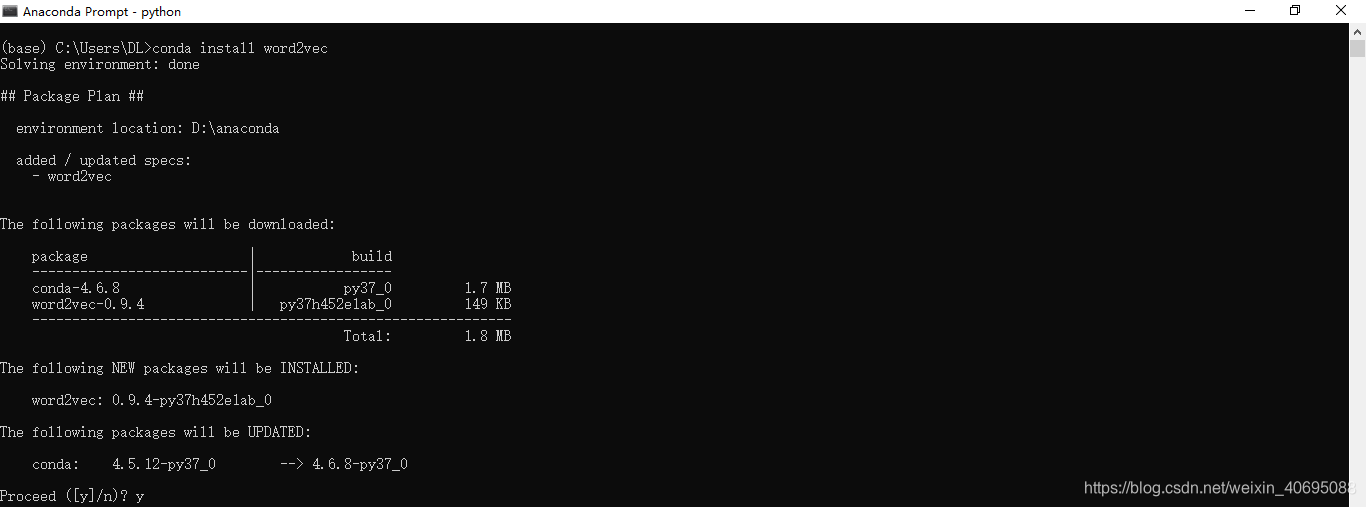
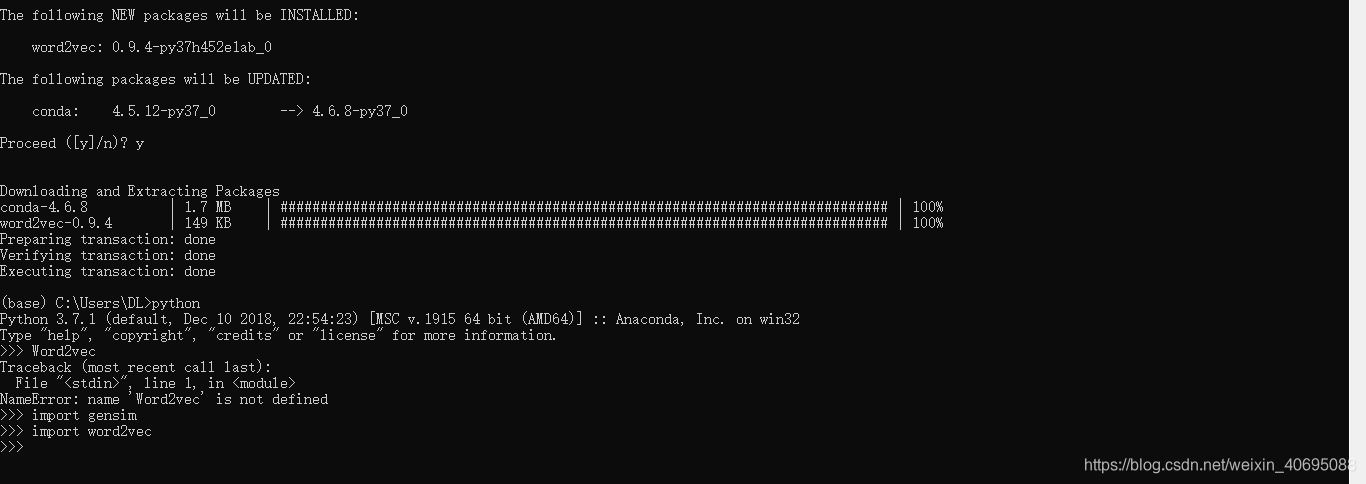
此时在jupyter notebook输入word2vec是没有报错的

第一次安装这个东西,笔者其实对python和anaconda也不是很熟悉,都只能称得上了解一点吧,所以做这个主要还是慢慢钻研,多尝试写办法,会运用网上的各种资料吧,我觉得最最重要的还是要有耐心,我也是弄了将近一周的时间(零散时间)才有了这么点小小经验。嘿嘿!

















 4540
4540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









