




以往的基于HIN的推荐模型存在两个不足。几乎不学习路径或者元路径的显式表达;只考虑user-item交互,而忽视了元路径与涉及到的user-item pair之间的相互影响。本文是来自KDD 2018的工作,不仅学习user和item的表达,还显式的表示user-item的基于元路径的上下文信息,并且提出co-attention机制来相互促进,改善三者的表达效果。
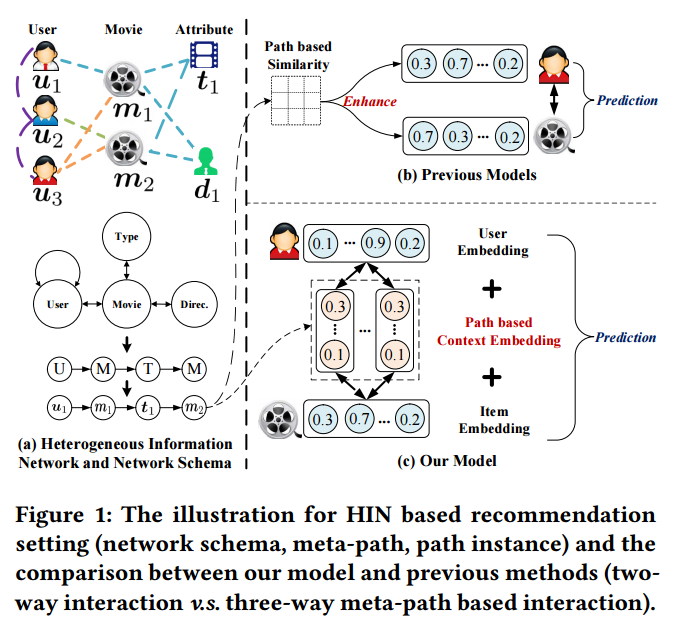
预备知识
隐式反馈:存在n个users U={ u1,...,un}\mathcal{U}=\{u_1,...,u_n\}U={ u1,...,un}和m个items I={ i1,...,im}\mathcal{I}= \{i_1,...,i_m\}I={ i1,...,im},定义隐式反馈矩阵R∈Rn×mR \in \mathbb{R}^{n\times m}R∈Rn×m的元素ru,ir_{u,i}ru,i,代表用户u和物品i之间是否有交互。当ru,i=1r_{u,i}=1r
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1786
1786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









