







7. 序列共有特性
字符串,列表,元祖统称序列,是可以顺序访问的;他们的关系和共有特性如下:
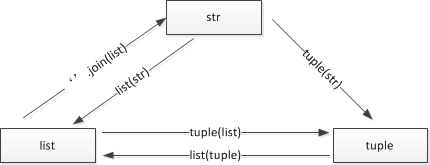
1)相互转换
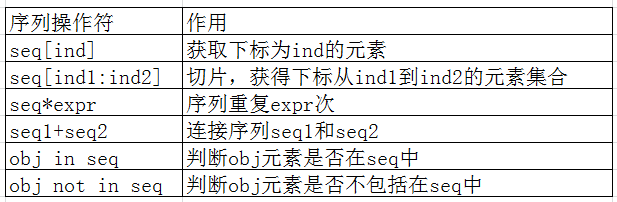
2)序列操作符
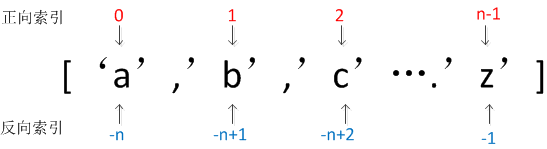
a)根据索引取值,可以正向索引,也可以反向索引


li = [1,2,3,4] res = li[0] #结果为1 res = li[-1] #结果为4 li[1] = ['a'] #结果li = [1,'a',3,4]
b)切片
seq[ind1:ind2:step],原则是顾头不顾尾

li = [1,2,3,4] res = li[:] #结果为[1, 2, 3, 4] res = li[1:] #结果为[2,3,4] res = li[:-2] #结果为[1,2] res = li[1:3] #结果为[2,3] res = li[::2] #取索引值为偶数的元素[1,3],对应的li[1::2]为取索引值为基数的元素 res = li[::-1] #步进为-1,结果为[4, 3, 2, 1] res = li[-1:-3:-1] #结果为[4,3] res = li[3:1:-1] #结果为[4,3] res = li[1:1] #结果为[] li[1:2] = ['a','b'] #结果li = [1, 'a', 'b', 3, 4] li[1:1] = [9] #结果li = [1, 9, 'a', 'b', 3, 4],相当于插入
注意序列不能读写不存在的索引值,但是切片可以
li = [1,2,3] li[9] #报IndexError li[1:9] #结果为[2,3] li[8:9] = [9] #结果为[1,2,3,9]
c)重复操作符*
[1]*3 #结果为[1,1,1] [1,2,3]*3 #结果为[1, 2, 3, 1, 2, 3, 1, 2, 3]
d)连接操作符+
[1,2,3]+[4,5,6] 结果为 [1, 2, 3, 4, 5, 6]
e)成员关系操作符in, no in
li = [1,2,3] 1 in li #结果为True 4 not in li #结果为True
f)删除序列对象,元素关键字del
l = [1,2,3] del l[0] #结果l为[2,3] del l #结果访问l后,报NameError
3)可操作内建函数
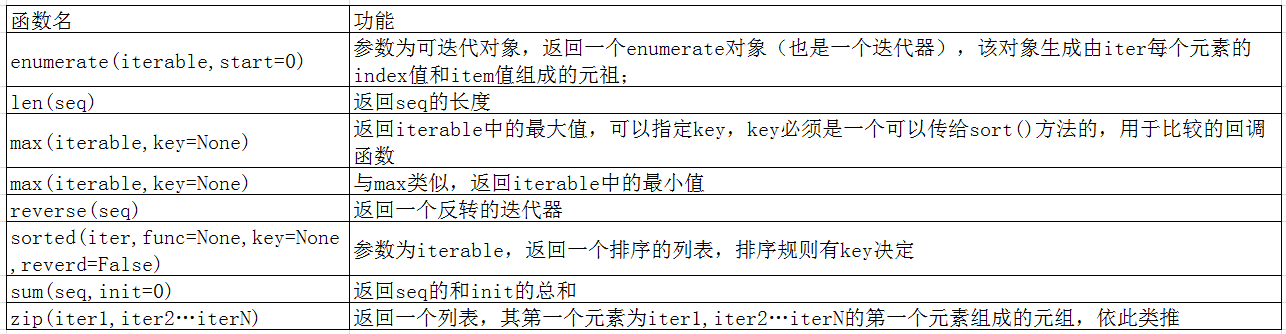
1 #enumerate,枚举 2 li = ['a','b','c'] 3 for item in enumerate(li): 4 print(item) 5 ''' 6 结果为: 7 (0, 'a') 8 (1, 'b') 9 (2, 'c') 10 ''' 11 for item in enumerate(li,5): 12 print(item) 13 ''' 14 结果为: 15 (5, 'a') 16 (6, 'b') 17 (7, 'c') 18 ''' 19 20 21 #len 22 len([1,2,3]) #结果为3 23 len([[1,2],[3,4]]) #结果为2 24 25 26 #max, min 27 max([1,2,3]) #结果为3 28 min([1,2,3]) #结果为1 29 30 31 #sorted,注意与list.sort()方法的区别 32 li = [[1,4],[2,3],[3,2]] 