







 本文介绍了Python的模块和标准库,包括如何定义和使用模块,如何添加测试代码,以及包的概念。详细讲解了sys、os、fileinput等常用标准库,并提供了使用示例。同时,文章还涉及堆、双端队列、time、random、shelve和re模块的使用方法,帮助读者更好地理解和利用Python的标准库。
本文介绍了Python的模块和标准库,包括如何定义和使用模块,如何添加测试代码,以及包的概念。详细讲解了sys、os、fileinput等常用标准库,并提供了使用示例。同时,文章还涉及堆、双端队列、time、random、shelve和re模块的使用方法,帮助读者更好地理解和利用Python的标准库。
模块
Python不仅语言核心非常强大,还提供了很多标准库的模块以供使用,当然不仅可以使用官方模块还可以编写自己的模块
模块即是程序,任何Python程序都可以作为模块导入,我们需要讲模块导入正确的位置让python解释器去查找
查看当前path的目录列表并导入想要增加的目录:
>>> import sys,pprint
>>> pprint.pprint(sys.path)
['',
'F:\\anaconda\\python36.zip',
'F:\\anaconda\\DLLs',
'F:\\anaconda\\lib',
'F:\\anaconda',
'C:\\Users\\E6600\\AppData\\Roaming\\Python\\Python36\\site-packages',
'F:\\anaconda\\lib\\site-packages',
'F:\\anaconda\\lib\\site-packages\\Babel-2.5.0-py3.6.egg',
'F:\\anaconda\\lib\\site-packages\\setuptools-41.0.1-py3.6.egg',
'F:\\anaconda\\lib\\site-packages\\robotframework-3.1.2-py3.6.egg',
'F:\\anaconda\\lib\\site-packages\\win32',
'F:\\anaconda\\lib\\site-packages\\win32\\lib',
'F:\\anaconda\\lib\\site-packages\\Pythonwin',
'C:/python',
'D:/python',
'D:\\python']
>>> sys.path.append('E:/python')除使用环境变量PYTHONPATH外,还可使用路径配置文件。这些文件的扩展名为.pth,位于一些特殊目录中,包含要添加到sys.path中的目录。有关这方面的详细信息,请参阅有关模块site的标准库文档
编写一个简单的模块hello.py文件,我放在D盘python的目录下面
print("Hello,world!")然后在解释器里面加入保存这个模块的地址,然后导入模块
>>> import sys
>>> sys.path.append('D:\python')
>>> import hello
Hello,world!
>>> import hello
>>> import importlib
>>> hello=importlib.reload(hello)
Hello,world!注意:头一次导入模块时会执行这个模块的代码,再次导入则不会执行,因为模块是用来定义的不是来执行操作的
如果想重新加载函数可使用模块importlib中的函数reload,它接受一个参数(要重新加载的模块),并返回重新加载的模块
在模块中定义函数
编写一个hello2.py文件,还是放在python目录下面
def hello():
print("Hello,world!")然后导入并执行这个模块:
>>> import hello2
>>> hello2.hello()
Hello,world!采用这种方式就可以重用代码,通过放在模块中,可以在多个程序中使用他们
添加测试代码
添加hello3.py文件:
def hello():
print("Hello,world!")
hello()导入并执行:
>>> import hello3
Hello,world!
>>> hello3.hello()
Hello,world!
>>>如果在程序中作为模块导入执行的话也会执行测试代码,所以要避免这种行为,需要使用变量__name__
一个包含有条件执行的测试代码模块
编写一个hello4.py文件
def hello():
print("Hello,world!")
def test():
hello()
if __name__=='__main__':test()导入并执行:
>>> import hello4
>>> hello4.hello()
Hello,world!
