







 本文深入探讨Redis的数据结构、操作命令及其在Java中的应用。Redis作为高性能的键值存储系统,支持多种数据类型,包括字符串、哈希、列表、集合和有序集合。文章详细介绍了每种数据类型的特性和常见操作,如String的SET和GET,Hash的HSET和HGET,List的LPUSH和LPOP,Set的SADD和SMEMBERS,以及Sorted Set的ZADD和ZRANGE。此外,还讨论了Redis的事务、脚本、数据备份和Java API使用方法。
本文深入探讨Redis的数据结构、操作命令及其在Java中的应用。Redis作为高性能的键值存储系统,支持多种数据类型,包括字符串、哈希、列表、集合和有序集合。文章详细介绍了每种数据类型的特性和常见操作,如String的SET和GET,Hash的HSET和HGET,List的LPUSH和LPOP,Set的SADD和SMEMBERS,以及Sorted Set的ZADD和ZRANGE。此外,还讨论了Redis的事务、脚本、数据备份和Java API使用方法。
原文链接: https://blog.youkuaiyun.com/weixin_40533111/article/details/83894281 作者四月天五月雨^_^,转载请注明出处,谢谢
前言
redis常被称为数据结构服务器,可基于内存亦可持久化的日志型、Key-Value数据库, 因为值(value)可以是 字符串(String), 哈希(Map或对象), 列表(list), 集合(sets) 和 有序集合(sorted sets)等类型,提供多种语言的api,本文最后以java为例接入.
优势:
1.性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
2.丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作,存字符,音频,视频等各种数据都行,当然redis的核心价值是存储小,多,快的数据,因为是单线程并提供原子性操作,分布式锁就是一个常见应用。
3.支持key过期设置
目录:
1.redis常见的数据结构及操作命令
2.redis key相关操作
3.redis 脚本,事务
4.redis数据备份
5.在java中使用
正文:
1.redis常见的数据结构及操作命令
redis支持五种基本数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。新版本加了范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。
1.1 String
key是二进制安全的,即可用任何二进制序列作为key,不建议太长如512个字节,造成内存浪费和查询成本高.
String类型是最简单Redis类型。像一个可以持久化的memcached服务器(注:memcache的数据仅保存在内存中,服务器重启后,数据将丢失),可完全代替memcached,不管是性能还是安全上.
基本语法格式:
redis 127.0.0.1:6379> COMMAND KEY_NAME
常用操作命令如下:
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | set key value | 设置指定 key 的值 |
| 2 | GET key | 获取指定 key 的值 |
| 3 | INCR key | 将 key 中储存的数字值增一 |
| 4 | DECR key | 将 key 中储存的数字值减一 |
| 5 | MGET key1 [key2…] | 获取所有(一个或多个)给定 key 的值 |
| 6 | SETEX key seconds value | 将值 value 关联到 key ,并将 key 的过期时间设为 seconds (以秒为单位) |
| 7 | SETNX key value | 只有在 key 不存在时设置 key 的值 |
| 8 | STRLEN key | 返回 key 所储存的字符串值的长度 |
| 9 | MSET key value [key value …] | 同时设置一个或多个 key-value 对。 |
| 10 | GETRANGE key start end | 返回 key 中字符串值的子字符 |
| 11 | GETSET key value | 将给定 key 的值设为 value ,并返回 key 的旧值(old value) |
简单示例:
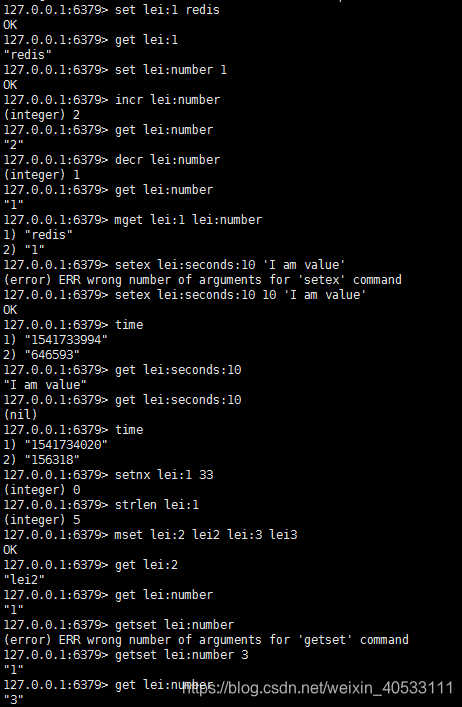
使用场景:
可完全替换memcached,存储简单k-v.