33 res = sorted(li, key=lambda x:x[1]) #结果res为[[3, 2], [2, 3], [1, 4]] 34 35 36 #zip,和倒置有点像 37 l1 = [1,2,3] 38 l2 = [1,2,3] 39 for item in zip(l1,l2): 40 print(item) 41 ''' 42 结果为: 43 (1, 1) 44 (2, 2) 45 (3, 3) 46 ''' 47 l1 = [1,2,3] 48 l2 = [1,2] 49 for item in zip(l1,l2): 50 print(item) 51 ''' 52 结果为: 53 (1, 1) 54 (2, 2) 55 '''
8. 字典
字典是Python语言中唯一的映射类型。映射对象类型里哈希值(键,key)和指向的对象(值,value)是一对多的关系;
特性:
a)字典是无序的可变的容器类型
b)字典的键是唯一的,且必须是不可变类型,如果是元组,要求元组的元素也不可变(因为值的内存地址与键的哈希值有关)
1)创建字典
1 #直接创建
2 d = {
3 'name':'winter',
4 'age':18,
5 'hobbies':['basketball','football']
6 }
7
8 #通过dict函数创建,参数为可迭代对象,字典或列表组成的任意形式;[(),()]或((),())或([],[])或[[],[]]或使用dict(zip())
9 d = dict([('name', 'winter'),
10 ('age',18),
11 ('hobbies',['basketball','football'])]) #结果为{'age': 18, 'hobbies': ['basketball', 'football'], 'name': 'winter'}
12
13 #通过字典推导式
14 d = {x:y for x, y in zip(['name','age','hobbies'],['winter',18,['basketball','football']])} #结果为{'age': 18, 'hobbies': ['basketball', 'football'], 'name': 'winter'}
15 d = {x:y for x, y in zip(['name','age','hobbies'],['winter',18,['basketball','football']]) if x=='name'}#结果为{'name': 'winter'}
16
17 #通过字典方法fromkeys()创建一个含有默认值的字典,fromkeys方法是dict类的静态方法
18 d = dict.fromkeys(['name','gender'], 'unknown') #结果{'gender': 'unknown', 'name': 'unknown'}
2)字典方法
1 #增
2 d = {
3 'name':'winter',
4 'age':18,
5 'hobbies':['basketball','football']
6 }
7 #update,类似于list.extend(),将键值对参数加到字典中,对于已存在的更新
8 d.update({'gender':'male'}) #结果为:{'age': 18, 'gender': 'male', 'hobbies': ['basketball', 'football'], 'name': 'winter'}
9
10