>>> hello4.test()
Hello,world!包
包其实是另一种模块,也可包含其他模块,模块存储在扩展名为.py的文件中,而包则是一个目录。
作为包,目录里面必须含有文件__init__.py
比如有个名为bag的包,里面的文件__init__.py包含语句v1=1
那么我们需要这样处理:
import bag
print(bag.v1)查找模块源代码使用特性__file__
>>> print(hello.__file__)
D:/python\hello.py常用标准库
1、sys
能够访问与Python解释器紧密相关的变量和函数
| 函数/变量 | 命令行参数,包括脚本名 |
| exit([arg]) | 退出当前程序,可通过可选参数指定返回值或错误消息 |
| modules | 一个字典,将模块名映射到加载的模块 |
| path | 一个列表,包含要在其中查找模块的目录的名称 |
| platform | 一个平台标识符,如sunos5或win32 |
| stdin | 标准输入流——一个类似于文件的对象 |
| stdout | 标准输出流——一个类似于文件的对象 |
| stderr | 标准错误流——一个类似于文件的对象 |
2、os
可通过模块os访问多个操作系统服务
| 函数/变量 | 描述 |
|---|---|
| environ | 包含环境变量的映射 |
| system(command) | 在子shell中执行操作系统命令 |
| sep | 路径中使用的分隔符 |
| pathsep | 分隔不同路径的分隔符 |
| linesep | 行分隔符('\n'、'\r'或'\r\n') |
| urandom(n) | 返回n个字节的强加密随机数据 |
3、fileinput
迭代一系列文本文件中所有的行
| 函数 | 描述 |
|---|---|
| input([files[, inplace[, backup]]]) | 帮助迭代多个输入流中的行 |
| filename() | 返回当前文件的名称 |
| lineno() | 返回(累计的)当前行号 |
| filelineno() | 返回在当前文件中的行号 |
| isfirstline() | 检查当前行是否是文件中的第一行 |
| isstdin() | 检查最后一行是否来自sys.stdin |
| nextfile() | 关闭当前文件并移到下一个文件 |
| close() | 关闭序列 |
fileinput.input是其中最重要的函数,它返回一个可在for循环中进行迭代的对象。如果要覆盖默认行为(确定要迭代哪些文件),可以序列的方式向这个函数提供一个或多个文件名。还可将参数inplace设置为True(inplace=True),这样将就地进行处理。对于你访问的每一行,都需打印出替代内容,这些内容将被写回到当前输入文件中。就地进行处理时,可选参数backup用于给从原始文件创建的备份文件指定扩展名。
函数fileinput.filename返回当前文件(即当前处理的行所属文件)的文件名。
函数fileinput.lineno返回当前行的编号。这个值是累计的,因此处理完一个文件并接着处理下一个文件时,不会重置行号,而是从前一个文件最后一行的行号加1开始。
函数fileinput.filelineno返回当前行在当前文件中的行号。每次处理完一个文件并接着处理下一个文件时,将重置这个行号并从1重新开始。
函数fileinput.isfirstline在当前行为当前文件中的第一行时返回True,否则返回False。
函数fileinput.isstdin在当前文件为sys.stdin时返回True,否则返回False。
函数fileinput.nextfile关闭当前文件并跳到下一个文件,且计数时忽略跳过的行。这在你知道无需继续处理当前文件时很有用。例如,如果每个文件包含的单词都是按顺序排列的,而你要查找特定的单词,则过了这个单词所在的位置后,就可放心地跳到下一个文件。
函数fileinput.close关闭整个文件链并结束迭代。
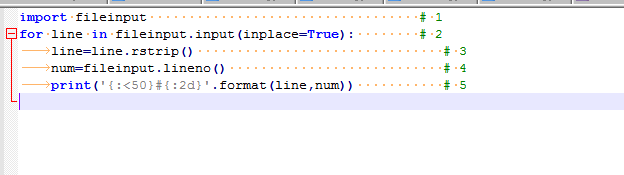
举例:在脚本后面添加行号,新增test1.py文件
import fileinput
for line in fileinput.input(inplace=True):
line=line.rstrip()
num=fileinput.lineno()
print('{:<50}#{:2d}'.format(line,num))然后在命令行运行这个程序
C:\Users\E6600>python test1.py test1.py运行后结果:
注意:谨慎使用inplace参数,很容易破坏文件
堆
另一种著名的数据结构是堆(heap),它是一种优先队列。优先队列让你能够以任意顺序添加对象,并随时(可能是在两次添加对象之间)找出(并删除)最小的元素。相比于列表方法min,这样做的效率要高得多。
python只有一个包含一堆操作函数的模块heapq
| 函数 | 描述 |
|---|---|
| heappush(heap, x) | 将x压入堆中 |
| heappop(heap) | 从堆中弹出最小的元素 |
| heapify(heap) | 让列表具备堆特征 |
| heapreplace(heap, x) | 弹出最小的元素,并将x压入堆中 |
| nlargest(n, iter) | 返回iter中n个最大的元素 |
| nsmallest(n, iter) | 返回iter中n个最小的元素 |
函数heappush用于在堆中添加一个元素。请注意,不能将它用于普通列表,而只能用于使用各种堆函数创建的列表
>>> from heapq import *
>>> from random import shuffle
>>> data=list(range(10))
>>> shuffle(data)
>>> heap=[]
>>> for n in data:
... heappush(heap,n)
...