计数,存储少量热点数据,分布式锁(秒杀系统有应用)
1.2 Hash
Redis hash 是一个string类型的field和value的映射表,就是String类型外面包了一层,hash特别适合用于存储对象。
画图对比:
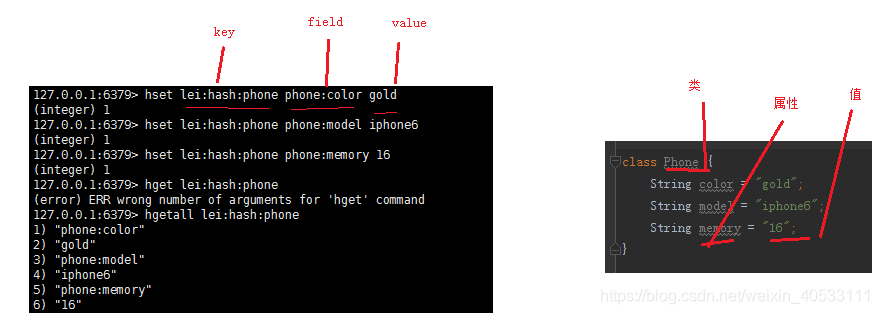
所以hash特别适合存对象(map)
常用操作命令如下:
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | HSET key field value | 将哈希表 key 中的字段 field 的值设为 value |
| 2 | HGET key field | 获取存储在哈希表中指定字段的值 |
| 3 | HDEL key field2 [field2] | 删除一个或多个哈希表字段 |
| 4 | HGETALL key | 获取在哈希表中指定 key 的所有字段和值 |
| 5 | HEXISTS key field | 查看哈希表 key 中,指定的字段是否存在 |
| 6 | HMGET key field1 [field2] | 获取所有给定字段的值 |
| 7 | HMSET key field1 value1 [field2 value2 ] | 同时将多个 field-value (域-值)对设置到哈希表 key 中 |
| 8 | HSETNX key field value | 只有在字段 field 不存在时,设置哈希表字段的值 |
部分示例如上图
使用场景:
上面也提到天然适合存储对象,此处对下几种方式优劣(以上图中的key lei: hash:iphone为例),key都一样,仅比较value:
1.使用String类型存储,value即为整个对象的序列化对象,使用时反序列化:缺陷:当修改一个属性时,需要把整个对象反序列化->修改->序列化存储,开销成本较大.
2.将这个对象的多个属性拆分,每个属性作为一个k-v存储,这样修改是挺方便,但造成多个key,浪费内存
3.使用hash:存储时开销较小,修改时,可以仅仅修改其中一个filed(属性)的值,开销小,(最佳方式)
当一张hash表比较小时,实际内存存储编码方式为zipmap,紧凑型存储,节省内存,当hash表filed较多时,才按照hashMap存储.
1.3 list
list列表也是常见的存储结构,它是一个双向链表,即可以作为栈结构也可以作为队列结构.
