










编辑:陈萍萍的公主@一点人工一点智能
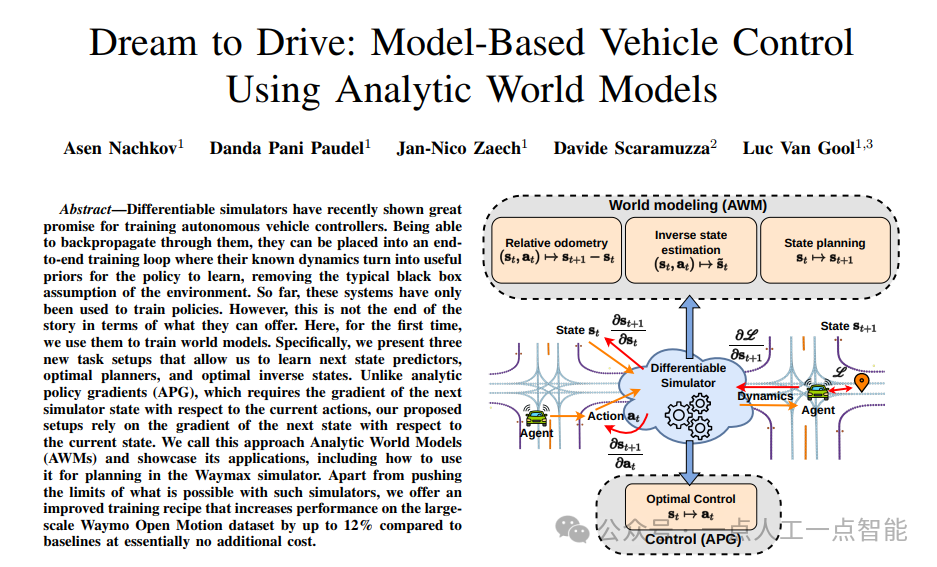
本文提出了一种基于可微分仿真器的自动驾驶车辆控制方法,首次将可微分仿真应用于世界模型(World Model)的训练。通过引入解析世界模型(Analytic World Models, AWMs),作者设计了三种新任务——相对里程计预测、最优状态规划和逆最优状态估计,旨在解决传统基于策略的模型(如APG)在规划能力与可解释性上的不足。
实验表明,结合改进的训练策略(如熵正则化与可微分碰撞检测),该方法在Waymax仿真器和Waymo Open Motion数据集上实现了比基线模型高达12%的性能提升,且计算成本相当。
01 引言
近年来,可微分仿真器在机器人、物理模拟和自动驾驶领域展现了巨大潜力。其核心优势在于允许通过反向传播直接优化策略或模型参数,避免了传统黑盒环境下的低效搜索。然而,现有研究多聚焦于反应式策略(Reactive Policy)的训练,缺乏对规划能力的探索。
本文首次提出将可微分仿真器用于世界模型的训练,旨在通过解析环境动态梯度,实现更高效、安全的自动驾驶规划。相较于传统模型预测控制(MPC)需大量试错,本文方法通过直接利用仿真器的梯度信息,显著提升了样本效率与物理一致性。研究还改进了训练策略,如限制训练周期防止过拟合、引入熵正则化增强策略多样性,并通过可微分高斯重叠近似优化碰撞检测,进一步提升了模型性能。
02 方法
2.1 任务设计
1)相对里程计(Relative Odometry):
预测执行动作后的状态偏移量。通过构造损失函数
,利用仿真器梯度优化预测器,实现无需黑盒搜索的高效学习。