11 #删
12 d = {
13 'name':'winter',
14 'age':18,
15 'hobbies':['basketball','football']
16 }
17 #popitem,随机删除一组键值对,并返回该组键值对
18 res = d.popitem() #结果为res = ('hobbies', ['basketball', 'football']), d为{'age': 18, 'name': 'winter'}
19 #pop,删除指定键的键值对,返回对应的值
20 res = d.pop('name') #结果为res = 'winter', d为{'age': 18}
21 #clear,清空字典,字典对象还在,没有被回收
22 d.clear() #结果d为{}
23 #del关键字,可以用于删除字典对象和元素
24 d = {
25 'name':'winter',
26 'age':18,
27 'hobbies':['basketball','football']
28 }
29 del d['hobbies'] #结果为 {'age': 18, 'name': 'winter'}
30 del d #结果访问d,报NameError
31
32
33 #查
34 d = {
35 'name':'winter',
36 'age':18,
37 'hobbies':['basketball','football']
38 }
39 #get,根据键取对应的值,没有对应的键,就返回第二个参数,默认为None
40 res = d.get('name', 'not found') #res = ’winter'
41 res = d.get('gender', 'not found') #res = 'not found'
42 #setdefault,根据键取对应的值,如果不存在对应的键,就增加键,值为第二个参数,默认为None
43 res = d.setdefault('name','winter') #res = ’winter'
44 res = d.setdefault('gender','male') #res = 'male',d变为{'age': 18, 'gender': 'male', 'hobbies': ['basketball', 'football'], 'name': 'winter'}
45 #keys,获得所有的键
46 res = d.keys() #res = dict_keys(['name', 'age', 'hobbies', 'gender'])
47 #values,获得所有的值
48 res = d.values() #res = dict_values(['winter', 18, ['basketball', 'football'], 'male'])
49 #items,获得所有的键值对
50 res = d.items() #res = dict_items([('name', 'winter'), ('age', 18), ('hobbies', ['basketball', 'football']), ('gender', 'male')])
51
52
53 #copy方法, 和list.copy一样,是浅复制
3)字典元素的访问
1 dic = {'name':'winter', 'age':18}
2 '''
3 下面3中方式的结果都为
4 name winter
5 age 18
6 '''
7 #方式1
8 for item in dic:
