







 本文介绍了一种新型对话生成模型Mem2Seq,该模型结合了多跳注意力机制和指针网络,有效解决了现有RNN编码-解码模型在整合外部知识库信息和处理长序列时的不足。Mem2Seq不仅能够从历史对话或知识库中复制实体,还能动态生成查询以控制记忆访问,展现出在对话数据集上的优秀性能。
本文介绍了一种新型对话生成模型Mem2Seq,该模型结合了多跳注意力机制和指针网络,有效解决了现有RNN编码-解码模型在整合外部知识库信息和处理长序列时的不足。Mem2Seq不仅能够从历史对话或知识库中复制实体,还能动态生成查询以控制记忆访问,展现出在对话数据集上的优秀性能。
一、概述
近年来端到端的学习方法取得了不错得成绩,已有的RNN 编码-解码模型可以直接将纯文本对话历史映射到输出响应,并且对话状态是潜在的,因此不需要手工标注状态标签。
另外RNN编码-解码模型+基于attention的复制机制则可以直接从输入源复制到输出响应端,能够解决在对话历史中没有出现的token,生成正确和相关的实体。
但是这些方法仍然存在两个问题:
- 他们努力的想将外部的KB知识整合进入RNN网络的隐藏层,但是RNN处理长序列并不稳定。
- 处理长序列非常耗费时间,尤其是加入了attention机制的时候。
后来发现MemNNs(end-to-end memory networks)可以解决上述两个问题,它通过外部存储器嵌入几个embedding 矩阵,并使用查询向量反复的读取存储器,从而解决能够记忆外部KB信息并且快速编码长对话历史记录。但是,MemNN只是从预定义的候选池中选择输出响应,而不是逐字生成,并且Memory query需要显示设计而不是被学习,缺乏复制机制。
为了解决MemNNs的问题,论文提出了一个新的框架:Mem2Seq。它在MemNNs的框架上使用序列生成框架进行扩充,使用全局multi-hop attention机制直接从历史对话或KB进行复制。
Mem2Seq的优点:
(1):Mem2Seq是第一个结合了multi-hop attention机制和pointer networks的生成网络模型,并有效的加入了KB信息。
(2):Mem2Seq学习了如何动态生成查询,去控制memory的访问,可以可视化memory控制器和attention的跳跃之间的模型动态。
(3):Mem2Seq训练速度快并且在一些面向对话的数据集上表现的非常好。
二、一些基本概念
1,multi-hop attention机制:这个机制就像人类翻译句子时会分解句子结构:不是看一眼句子接着头也不回地翻译整个句子,这个网络会反复「回瞥(glimpse)」句子,选择接下来翻译哪个单词,这点和人类更像:写句子时,偶然回过头来看一下关键词。 多跳注意是这一机制的增强版本,可以让神经网络多次「回瞥」,以生成更好的翻译效果。多次「回瞥」也会彼此依存。比如,头次「回瞥」关注动词,那么,第二次「回瞥」就会与助动词有关。
2,pointer networks(指针网络):是seq2seq模型的一个变种。他们不是把一个序列转换成另一个序列, 而是产生一系列指向输入序列元素的指针。最基础的用法是对可变长度序列或集合的元素进行排序。在指针网络中, 注意力更简单:它不考虑输入元素,而是在概率上指向它们。实际上,你得到了输入的排列。有关更多细节和公式, 请参阅论文:https://arxiv.org/abs/1506.03134
三、模型介绍
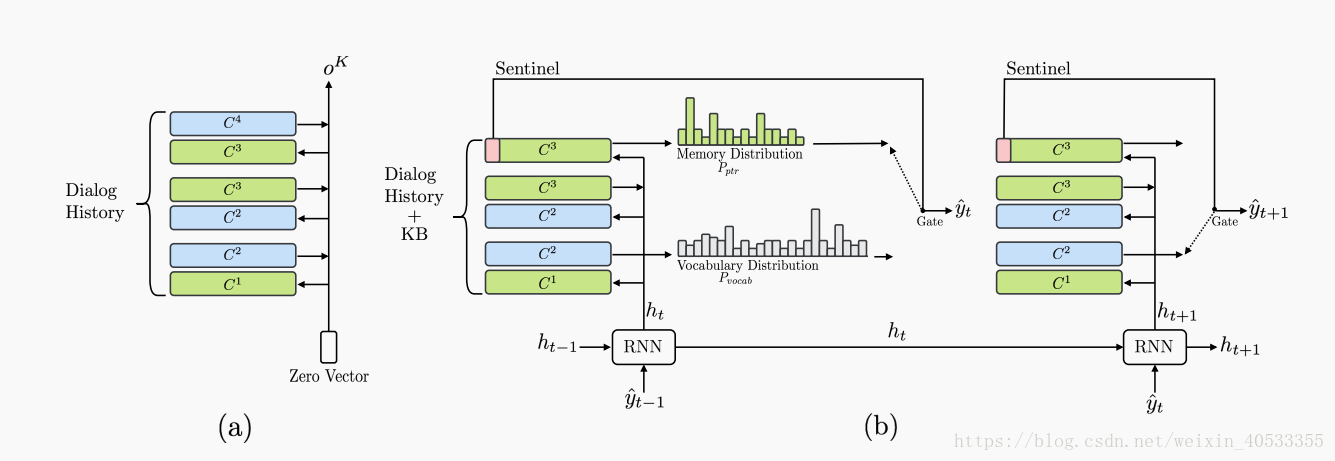
Mem2Seq 由两个组件组成:MemNN编码器(a)和memory解码器(b),如图所示,MemNN编码器创建对话历史的矢量表示。 然后,memory解码器读取并复制memory以产生响应。