2)最优规划(Optimal Planners):
直接预测下一目标状态,并通过逆运动学(InvKin)求解最优动作。公式
确保规划路径与专家轨迹对齐。
3)逆最优状态估计(Inverse State Estimation):
求解“在当前状态下,执行给定动作需调整至何种状态才能达到最优结果”。损失函数通过梯度反传优化状态修正量,为动作提供可解释的置信度评估。
2.2 架构与规划
· 多模态融合:通过RNN整合道路拓扑、交通信号、车辆位置等信息,生成统一潜在状态表征。
· 模型预测控制(MPC):基于AWMs自回归生成多条虚拟轨迹,通过奖励模型评估后选择最优动作序列(见图4)。相较于传统MPC,本文方法利用仿真器梯度信息显著减少计算开销。
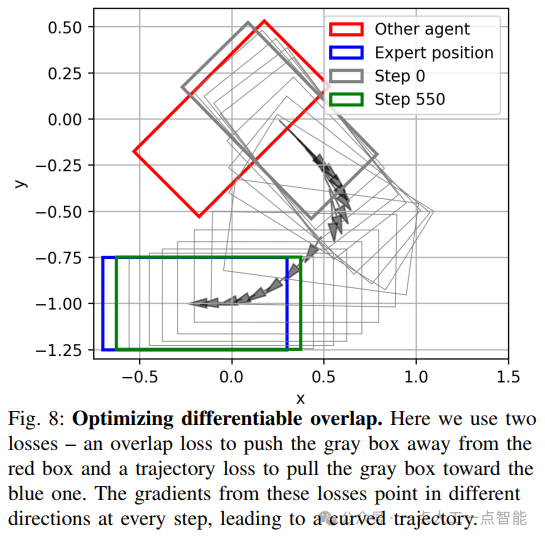
· 可微分碰撞检测:将车辆近似为二维高斯分布,通过密度重叠计算碰撞损失,实现端到端优化。
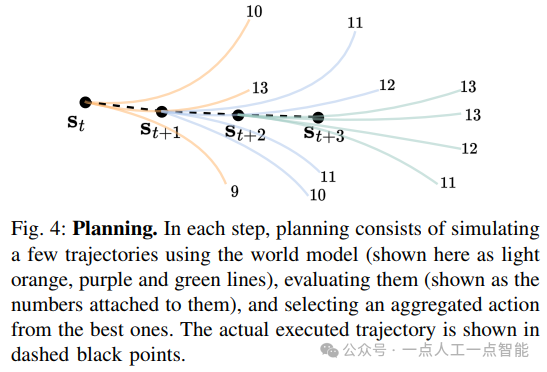

03 实验
本文主要介绍了在交通场景下使用神经网络进行决策和规划的实验研究。作者进行了多个独立的实验来评估不同的方法和技术,并提供了详细的实验结果和分析。
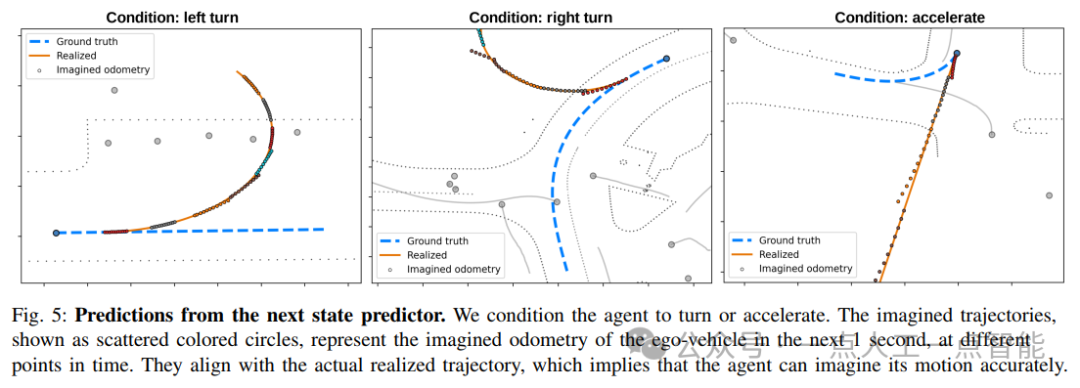
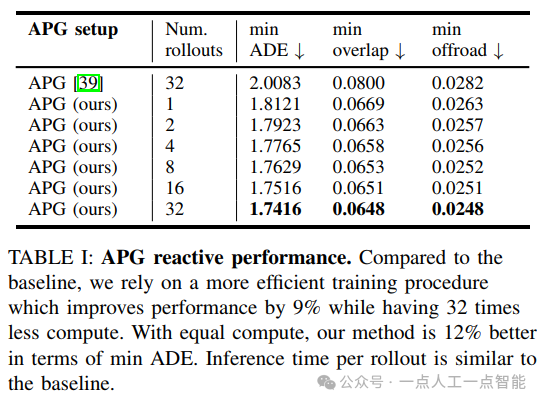
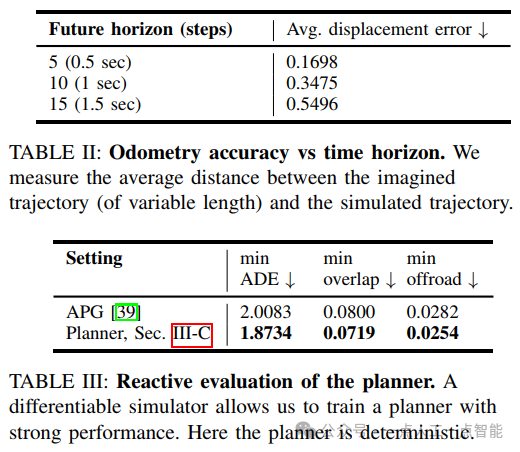
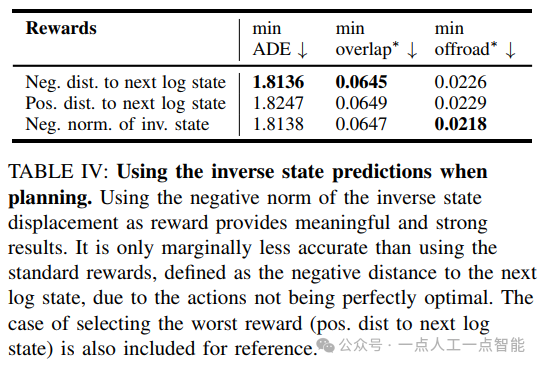