9 print(item, dic[item])
10 #方式2
11 for item in dic.keys():
12 print(item, dic[item])
13 #方式3
14 for k,v in dic.items():
15 print(k, v)
推荐方式1),采用了迭代器来访问;
4)字典vs列表
a) 字典:
- 查找和插入的速度极快,不会随着key的数目的增加而增加(直接查找hash后得到的内存地址);
- 需要占用大量的内存,内存浪费多(大量的hash值,占用内存你空间)
- key不可变
- 默认无序
b) 列表:
- 查找和插入的时间随着元素的增加而增加
- 占用空间小,浪费内存很少
- 通过下标查询
- 有序
9. 集合
这是高一数学的内容了
集合对象是一组无序排列的值,分为可变集合(set)和不可变集合(frozenset);可变集合不可hash;不可变集合可以hash,即可以作为字典的键;
特性:
a) 无序性,无法通过索引访问
b) 互异性,元素不可重复,即有去重的功能
1) 创建集合
1 #直接创建可变集合
2 s1 = {1,2,3,3} #结果,python3.x为{1,2,3},python2.x为set([1, 2, 3]),因为集合不允许有重复元素,所以只有一个3元素
3 #通过函数创建
4 s2 = set([1,2,3,4]) #创建可变集合{1, 2, 3, 4}
5 s3 = frozenset([1,2,3,3]) #创建不可变集合,结果为frozenset({1, 2, 3})
2) 集合方法和操作符
这里直接用一张表:
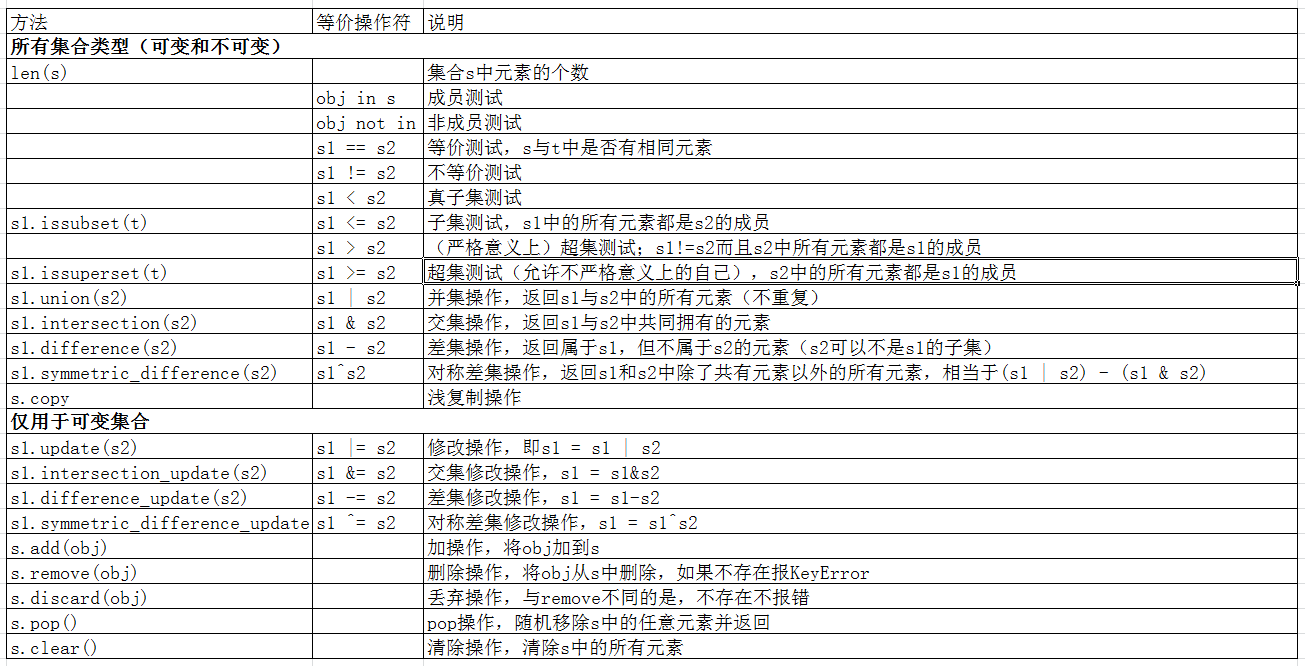
这里只列出可变集合的方法示例,因为不可变集合的方法可变集合都有
a) 单个集合的操作
1 #集合
2
3 #直接创建可变集合
4 s1 = {1,2,3,3} #结果,python3.x为{1,2,3},python2.x为set([1, 2, 3]),因为集合不允许有重复元素,所以只有一个3元素
5 #通过函数创建
6 s2 = set([1,2,3,4]) #创建可变集合{1, 2, 3, 4}
7 s3 = frozenset([1,2,3,3]) #创建不可变集合,结果为frozenset({1, 2, 3})
8
9
10 s1 = {1,2,3}
11
12 #增
13 s1.add('456') #结果s1 = {1, 2, 3, '456'}
14 s1.update('789') #结果s1 = {1, 2, 3, '7', '8', '9', '456'}
15
16 #删
17 res = s1.pop() #结果res = 1,s1 = {2, 3, '7', '8', '9', '456'}
18 s1.remove(3) #结果s1 = {2, '7', '8', '9', '456'}
19 s1.discard(4) #结果s1 = {2, '7', '8', '9', '456'},同时不报Error
20 s1.clear() #结果s1 = set()
21
22 #浅复制
23 s1 = {1,2,3}
24 s2 = s1.copy() #结果s2 = {1,2,3}
b) 集合之间的操作,集合的主要功能
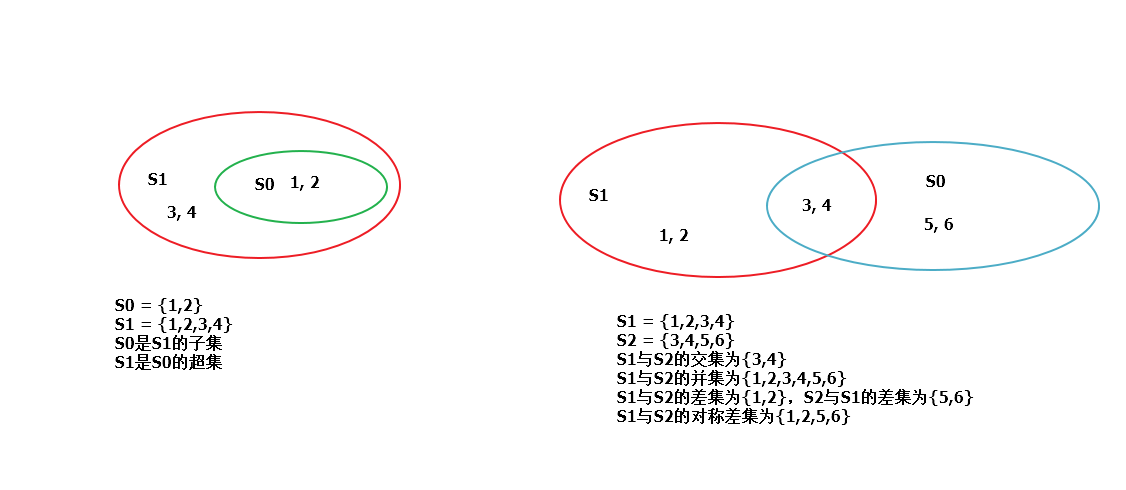
1 s0 = {1,2}
2 s1 = {1,2,3,4}
3 s2 = {3,4,5,6}
4
5 #子集,超级判断
6 res = s0.issubset(s1) #结果res = True
