




#创作灵感#
上一篇讲的是基于AnythingLLM搭建的本地知识库,使用几天后,咋说呢,没得意思,豪无智能感,于是决定直接对模型动手微调,再看看效果。
#干货走起#
1,先搞一套python的环境,包括开发工具(我用的是pycharm),环境配置等等。
2,搞个GPU加速工具,没有的直接用CPU,我用的是这个:
3,通过这玩意思,直接创建一个虚拟环境,主要目的是为了区分不同项目的依赖冲突等等,我在这里吃过亏,先是Python3.12版本搞半天,后面发现依赖有问题,于是又搞个3.10版本的,还是冲突,一气之下全删了,再安装3.10,又研究了虚拟环境,后面就顺了。
4,通过DeepSeek,搞一套python训练模型的代码,最好描述清晰一点,对python不是很熟,研究了一下代码,大概看懂了,最主要的是少什么依赖,在虚拟环境下直接安装就行,它提供的代码最终能训练成模型。
有小坑的地方是,如果你提供了多少条数据,num_labels就设置为多少条。
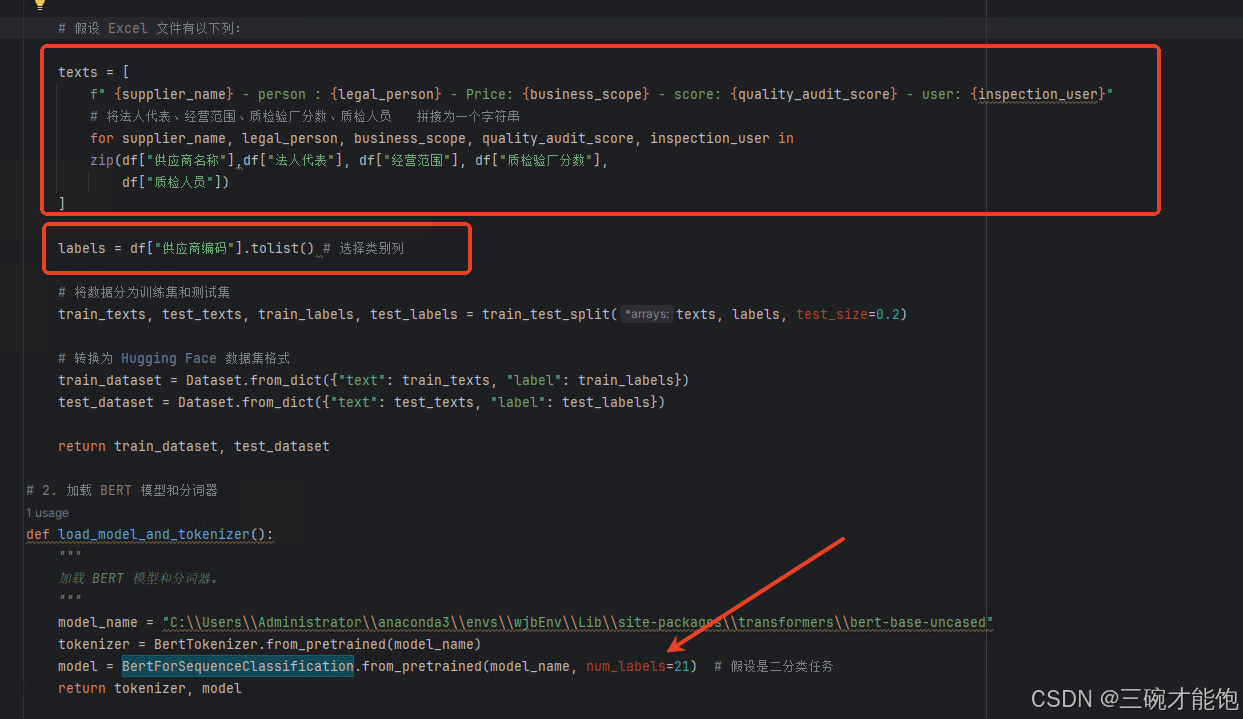
texts和labels是最主要的,训练模型只认这两个参数,但是你有多个字段的话咋搞?
只能拼接起来,看上图。
labels指的是ID一类的意思,最大值不能大于总条数,我是按顺序写的数字,字符不行。
如果你是从数据库导出的文件类型不同,那么python代码就得对应改动,具体请教deepseek就行。
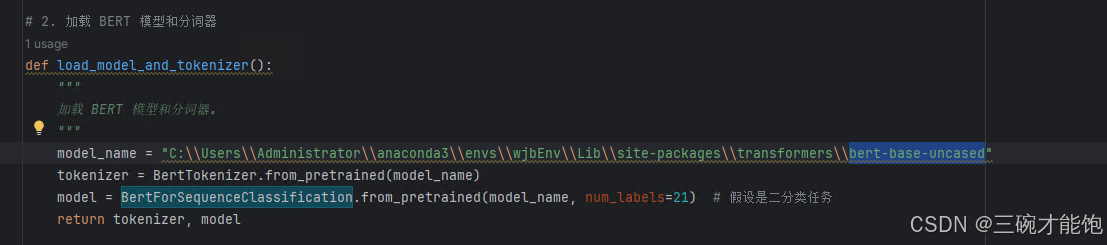
我用的训练模型是BERT,代码运行时找不到什么权重、分词器文件。
主要是国外网站有墙,不好访问。
bert-base-uncased这个东西,找到官网,下载对应的文件到本地。
在你的报错包路径下(也就是lib\site-packages包下),建一个同名文件夹,把文件都放进去,代码里写上绝对路径。
5,模型训练完成生成的是model.safetensors格式的,上传到ollama很麻烦,研究了一下,发现guff格式最简单方便,所以代码还得再转两次。需要使用 llama.cpp 工具将模型转换为 GGUF 格式。
6,登录ollama官网,注册一个账号,把本地ollama的公钥添
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









