







 本文介绍了如何运用IV值和随机森林进行特征筛选,以预测贷款用户是否会逾期。首先,阐述了IV值的计算原理和中等IV值的含义。接着,详细解释了随机森林的决策过程,包括样本抽取、决策树生成和预测方法。通过代码实现和模型训练,得出预测结果。
本文介绍了如何运用IV值和随机森林进行特征筛选,以预测贷款用户是否会逾期。首先,阐述了IV值的计算原理和中等IV值的含义。接着,详细解释了随机森林的决策过程,包括样本抽取、决策树生成和预测方法。通过代码实现和模型训练,得出预测结果。
一、学习要求
分别对前面预处理的数据使用IV值和随机森林进行特征筛选
二、基础知识
1、IV值
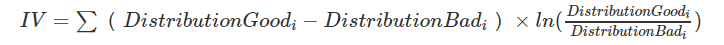
计算过程是根据该特征所命中黑白样本的比率与总黑白样本的比率,来对比和计算其关联程度
IV 值的取值范围是[0, ∞ ),但一般具有中等IV值的变量来进行模型开发,如下所示
| IV值 | 预测能力 |
|---|---|
| <0.02 | 无用 |
| 0.02-0.1 | 弱预测 |
| 0.1-0.3 | 中等预测 |
| 0.3-0.5 | 强预测 |
| >0.5 | 可疑 |
import math
import numpy as np
from scipy import stats
from sklearn.utils.multiclass import type_of_target
def woe(X, y, event=1):
res_woe = []
iv_dict = {}
for feature in X.columns:
x = X[feature].values
# 1) 连续特征离散化
if type_of_target(x) == 'continu 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 575
575

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









