







 本文深入探讨Hadoop作为大数据处理框架的核心作用,包括其在海量数据存储与分析计算中的优势,介绍了MapReduce、Hive、HBase、YARN和HDFS等关键组件的功能与架构,以及Hadoop运行环境的搭建步骤。
本文深入探讨Hadoop作为大数据处理框架的核心作用,包括其在海量数据存储与分析计算中的优势,介绍了MapReduce、Hive、HBase、YARN和HDFS等关键组件的功能与架构,以及Hadoop运行环境的搭建步骤。
大数据主要解决海量数据的存储和海量数据的分析计算问题,其特点是大量、高速、多样和低价值密度。Google 是 hadoop 的思想之源:GFS -> HDFS, Map-Reduce -> MR, BigTable -> Hbase。Hadoop 三大发行版本是Apache、Cloudera和Hortonworks
Hadoop生态圈:
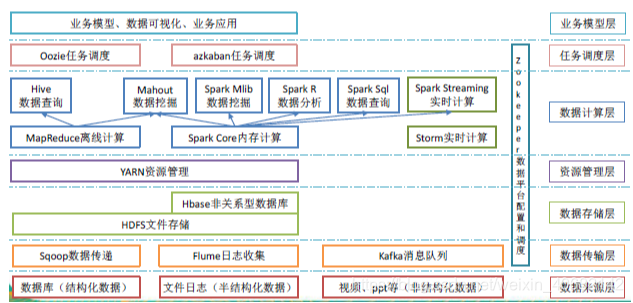
Hadoop 组成:
- MapReduce:一个分布式的离线并行计算框架。
- Hive:针对大数据的查询框架。
- HBase:NoSQL实时/准实时框架。
- YARN:作业调度与集群资源管理的框架。
- HDFS:一个高可靠、高吞吐量的分布式文件存储系统。
HDFS 架构:
- NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的 DataNode 等。
- DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
- Econdary NameNode(2nn):用来监控 HDFS 状态的辅助后台程序,每隔一段时间获取 HDFS 元数据的快照。
YARN 架构:
- ResourceManager(rm):处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度。
- NodeManager(nm):单个节点上的资源管理、处理来自 ResourceManager 的命令、处理来自ApplicationMaster 的命令。
- ApplicationMaster:数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错。
- Container:对任务运行环境的抽象,封装了 CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息。
MapReduce 架构:MapReduce 将计算过程分为两个阶段:Map 和 Reduce,Map 阶段并行处理输入数据,Reduce 阶段对 Map 结果进行汇总。
搭建Hadoop运行环境步骤:
1、创建并克隆虚拟机。
2、设置静态ip和主机名。
3、安装jdk和hadoop。
Hadoop的三种运行模式demo:
1、本地模式
2、伪分布模式
3、完全分布式模式

















 785
785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