其中MemNN编码器(a)部分是3跳的Memory encoder。(b)是2步生成的 Memory decoder。
3.1基本符号及概念
X:是一个token序列,用来定义历史对话消息的。形式为
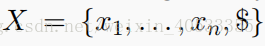
$:哨兵(sentinel)。一旦选择了$,则从中 P(vocab)生成token,否则从P(ptr) 分布获取memory context。senine标记用作控制每个时间步分布使用的的hard gate。
KB元组:形式为
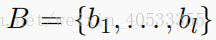
存储KB信息得时候用 (subject, relation, object)来表示,计算subject,relation,object的词向量求和,得到每个KB内存表示。解码阶段,object部分作为P(ptr) 的生成。只有于特定对话相关的KB的特定部分才能加载到内存中。
memory context:一方面X存储在memory module中。 在X的每个标记中添加时态信息和说话者信息以捕获顺序依赖性。另一方面,为了存储KB信息,使用(主题,关系,对象)表示。 用P(ptr)表示:
U:是X和B的连接,表示为
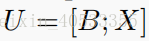
Y:预期系统输出响应。表示为Y={y1,........ym}
PTR:为pointer索引集。表示为
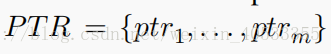
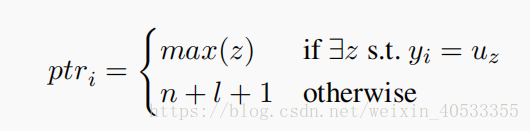
(uz:是输入序列。 n+l+1是哨兵的位置索引(是X和B中元素的个数再加1))
3.2 Memory 编码(a处)
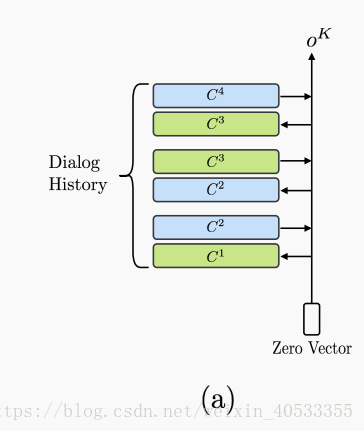
Mem2Seq用来了一个标准的相邻加权的MemNN作为编码器。输入为U,输出为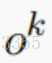 。
。
MemNN的memories是由一组可训练的embedding矩阵C表示的。C={C1,..........Ck+1.},这里每个 Ck 将token映射为向量。
qk:查询向量(query vector),作为一个reading head。
模型在K hops中循环,并用以下方法计算每个memory i中的attention权重:
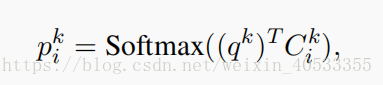
这里,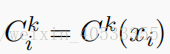 是位置i处的memory内容。以及softmax的计算公式。
是位置i处的memory内容。以及softmax的计算公式。
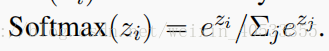
这里,pk:是soft memory selector,作用是可以决定与查询向量 qk 的memory 相关性。
attention权重的含义是:memory i用于查询向量 qk 的相关性。attention权重值越高,则越相关。
然后,模型通过以下公式计算输出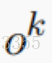 。
。
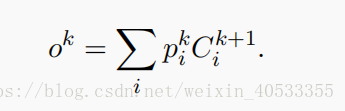
在下个hop中通过qk通过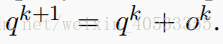 来更新。
