







 本文详细介绍了数据仓库的概念,包括业务数据和用户行为数据的采集、Hive数仓的层级结构(ods、dw、dwd、dws、ads层)以及数据输出的用途。重点讨论了数据清洗、性能控制和数据倾斜问题,提到了Nginx用于数据转发,Kafka用于消峰处理。此外,还涵盖了数据采集工具如Flume和DataX,以及技术选型如HiveonSpark、Presto和ClickHouse。数据仓库的最终目的是支持统计数据可视化、用户画像和推荐系统。
本文详细介绍了数据仓库的概念,包括业务数据和用户行为数据的采集、Hive数仓的层级结构(ods、dw、dwd、dws、ads层)以及数据输出的用途。重点讨论了数据清洗、性能控制和数据倾斜问题,提到了Nginx用于数据转发,Kafka用于消峰处理。此外,还涵盖了数据采集工具如Flume和DataX,以及技术选型如HiveonSpark、Presto和ClickHouse。数据仓库的最终目的是支持统计数据可视化、用户画像和推荐系统。
数据仓库的概念
输入数据分类
- 业务数据
客户端交互,一般用关系数据库存储 - 用户行为数据
来自客户端,使用埋点的方式,存储为日志文件:
前端页面,点击network–>筛选log–>URL解析–>一个请求,向后端发送商品名称
特点:点击多次,数量大;写入后台后,客户端不会查–>使用关系型数据库不划算 - 爬虫数据
来自其他平台,尽量少用
数据仓库总体介绍
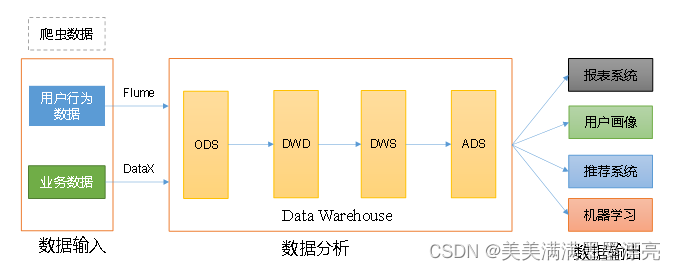
Hive数仓(数据的备份、清晰、聚合、统计):
- ods层:Flume和DataX的数据直接存储到ODS层(原封不动的HIVE表数据):
主要作用:备份 - dw层:ods层数据执行sql语句进行聚合统计
- dwd主要作用:数据清洗阶段,对数据的类型进行检验、敏感数据脱敏;
- dws主要作用:进一步指标统计,多个表join得到结果,预先聚合——性能控制:例如两个大表多次被join得到不同的指标影响性能——改进:直接join两个表,得到中间表,从中间表取多个指标数据
- ads层:统计最终的指标结果数仓的最终目的:
数据输出:
- 统计数据可视化
- 用户画像(通过共同特征:用户标签)、推荐系统(By用户标签等)
- 方式:机器学习算法
项目需求分析
- 采集平台需求,借助采集工具保存到实时和离线数仓
- 用户行为数据采集——Flume
- 业务数据——DataX
- 离线数仓
- 数仓的主题及各个主题的指标(33个)
- 实时数仓
- 数仓的主题及各个主题的指标(48个)
技术框架
技术选型
考虑因素:
- 数据量大小
- 业务需求:实时or离线
- 行业内经验:例如实时数仓的选型——Spark / Flink
- 技术成熟度
- 开发维护成本
- 总成本预算:开源 or 订购
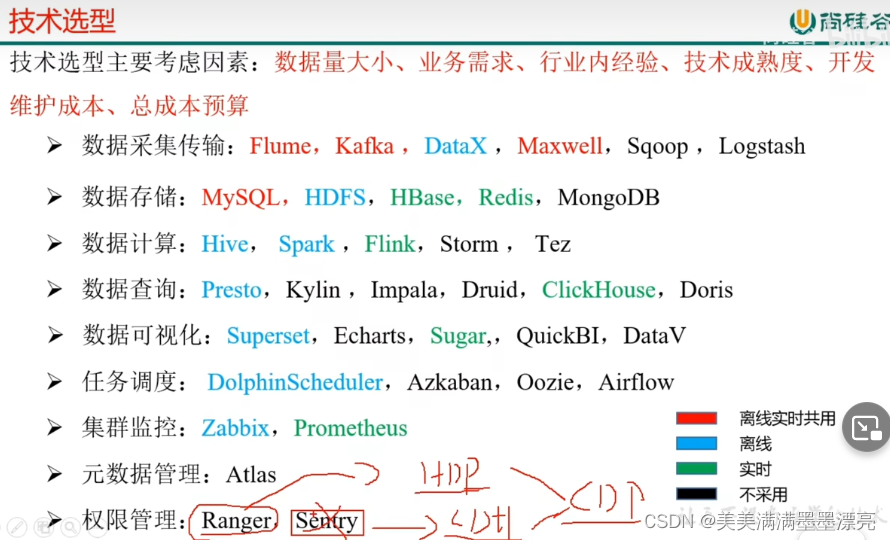
- Datax:全量同步——与Sqoop场景类似
- Maxwell:增量同步
- Logstash:数据量少适用,数据采集,同Flume
- MongoDB:机器学习 or 爬虫
- 离线主要用:Hive on Spark
- Presto 、 ClickHouse:即席查询工具
数据流程设计
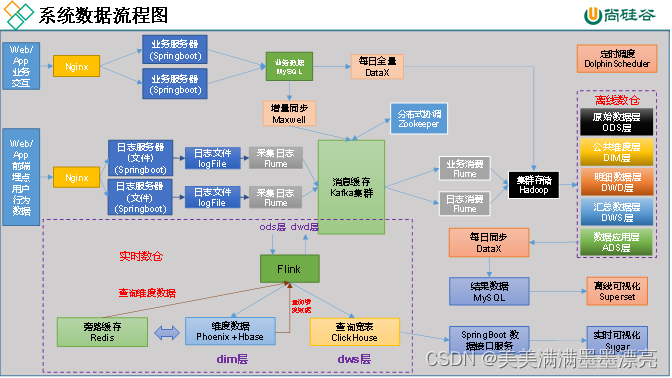
Nginx:数据转发,防止数据倾斜。
什么是数据倾斜?计算节点处理的数据量不同,造成内存不足或者运行速度较慢。
Kafka集群+Zookeeper协调:用于消峰处理
Flume:采集+消费


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