常用操作命令如下:
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | LPUSH key value1 [value2] | 将一个或多个值插入到列表头部 |
| 2 | LPOP key | 移出并获取列表的第一个元素 |
| 3 | LLEN key | 获取列表长度 |
| 4 | LRANGE key start stop | 获取列表指定范围内的元素 |
| 5 | LREM key count value | 移除列表元素 |
| 6 | LTRIM key start stop | 对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除。 |
| 7 | RPUSH key value1 [value2] | 在列表中添加一个或多个值 |
| 8 | RPOP key | 移除并获取列表最后一个元素 |
| 9 | RPUSHX key value | 为已存在的列表添加值 |
简单示例:
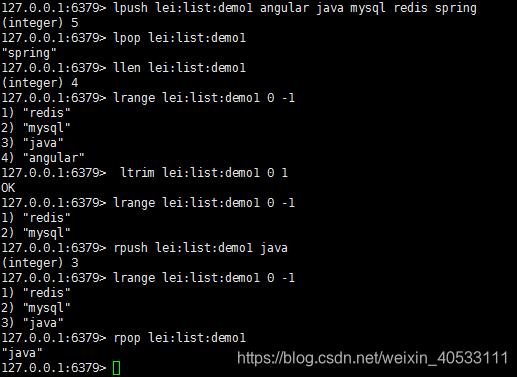
使用场景:
1.取出最新n个消息(不涉及复杂排序)
比如最新1000个访客,就可以使用list,同时使用LTRIM key 0 1000,只保存最新的1000个
2.作为队列
可用来走日志打印,多个端进行push,一个端进行Rpop,
1.4 set
Redis的Set是string类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。
Redis 中 集合是通过哈希表实现的,所以没有hash碰撞时添加,删除,查找的复杂度都是O(1),有碰撞时为O(n)
常用操作命令如下:
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | SADD key member1 [member2] | 向集合添加一个或多个成员 |
| 2 | SCARD key | 获取集合的成员数 |
| 3 | SDIFF key1 [key2] | 返回给定所有集合的差集 |
| 4 | SINTER key1 [key2] | 返回给定所有集合的交集 |
| 5 | SISMEMBER key member | 判断 member 元素是否是集合 key 的成员 |
| 6 | SMEMBERS key | 返回集合中的所有成员 |
| 7 | SREM key member1 [member2] | 移除集合中一个或多个成员 |
| 8 | SUNION key1 [key2] | 返回所有给定集合的并集 |
简单示例:
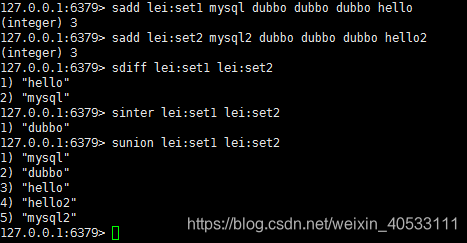
使用场景:
一些会不重复的数据,进行交集,并集,差集等灵活操作
抖音的关注人,粉丝,可分别放在一个set中
1.5 sorted set
redis 有序集合和集合一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的,但分数(score)却可以重复,当分数重复时,按照自然顺序排序。
常用操作命令如下:
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | ZADD key score1 member1 [score2 member2] | 向有序集合添加一个或多个成员,或者更新已存在成员的分数 |
| 2 | ZCARD key | 获取有序集合的成员数 |
| 3 | ZCOUNT key min max | 计算在有序集合中指定区间分数的成员数 |
| 4 | ZINCRBY key increment member | 有序集合中对指定成员的分数加上增量 increment |
| 5 | ZINTERSTORE destination numkeys key [key …] | 计算给定的一个或多个有序集的交集并将结果集存储在新的有序集合 key 中 |
| 6 | ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT] | 通过分数返回有序集合指定区间内的成员 |
| 7 | ZRANK key member | 返回有序集合中指定成员的索引 |
| 8 | ZREM key member [member …] | 移除有序集合中的一个或多个成员 |
| 9 | ZREMRANGEBYSCORE key min max | 移除有序集合中给定的分数区间的所有成员 |
| 10 | ZSCORE key member | 返回有序集中,成员的分数值 |
| ZREVRANGEBYSCORE key max min [WITHSCORES] | 返回有序集中指定分数区间内的成员,分数从高到低排序 | |
| ZUNIONSTORE destination numkeys key [key …] | 计算给定的一个或多个有序集的并集,并存储在新的 key 中 |
简单示例
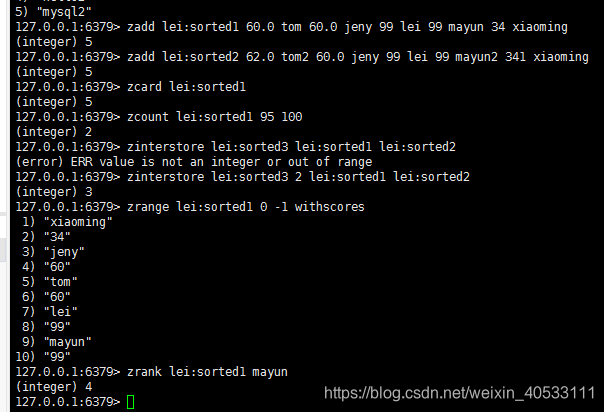
使用场景:
sorted set 比set多了一个score的(分数),可以通过这个scored来排序,相同scored的数据按自然顺序,比如微信朋友圈就可以用sorted set 来排序,分数用时间来表示. 经典案例:一个班的同学按分数排序,就可以把分数作为scored,实现排序.当然应用远不止于此.