7 res = s1.issubset(s2) #结果res = False
8 res = s1.issuperset(s0) #结果res = True
9 res = s0 <= s1 #结果res = True
10
11 #并集
12 res = s1.union(s2) #结果res = {1, 2, 3, 4, 5, 6}
13 res = s1 | s2 #结果res = {1, 2, 3, 4, 5, 6}
14
15 #交集
16 res = s1.intersection(s2) #结果为{3, 4}
17 res = s1 & s2 #结果为{3, 4}
18
19 #差集
20 res = s2.difference(s1) #结果res = {5, 6}
21 res = s2 - s1 #结果res = {5, 6}
22 res = s1.difference(s2) #结果res = {1, 2}
23
24 #对称差集
25 res = s2.symmetric_difference(s1) #结果为{1, 2, 5, 6}
26 res = s2 ^ s1 #结果为{1, 2, 5, 6}
27
28 #在原集合基础上修改原集合
29 s1.intersection_update(s2)
30 s1.difference_update(s2)
31 s1.symmetric_difference_update(s2)
用一张图来解释一下:
2017年9月20日更新
1. 推导式
有列表推导式,字典推导式,集合推导式
1)列表推导式
1 li_1 = [item for item in range(5)] #结果li_1 = [0, 1, 2, 3, 4]
2
3 li_2 = [item for item in range(5) if item > 2] #结果li_2 = [3, 4]
4
5 li_3 = [item if item>2 else 0 for item in range(5)] #结果li_3 = [0, 0, 0, 3, 4]
6
7 li_4 = [(x,y) for x in range(3) for y in range(3,6)] #结果li_4 = [(0, 3), (0, 4), (0, 5), (1, 3), (1, 4), (1, 5), (2, 3), (2, 4), (2, 5)]
8
9 li_raw = [['winter', 'tom', 'lily'], ['winter']]
10 li_5 = [item for li in li_raw for item in li if item.count('l') > 1] #结果li_5 = ['lily']
2)集合推导式
和列表推导式一样,只要把[]换成{}即可
3)字典推导式
和列表推导式一样,只是没有if...else...形式
4)有元祖推导式吗?
(x for x in range(5))就是元祖推导式呢?
答案是:不是的
(x for x in range(5)得到的是一个生成器
>>>a = (x for x in range(10)) >>>a >>><generator object <genexpr> at 0x0000000004B09F68>
>>>a.__next__()
>>>0
>>>a.__next__()
>>>1

















 578
578

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









