







目录:
一、介绍
直线回归研究的是一个因变量与一个自变量之间的回归问题。
多项式回归(Polynomial Regression)研究的是一个因变量与一个或多个自变量间多项式的回归分析方法。
多项式回归模型是线性回归模型的一种。
多项式回归问题可以通过变量转换化为多元线性回归问题来解决。
二、多项式回归
# 导包
import numpy as np
import matplotlib.pyplot as plt
# [-3,3)之间随机100个数
x = np.random.uniform(-3, 3, size = 100)
X = x.reshape(-1, 1)
# np.random.normal(0, 1, size=100) 均值为0,方差为1的100个数
y = 0.5 * x**2 + x + 2 + np.random.normal(0, 1, size=100)
# 绘制散点图
plt.scatter(x, y)
plt.show()输出结果:
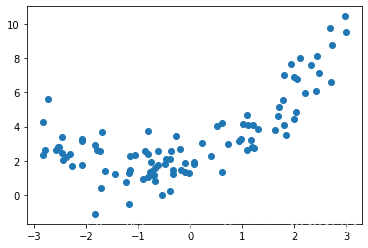
使用线性回归,效果会如何?
# 线性回归
from sklearn.linear_model import LinearRegression
# 训练数据
lin_reg = LinearRegression()
lin_reg.fit(X, y)
# 预测
y_predict = lin_reg.predict(X)
# 绘制散点图
plt.scatter(x, y)
plt.plot(x, y_predict, color='r')
plt.show()输出结果:
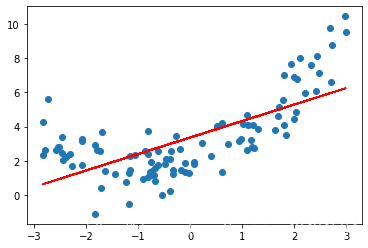
明显,采用拟合的效果并不好。那么如何解决?
解决方案:添加一个特征。
(X**2).shape # 显示:(100, 1)
X2 = np.hstack([X, X**2])
X2.shape # 显示:(100, 2)
# 训练并预测
lin_reg2 = LinearRegression()
lin_reg2.fit(X2, y)
y_predict2 = lin_reg2.predict(X2)
# 绘制散点图
plt.scatter(x, y)
plt.plot(np.sort(x), y_predict2[np.argsort(x)], color='r')
plt.show()输出结果:
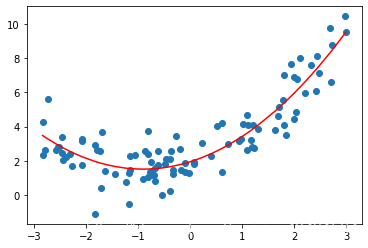
这样显然要比直线拟合的效果好了不少。
# 显示系数
print(lin_reg2.coef_)
print(lin_reg2.intercept_)输出结果:
array([0.95801775, 0.52570266])
1.947743957564143小结:
多项式回归在算法并没有什么新的地方,完全是采用线性回归的思路,关键在于为数据添加新的特征,而这些新的特征是原有的特征的多项式组合,采用这样的方式就能解决非线性问题,这样的思路跟PCA这种降维思想刚好相反,而多项式回归则是升维,添加了新的特征之后,使得更好地拟合高维数据。
三、scikit-learn中的多项式回归
# 导包
import numpy as np
import matplotlib.pyplot as plt
# 模拟数据
x = np.random.uniform(-3, 3, size = 100)
X = x.reshape(-1, 1)
y = 0.5 * x**2 + x + 2 + np.random.normal(0, 1, size=100)
# 多项式回归其实对数据进行预处理,给数据添加新的特征,所以调用库preprocessing
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=2) # 添加二次幂特征
poly.fit(X)
X2 = poly.transform(X)
X2.shape输出结果:
(100, 3) 第一列表示常数项,第二列表示一次项系数,第三列表示二次项系数,接下来查看一下前五列。
X2[:5, :]输出结果:
array([[ 1. , 2.32619679, 5.41119149],
[ 1. , -2.05863059, 4.2379599 ],
[ 1. , 0.26110181, 0.06817416],
[ 1. , -0.50132099, 0.25132274],
[ 1. , 1.48172452, 2.19550756]])from sklearn.linear_model import LinearRegression
# 训练并预测
lin_reg2 = LinearRegression()
lin_reg2.fit(X2, y)
y_predict2 = lin_reg2.predict(X2)
# 绘制散点图
plt.scatter(x, y)
plt.plot(np.sort(x), y_predict2[np.argsort(x)], color='r')
plt.show()输出结果:
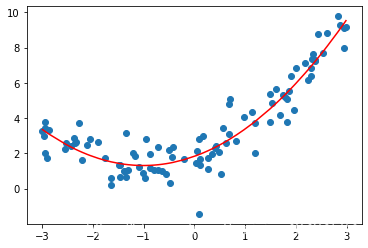
# 显示系数
print(lin_reg2.coef_)
print(lin_reg2.intercept_)输出结果:
array([0. , 1.03772276, 0.51558598])
1.8308914615008804四、关于PolynomialFeatures
多项式回归关键在于如何构建新的特征,在sklearn中已经封装了,那具体如何实现的?