>>> heap
[0, 3, 1, 4, 6, 7, 2, 9, 5, 8]
>>> heappush(heap,0.5)
>>> heap
[0, 0.5, 1, 4, 3, 7, 2, 9, 5, 8, 6]堆特征:位置i处的元素总是小于位置2 * i和2 * i + 1处的元素
双端队列
按添加元素的顺序进行删除时使用双端队列,模块collections包含类型deque以及其他几个集合类型
同集合一样,双端队列也是由可迭代对象创建
>>> from collections import deque
>>> d=deque(range(8))
>>> d.append(8)
>>> d
deque([0, 1, 2, 3, 4, 5, 6, 7, 8])
>>> d.pop()
8
>>> d.popleft()
0
>>> d.rotate(2)
>>> d
deque([6, 7, 1, 2, 3, 4, 5])
>>> d.rotate(-1)
>>> d
deque([7, 1, 2, 3, 4, 5, 6])time
| 索引 | 字段 | 值 |
|---|---|---|
| 0 | 年 | 2000、2019 |
| 1 | 月 | 1-12 |
| 2 | 日 | 1-31 |
| 3 | 时 | 0-23 |
| 4 | 分 | 0-59 |
| 5 | 秒 | 0-61 |
| 6 | 星期 | 0-6 |
| 7 | 儒略历 | 1-366 |
| 8 | 夏令时 | 0、1、-1 |
| 函数
| 描述 |
|---|---|
| asctime([tuple]) | 将时间元组转换为字符串 |
| localtime([secs]) | 将秒数转换为表示当地时间的日期元组 |
| mktime(tuple) | 将时间元组转换为当地时间 |
| sleep(secs) | 休眠(什么都不做)secs秒 |
| strptime(string[, format]) | 将字符串转换为时间元组 |
| time() | 当前时间(从新纪元开始后的秒数,以UTC为准) |
使用举例:
>>> import time
>>> t=(2019,9,1,16,25,20,1,45,0)
>>> secs=time.mktime(t)
>>> time.mktime(t)
1567326320.0
>>> time.asctime(time.localtime(secs))
'Sun Sep 1 16:25:20 2019'random
模块random包含生成伪随机数的函数,有助于编写模拟程序或生成随机输出的程序
| 函数 | 描述 |
|---|---|
| random() | 返回一个0~1(含)的随机实数 |
| getrandbits(n) | 以长整数方式返回n个随机的二进制位 |
| uniform(a, b) | 返回一个a~b(含)的随机实数 |
| randrange([start], stop, [step]) | 从range(start, stop, step)中随机地选择一个数 |
| choice(seq) | 从序列seq中随机地选择一个元素 |
| shuffle(seq[, random]) | 就地打乱序列seq |
| sample(seq, n) | 从序列seq中随机地选择n个值不同的元素 |
shelve
shelve可以简单的存储数据,如果要正确的使用模块shelve存储对象,必须将获取的副本赋给一个临时变量,并在修改副本后再次存储:
>>> import shelve
>>> s=shelve.open('test.txt')
>>> s['x']=[1,2,3]
>>> s['x'].append(4)
>>> s['x']
[1, 2, 3]
>>> temp=s['x']
>>> temp.append(4)
>>> s['x']=temp
>>> s['x']
[1, 2, 3, 4]re
通配符
句点:与除换行符外的任何字符都匹配,句点只与一个字符匹配,零个和两个都不匹配