首先,作者对四个任务进行了独立的评估,包括最优控制、相对位移预测、最优路径规划和逆向状态预测。每个任务都采用了不同的评估指标和分数,如最小平均距离误差(minADE)、最小重叠率和最小离路率等。通过这些评估指标,作者可以比较不同方法和技术的表现,并得出一些有用的结论。
其次,作者还进行了多项实验来进一步评估和改进他们的方法。例如,在最优路径规划方面,作者增加了虚拟轨迹的数量以提高性能,并发现增加数量的效果很小但仍然可见。此外,作者还探索了路线条件化和可微分重叠损失等技术,并对其效果进行了评估。
最后,作者提供了详细的实现细节,包括训练细节、模型参数和推理速度等方面的信息。这些信息可以帮助其他研究人员更好地理解该方法的工作原理并进行相关研究。
04 讨论与结论
4.1 贡献与意义
本文首次将可微分仿真器应用于世界模型训练,提出三种新任务,实现了自动驾驶规划的物理一致性与高效性。改进后的训练策略显著提升性能,且方法兼容现有仿真框架(如Waymax),为安全驾驶提供了新思路。
4.2 局限性
· 多模态策略:专家轨迹单一性导致策略多样性受限;
· 传感器依赖:未融合原始摄像头数据,依赖中间表征(如道路拓扑);
· 碰撞优化:可微分碰撞与轨迹跟踪的梯度方向冲突,需权衡损失权重。
4.3 未来方向
本文提出的方法为解决自动驾驶中的一些挑战提供了一个有前途的方向。然而,仍有一些限制需要进一步研究。例如,当车辆只有一种专家轨迹时,多模式策略可能会退化成单模式策略。此外,虽然作者已经展示了如何使用不同的预测器来解决世界建模问题,但还需要更多的工作来开发更有效的策略来维护多模式随机策略。因此,在未来的研究中,需要进一步探索这些问题并提出解决方案。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