来更新。
总结:先将token映射为矩阵C,通过公式计算p,在通过公式计算o。得到编码结果。
3.3 memory 解码
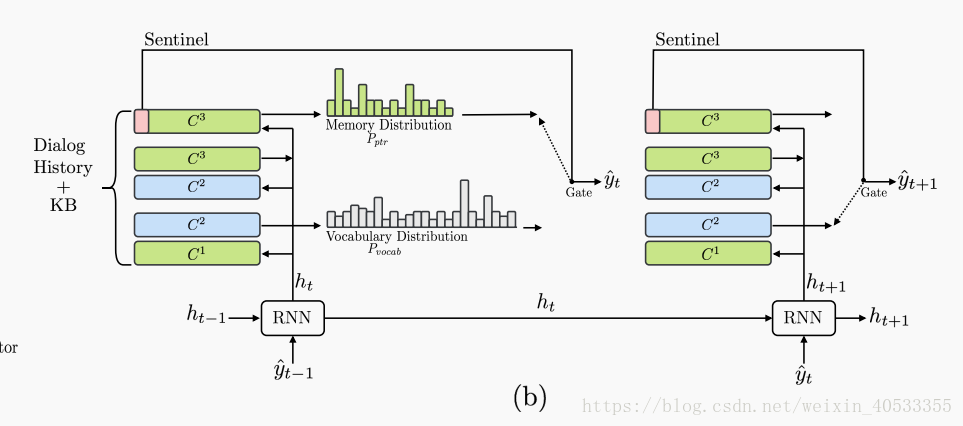
解码的是RNN和MemNN。由于要使用对话历史和KB信息来生成适当的系统响应,MemNN加载X和B。
解码器的输入:是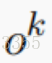 ,即编码器的输出。
,即编码器的输出。
输出为:通过指向Memory中的输入生成tokens,于指针网络使用attention相似。
对于MemNN来说,GRU充当一个动态查询生成器。在t 解码时刻GRU的输入是:先前生成的单词和先前的查询。GRU的输出:新的查询向量(如下公式所示)。
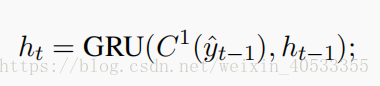
ht 传递给MemNN产生token。(这里 h0 是编码器的输出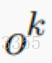 )
)
然后在每个解码步骤中,都会生成2个分布:vocabulary 分布 p(vocab) 和Memory contents 分布 p(ptr) ,他们是对话历史和KB信息。
其中p(vocab) 是通过连接第一个hop attention的输出和当前查询向量生成的。

W1是训练参数。
p(ptr) 是由解码器的最后的MemNN top 处的attention权值生成。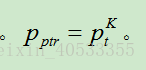
最后解码器通过指向memory中的输入字段来生成token。
总结:论文中说,架构设计的原因是:因为期望第一hop和最后一hop的attention weights分别显示“更松散(looser)”和“更清晰(sharper)”的分布。 第一hop更侧重于检索memory信息,最后一hop倾向于选择利用pointer监督的精准token。因此,在训练期间,通过最小化两个标准交叉熵损失的总和来共同学习所有参数:一个是vocabulary分布的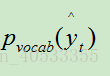 和yt。另一个方法是在memory分布的
和yt。另一个方法是在memory分布的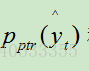 和ptrt(它属于PTR)。
和ptrt(它属于PTR)。
四、实验
论文中用三个数据集进行评估:bAbI(模拟对话)、DSTC2(真实人机对话)、In-Car(人-人对话和多域对话)。
在GitHub 上https://github.com/HLTCHKUST/Mem2Seq中包含了bAbI数据集。
另外论文中也公布了一些模型训练的细节,如优化器的选择(Adam),学习率,及hop K的选择等。这里就不多说了。
另外论文中还有一些对实验的评价:侧重性能、安全、正确等。如果详细了解这块的,可以看论文。https://arxiv.org/abs/1804.08217(论文地址)
五、总结
整个框架很新,感觉这个框架挺好的。它在GitHub上也已经开源,如何训练啥的,都讲的很清楚。但是我测试还未成功,后期还会在调试这个代码。
但这个框架也有局限性,在未来的工作中,可以应用几种方法(例如,强化学习等),Beam Search,以改善响应相关性。

















 192
192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