Redis sorted set的内部使用HashMap和跳跃表(SkipList)来保证数据的存储和有序,HashMap里放的是成员到score的映射,而跳跃表里存放的是所有的成员,排序依据是HashMap里存的score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。
2.redis key相关操作
常用操作命令如下:
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | DEL key | 该命令用于在 key 存在是删除 key。 |
| 2 | EXPIRE key | seconds 为给定 key 设置过期时间。 |
| 3 | EXPIREAT key timestamp | EXPIREAT 的作用和 EXPIRE 类似,都用于为 key 设置过期时间。 不同在于 EXPIREAT 命令接受的时间参数是 UNIX 时间戳(unix timestamp)。 |
| 4 | EXISTS key | 检查给定 key 是否存在 |
| 5 | KEYS pattern | 查找所有符合给定模式( pattern)的 key |
| 6 | MOVE key db | 将当前数据库的 key 移动到给定的数据库 db 当中 |
| 7 | PERSIST key | 移除 key 的过期时间,key 将持久保持 |
| 8 | PTTL key | 以毫秒为单位返回 key 的剩余的过期时间 |
| 9 | TTL key | 以秒为单位,返回给定 key 的剩余生存时间(TTL, time to live) |
| 10 | TYPE key | 返回 key 所储存的值的类型 |
简单示例
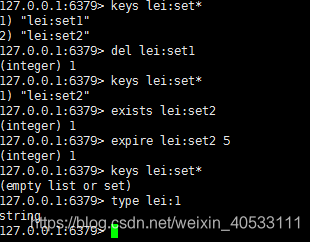
3.redis 脚本,事务
3.1脚本
Redis 脚本使用 Lua 解释器来执行脚本。 Reids 2.6 版本通过内嵌支持 Lua 环境。执行脚本的常用命令为 EVAL。
Eval 命令的基本语法如下:
redis 127.0.0.1:6379> EVAL script numkeys key [key …] arg [arg …]
常用操作命令如下:
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | EVAL script numkeys key [key …] arg [arg …] | 执行 Lua 脚本 |
| 2 | EVALSHA sha1 numkeys key [key …] arg [arg …] | 执行 Lua 脚本 |
| 3 | SCRIPT EXISTS script [script …] | 查看指定的脚本是否已经被保存在缓存当中 |
| 4 | SCRIPT FLUSH | 从脚本缓存中移除所有脚本 |
| 5 | SCRIPT KILL | 杀死当前正在运行的 Lua 脚本 |
| 6 | SCRIPT LOAD script | 将脚本 script 添加到脚本缓存中,但并不立即执行这个脚本。 |
简单示例
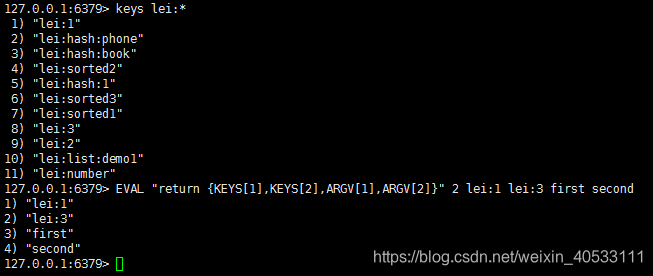
3.2事务
Redis 事务可以一次执行多个命令, 并且带有以下两个重要的保证:
事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
一个事务从开始到执行会经历以下三个阶段:
开始事务。
命令入队。
执行事务。
常用操作命令如下:
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | EXEC | 执行所有事务块内的命令 |
| 2 | DISCARD | 取消事务,放弃执行事务块内的所有命令 |
| 3 | MULTI | 标记一个事务块的开始。 |
| 4 | UNWATCH | 取消 WATCH 命令对所有 key 的监视 |