之前使用的都是1维数据,如果使用2维3维甚至更高维呢?
# 导包
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
X = np.arange(1, 11).reshape(-1, 2)
X输出结果:
array([[ 1, 2],
[ 3, 4],
[ 5, 6],
[ 7, 8],
[ 9, 10]])poly = PolynomialFeatures(degree=2)
poly.fit(X)
X2 = poly.transform(X)
X2.shape # 显示:(5, 6)
X2输出结果:
array([[ 1., 1., 2., 1., 2., 4.],
[ 1., 3., 4., 9., 12., 16.],
[ 1., 5., 6., 25., 30., 36.],
[ 1., 7., 8., 49., 56., 64.],
[ 1., 9., 10., 81., 90., 100.]])注:
此时,可以看出当数据维度是2维是,经过多项式预处理生成了6维数据,第一列很显然是0次项系数,第二列和第三列也很好理解,分别是x1,x2,第四列和第六列分别是 x1^2,x2^2 ,还有一列,其实是x1*x2,这就是第5列,总共6列。由此可以猜想一下如果数据是3维的时候是什么情况?
poly = PolynomialFeatures(degree=3)
poly.fit(X)
X3 = poly.transform(X)
X3.shape # 显示:(5, 10)
X3输出结果:
array([[ 1., 1., 2., 1., 2., 4., 1., 2., 4.,
8.],
[ 1., 3., 4., 9., 12., 16., 27., 36., 48.,
64.],
[ 1., 5., 6., 25., 30., 36., 125., 150., 180.,
216.],
[ 1., 7., 8., 49., 56., 64., 343., 392., 448.,
512.],
[ 1., 9., 10., 81., 90., 100., 729., 810., 900.,
1000.]])通过PolynomiaFeatures,将所有的可能组合,升维的方式呈指数型增长。这也会带来一定的问题。 如何解决这种爆炸式的增长?
如果不控制一下,试想x和x[^100]相比差异就太大了。这就是传说中的过拟合。
五、sklearn中的Pipeline
一般情况下,我们会对数据进行归一化,然后进行多项式升维,再接着进行线性回归。因为sklearn中并没有对多项式回归进行封装,不过可以使用Pipeline对这些操作进行整合。
# 导包
import numpy as np
import matplotlib.pyplot as plt
x = np.random.uniform(-3, 3, size = 100)
X = x.reshape(-1, 1)
y = 0.5 * x**2 + x + 2 + np.random.normal(0, 1, size=100)
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
# Pipeline
poly_reg = Pipeline([
("poly", PolynomialFeatures(degree=2)),
("std_scaler", StandardScaler()),
("lin_reg", LinearRegression())
]) # 列表,每个类,元祖形式 三步走 方便
# 训练并预测
poly_reg.fit(X, y)
y_predict = poly_reg.predict(X)
# 绘制散点图
plt.scatter(x, y)
plt.plot(np.sort(x), y_predict[np.argsort(x)], color='r')
plt.show()输出结果:
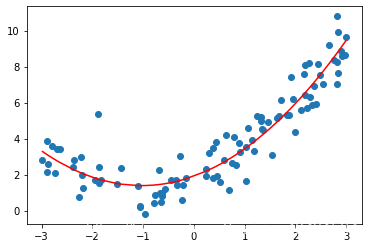
结果和之前的完全一样!!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