对特殊字符进行转义
比如匹配字符串’www.abc.com‘,就不可以直接使用,需要在前面加上一个反斜杠,但是一个反斜杠解释器又会对这个反斜杠进行转义所以要使用两个反斜杠‘www\\.abc\\.com’
还有一种方式是使用原始字符串,比如r‘www.abc.com’
字符集
[abcd]you与ayou、byou、cyou、dyou都匹配
[a-z]与a~z的任何字母都匹配
[a-zA-Z0-9]与大写字母、小写字母和数字都匹配
[^abc]匹配除abc以外的任何字符
字符集只能匹配一个字符
二选一和子模式
二选一采用管道字符(|)
‘hello|hi’
子模式的表达方式为‘h(ello|i)’
可选模式和重复模式
通过在子模式后面加上问号
比如:r'(http://)?(www\.)?python\.org'
只与下面这些字符串匹配:
'http://www.python.org'
'http://python.org'
'www.python.org'
'python.org'
字符串的开头和末尾
到目前为止,讨论的都是模式是否与整个字符串匹配,但也可查找与模式匹配的子串,
如字符串'www.python.org'中的子串'www'与模式'w+'匹配。像这样查找字符串时,有时在整个字符串开头或末尾查找很有用。
例如,你可能想确定字符串的开头是否与模式'ht+p'匹配,为此可使用脱字符('^')来指出这一点。
例如,'^ht+p'与'http://python.org'和'htttttp://python.org'匹配,但与'www.http.org'不匹配。同样,要指定字符串末尾,可使用美元符号($)。
| 函数 | 描述 |
|---|---|
| compile(pattern[, flags])
| 根据包含正则表达式的字符串创建模式对象 |
| search(pattern, string[, flags]) | 在字符串中查找模式 |
| match(pattern, string[, flags]) | 在字符串开头匹配模式 |
| split(pattern, string[, maxsplit=0]) | 根据模式来分割字符串,maxsplit指定最多分割多少次 |
| findall(pattern, string) | 返回一个列表,其中包含字符串中所有与模式匹配的子串 |
| sub(pat, repl, string[, count=0]) | 将字符串中与模式pat匹配的子串都替换为repl |
| escape(string) | 对字符串中所有的正则表达式特殊字符都进行转义 |
匹配对象和编组
| 方法 | 描述 |
|---|---|
| group([group1, ...])
| 获取与给定子模式(编组)匹配的子串 |
| start([group]) | 返回与给定编组匹配的子串的起始位置 |
| end([group]) | 返回与给定编组匹配的子串的终止位置(与切片一样,不包含终止位置) |
| span([group]) | 返回与给定编组匹配的子串的起始和终止位置 |
>>> import re
>>> m=re.match(r'www\.(.*)\..{3}', 'www.python.org')
>>> m.group(1)
'python'
>>> m.start(1)
4
>>> m.end(1)
10
>>> m.span(1)
(4, 10)注意 除整个模式(编组0)外,最多还可以有99个编组,编号为1~99。
一些其他的标准模块
argparse:在UNIX中,运行命令行程序时常常需要指定各种选项(开关),Python解释器就是这样的典范。这些选项都包含在sys.argv中,但要正确地处理它们绝非容易。模块argparse使得提供功能齐备的命令行界面易如反掌。
cmd:这个模块让你能够编写类似于Python交互式解释器的命令行解释器。你可定义命令,让用户能够在提示符下执行它们。或许可使用这个模块为你编写的程序提供用户界面?
