




 本文详细介绍了正则表达式的基本概念、语法和在Python中的应用,包括匹配、查找、替换等操作。通过实例展示了如何使用正则表达式进行字符串模糊匹配,并讨论了贪婪与非贪婪模式的区别。同时,提供了实际的代码示例,演示了如何使用正则表达式进行数据替换,以提高代码的效率和灵活性。
本文详细介绍了正则表达式的基本概念、语法和在Python中的应用,包括匹配、查找、替换等操作。通过实例展示了如何使用正则表达式进行字符串模糊匹配,并讨论了贪婪与非贪婪模式的区别。同时,提供了实际的代码示例,演示了如何使用正则表达式进行数据替换,以提高代码的效率和灵活性。
1.什么是正则表达式
正则表达式不是python中的一个概念,而是计算机的一概念,几乎所有的编程语言(java,python等)都支持正则表达式
正则表达式是字符串的模糊匹配技术(基于一个规则去匹配字符串当中的内容)
只要是想在字符串中找符合规律的子字符串,基本上都可以使用正则表达式
2.正则表达式的语法
2.1表示单字符

2.2表示数量

2.正则表达式在python中的应用
re模块,是python的一个标准模块,是不需要安装的,直接导入即可
import re
# pattern表示正则表达式(匹配规则) string表示一个字符串
string = '\n12abc45'
result = re.search(pattern='abc', string=string)
print(result)
# 获取匹配到的子字符串
print(result.group())
result = re.search(pattern='2a', string=string)
print(result)
# .:表示匹配任意字符,\n除外
result = re.search(pattern='.', string=string)
print(result)
# [7a]:表示匹配7或a,找到一个就不管其他符合条件的了
result = re.search(pattern='[7a]', string=string)
print(result)
# \d:表示匹配数字0-9
result = re.search(pattern='\d', string=string)
print(result)
运行结果:
<re.Match object; span=(3, 6), match='abc'>
abc
<re.Match object; span=(2, 4), match='2a'>
<re.Match object; span=(1, 2), match='1'>
<re.Match object; span=(3, 4), match='a'>
<re.Match object; span=(1, 2), match='1'>
span=(3, 6)表示匹配到子字符串的索引位置
match='abc'表示正则表达式的规则,也就是要匹配的子字符串
import re
# *:表示匹配某个字符0次或无限次
# 贪婪模式 VS 非贪婪模式,python默认为贪婪模式
string = 'aa1111'
result = re.search(pattern='1*', string=string)
print(result)
string = '7aabc45'
result = re.search(pattern='7*', string=string)
print(result)
# 非贪婪模式
string = 'aa7aabc45'
result = re.search(pattern='.*?', string=string)
print(result)
# 贪婪模式
result = re.search(pattern='.*', string=string)
print(result)
运行结果:
None
<re.Match object; span=(0, 0), match=''>
<re.Match object; span=(0, 1), match='7'>
<re.Match object; span=(0, 0), match=''>
<re.Match object; span=(0, 9), match='aa7aabc45'>
import re
string = '{"member_id": "#member_id#","amount":# "200"#}'
result = re.search('#.*#', string)
print(result)
# 匹配#member_id#
result = re.search('#(.*?)#', string)
print(result)
# 分组
# result.group()表示正则表达式匹配到的整个结果,默认是0
print(result.group(0))
# result.group(1)表示结果当中第一个括号里面的内容
# result.group(2)表示结果当中第二个括号里面的内容,此处没有第二个会报错
print(result.group(1))
print(result.group(2))
运行结果:

实践演练(正则替换代码):
re.search:每次只找一个匹配到的字符串,找到一个就不管其他的
re.finditer:找到所有匹配到的字符串
import re
string = '{"member_id": "#member_id#","amount":#money#}'
class Data:
member_id = '1234'
money = 1000
# 方法一:if判断
if '#member_id#' in string:
string = string.replace('#member_id#', Data.member_id)
if '#money#' in string:
string = string.replace('#money#', str(Data.money))
print(string)
# 方法二:正则表达式re.finditer,匹配所有符合规则的字符串
result = re.finditer('#(.*?)#', string)
for i in result:
# i是匹配到的每个数据
old = i.group() # #member_id#
new = i.group(1) # member_id
string = string.replace(old, str(getattr(Data, new)))
print(string)
运行结果:
{"member_id": "1234","amount":1000}
{"member_id": "1234","amount":1000}
注意:
- money是数值类型,所以使用replace替换时,一定要注意str()转换
- getattr(类名称,'属性名') 因为new正好是字符串,所以属性名不需要再加引号包裹
总结:
从结果中可以看到两种方法的结果是一样的,但当需要替换的内容较多时,使用方法二就比较方便
封装代码:
import re
class Data:
member_id = '1234'
money = 1000
def replace_data(string):
result = re.finditer('#(.*?)#', string)
for i in result:
# i是匹配到的每个数据
old = i.group() # #member_id#
new = i.group(1) # member_id
string = string.replace(old, str(getattr(Data, new)))
return string
if __name__ == '__main__':
string = '{"member_id": "#member_id#","amount":#money#}'
result = replace_data(string)
print(result)
注意:如果想替换token,那就必须要在Data类里添加token同名类属性,不然会报错,不想报错可以把这行代码修改为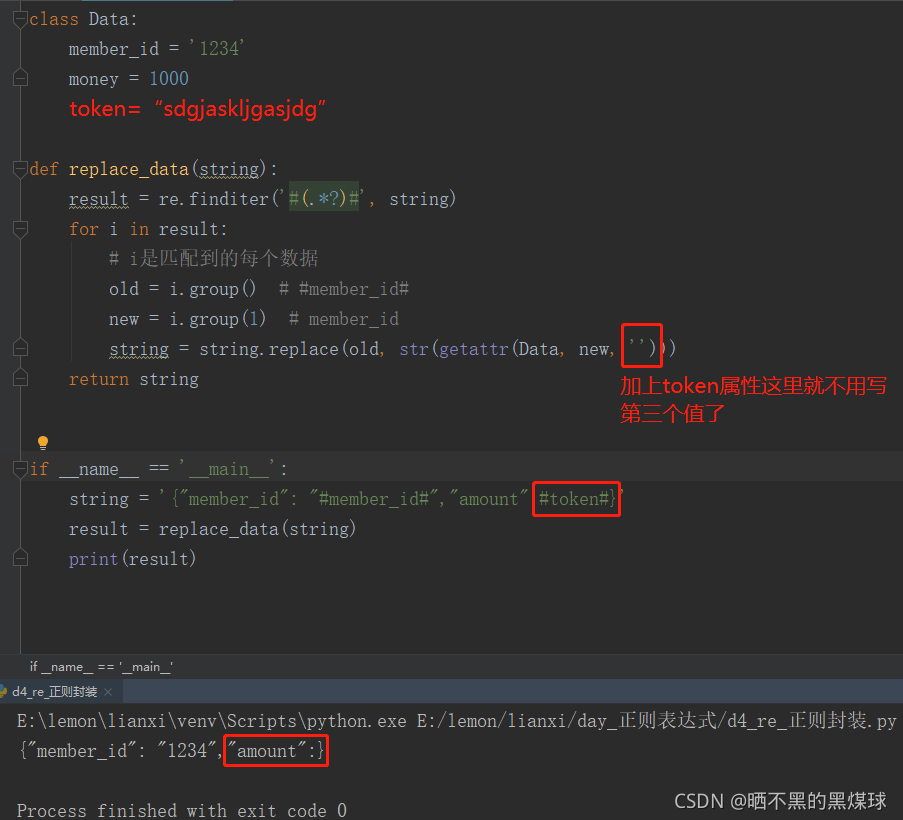

















 1026
1026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









