







比起SparkStreaming优势
1 自定义三种时间的处理
例如自定义设定字段值为数据时间,而不是根据机器默认时间
2 State 支持更复杂的逻辑
3 window窗口
4 流对比微批
watermark避免网络等原因导致乱序数据带来的计算不正确/CEP API等
算子状态 Operatior State 和 键控状态 Keyed State
State 托管状态。通过数据结构存储上一次数据结果,来结合新数据处理复杂的业务逻辑计算 (例如读取3个key则做一次合并等等需求)
Operate State (还未经过KeyBy)
Keyed State (经过KeyBy,常用)
ValueState
ListState
MapState
ReducingState
AggregatingState
State 存储位置
MemoryStateBackend 默认选择,存储在TaskManager堆内存中(默认5mb),checkpoint时改存储到指定文件中如HDFS
FsStateBackend
RocksDBStateBackend
State 如何保证数据安全/恢复数据
checkpoint,默认不开启,开启后默认100毫秒一次,可以自己参数配置,如果state很大则五分钟也可以。
默认也只保留最近1次最新的checkpoint数据
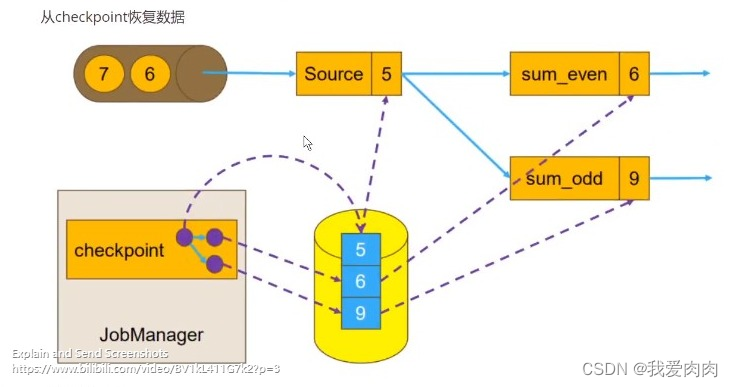
从checkpoint恢复
如图下,数据已经传输了1,2,3,4,5。数据6,7等在等待传输。此时sum_even统计为6(2/4),sum_odd为9,
数据偏移量为5(已经传输的数据)。5/6/9 为一个整体作checkpoint。当数据异常时则读取5/6/9来做数据恢复处理
Checkpoint Chandy-Lamport算法
因为checkpoint数据持久化时整条链路上都不能再传输新数据,会导致性能很低下。所以加入了Chandy-Lamport算法。
将整个链路一分为4次checkpoint,降低程序停止等待的时间
1 任务开启后,JobManager发起checkpoint记录一轮相同的barrier数据,如图下两个2 2。
2 所有InputStream链路的barrier到达Source第二次做checkpoint上报记录source偏移量,checkpoint结束后再继续发送数据
3 在source和sink的中间,barrier之前的数据则做逻辑运算sum_even/odd,barrier之后的则做缓存等待下一轮所有barrier到达
4 barrier对齐。所有barrier到达逻辑运算sum_even/odd后第三次上报checkpoint,记录逻辑计算后数据如下图
5 barrier全部到达sink后,第四次checkpoint sink的barrier数据
最后综合之前所有checkpoint作为一个完整checkpoint记录,备用将来的数据恢复

重启策略
固定间隔
默认,配置多少间隔时间重试一次,一共允许的尝试重试次数,到达设置的重试次数阈值则重启
2 种配置,全局配置 flink-conf.yaml 和 代码配置
失败率
配置一段时间内的失败次数
无重启
checkpoint和savepoint比较
1.目的:checkpoint重点是在于自动容错,savepoint重点在于程序修改或者更新后从状态中恢复
2.触发者:checkpoint是flink自动触发,而savepoint是用户主动触发
3.状态文件保存:checkpoint一般都会自动删除;savepoint一般都会保留下来,除非用户去做相应的删除操作
WaterMark解决数据乱序的计算不正确问题

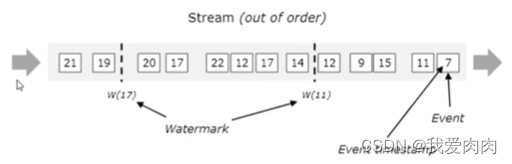
例如图上watermark到11时,已经传过来的12,15的数据不会统计做逻辑运算
CEP
定义匹配模式,读取数据做逻辑处理 CEP.pattern(输入流,自定义匹配方法)
如 start.times(3).where(_.behavior.startsWith(‘fav’))


















 2408
2408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