csv:CSV指的是逗号分隔的值(comma-seperated values),很多应用程序(如很多电子表格程序和数据库程序)都使用这种简单格式来存储表格数据。这种格式主要用于在不同的程序之间交换数据。模块csv让你能够轻松地读写CSV文件,它还以非常透明的方式处理CSV格式的一些棘手部分。
datetime:如果模块time不能满足你的时间跟踪需求,模块datetime很可能能够满足。datetime支持特殊的日期和时间对象,并让你能够以各种方式创建和合并这些对象。相比于模块time,模块datetime的接口在很多方面都更加直观。
difflib:这个库让你能够确定两个序列的相似程度,还让你能够从很多序列中找出与指定序列最为相似的序列。例如,可使用difflib来创建简单的搜索程序。
enum:枚举类型是一种只有少数几个可能取值的类型。很多语言都内置了这样的类型,如果你在使用Python时需要这样的类型,模块enum可提供极大的帮助。
functools:这个模块提供的功能是,让你能够在调用函数时只提供部分参数(部分求值,partial evaluation),以后再填充其他的参数。在Python 3.0中,这个模块包含filter和reduce。
hashlib:使用这个模块可计算字符串的小型“签名”(数)。计算两个不同字符串的签名时,几乎可以肯定得到的两个签名是不同的。你可使用它来计算大型文本文件的签名,这个模块在加密和安全领域有很多用途。
itertools:包含大量用于创建和合并迭代器(或其他可迭代对象)的工具,其中包括可以串接可迭代对象、创建返回无限连续整数的迭代器(类似于range,但没有上限)、反复遍历可迭代对象以及具有其他作用的函数。
logging:使用print语句来确定程序中发生的情况很有用。要避免跟踪时出现大量调试输出,可将这些信息写入日志文件中。这个模块提供了一系列标准工具,可用于管理一个或多个中央日志,它还支持多种优先级不同的日志消息。
statistics:计算一组数的平均值并不那么难,但是要正确地获得中位数,以确定总体标准偏差和样本标准偏差之间的差别,即便对于偶数个元素来说,也需要费点心思。在这种情况下,不要手工计算,而应使用模块statistics!
timeit、profile和trace:模块timeit(和配套的命令行脚本)是一个测量代码段执行时间的工具。这个模块暗藏玄机,度量性能时你可能应该使用它而不是模块time。模块profile(和配套模块pstats)可用于对代码段的效率进行更全面的分析。模块trace可帮助你进行覆盖率分析(即代码的哪些部分执行了,哪些部分没有执行),这在编写测试代码时很有用。
总结
模块:模块基本上是一个子程序,主要作用是定义函数、类和变量等。模块包含测试代码时,应将这些代码放在一条检查name == '__main__'的if语句中。如果模块位于环境变量PYTHONPATH包含的目录中,就可直接导入它;要导入存储在文件foo.py中的模块,可使用语句import foo。
包:包不过是包含其他模块的模块。包是使用包含文件__init__.py的目录实现的。
探索模块:在交互式解释器中导入模块后,就可以众多不同的方式对其进行探索,其中包括使用dir、查看变量__all__以及使用函数help。文档和源代码也是获取信息和洞见的极佳来源。
标准库:Python自带多个模块,统称为标准库。
sys:这个模块让你能够访问多个与Python解释器关系紧密的变量和函数。
os:这个模块让你能够访问多个与操作系统关系紧密的变量和函数。
fileinput:这个模块让你能够轻松地迭代多个文件或流的内容行。
sets、heapq和deque:这三个模块提供了三种很有用的数据结构。内置类型set也实现了集合。
time:这个模块让你能够获取当前时间、操作时间和日期以及设置它们的格式。
random:这个模块包含用于生成随机数,从序列中随机地选择元素,以及打乱列表中元素的函数。
shelve:这个模块用于创建永久性映射,其内容存储在使用给定文件名的数据库中。
re:支持正则表达式的模块。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