| 5 | WATCH key [key …] | 监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断 |
简单示例
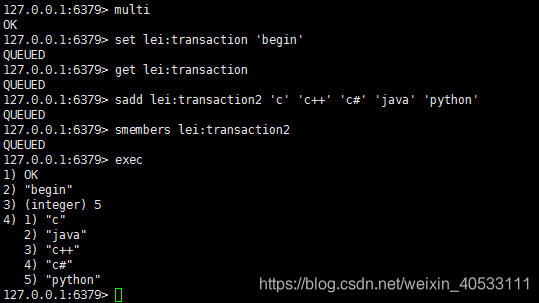
注意:
1.因为redis是单线程,不适合执行大事务,造成其他服务不可用,
2.redis不支持事务回滚,redis服务只要活着,并且执行命令正确,当是不会出错的,因此就不需要回滚,所以当执行事务时,我们要再三检查命令的正确性,不能像数据库中可以回滚,即应由事务开启者负责结果.这也是保持redis高性能的一个让步.
4.redis数据备份
这种备份是手动备份,不是容灾中的自动执行
redis Save 命令基本语法如下:
redis 127.0.0.1:6379> SAVE
该命令将在 redis 安装目录中创建dump.rdb文件。
恢复数据
如果需要恢复数据,只需将备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可。获取 redis 目录可以使用 CONFIG 命令,如下所示:
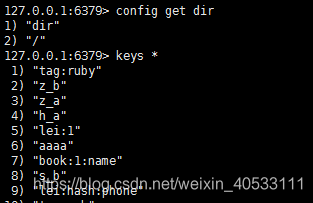
演示中的这个文件在根目录.
5.在java中使用
当熟悉了redis基本操作后,对应的javaAPI不看也可以猜出来并使用了,语言的规则就是封装.并提供人性化操作.
1.引入新版jedis依赖
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
2.即可使用客户端操作
/**
* @author lei
* @date 2018/11/9 18:13
*/
public class JedisTest {
private static Jedis jedis;
static {
//连接本地的 Redis 服务
jedis = new Jedis("192.168.229.5");
//密码
jedis.auth("******");
}
@Test
public void test1() {
System.out.println("Connection to server sucessfully");
//查看服务是否运行
System.out.println("Server is running: " + jedis.ping());
}
@Test
public void test2() {
Long lpush = jedis.lpush("jedisList1", "java", "c++", "python", "angular");
System.out.println("pushNumber:" + lpush);
List<String> jedisList1 = jedis.lrange("jedisList1", 0, -1);
jedisList1.forEach(System.out::println);
}
}
下篇是关于redis集群,和容错等介绍:https://blog.youkuaiyun.com/weixin_40533111/article/details/83658248
参考:
redis官网: https://redis.io/
梦里梦到 醒不来的梦 红线里被软禁的红
所有刺激 剩下疲乏的痛 再无动于衷
从背后 抱你的时候 期待的却是她的面容
说来实在嘲讽 我不太懂 偏渴望你懂
是否幸福轻得太沉重 过度使用不痒不痛
烂熟透红 空洞了的瞳孔 终于掏空 终于有始无终
得不到的永远在骚动 被偏爱的都有恃无恐
玫瑰的红 容易受伤的梦
握在手中 却流失于指缝 又落空
红是朱砂痣烙印心口 红是蚊子血般平庸

















 4086
4086

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









