






1. 项目简介
SmartETL:一个简单实用、灵活可配、开箱即用的Python数据处理(ETL)框架,提供Wikidata / Wikipedia / GDELT等多种开源情报数据的处理流程; 支持大模型、API、常见文件、数据库等多种输入输出及转换处理,支撑各类数据集成接入、大数据处理、离线分析计算、AI智能分析、知识图谱构建等任务。项目内置50+常用流程、180+常用ETL算子、10+领域特色数据处理流程,覆盖常见数据处理需求。
项目源码已经开放在https://github.com/ictchenbo/SmartETL,感兴趣的小伙伴可以直接拉取源码进行试用,并且这个项目我会持续丰富完善,也欢迎大家提出提意见或是直接提出数据处理需求,也可以一起来参与项目建设。
文本是《SmartETL:大模型赋能的开源情报数据处理框架》系列第二篇,主要对ETL基本知识进行回顾,讨论已有ETL存在什么问题。
2. ETL基本概念
ETL是指数据集成(Extract)、转换处理(Transform)、数据同步(Load)相关技术。ETL一度主要是作为数据仓库的前置技术,目的是从多源异构数据源进行数据加载和清洗,形成高质量的数据进入数据仓库,方便大规模数据OLAP分析。
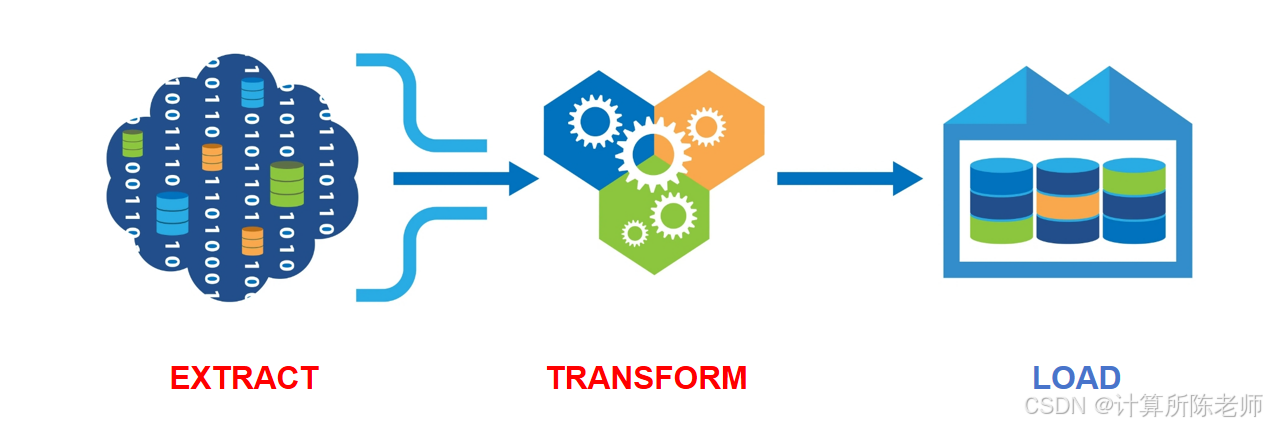
ETL中通常E和T是主要工作内容。E是对接多种不同数据源,包括各种类型的文件(json、csv、excel、word、pdf、pdf、eml等等),包括各种类型数据库(关系数据库MySQL、PostgreSQL、SQLServer……,NoSQL如MongoDB、ElasticSearch、Neo4j等等),以及消息队列(如Kafka、RabbitMQ),还有API(各种开放API以及项目内部API等),文件系统(本地文件系统、HDFS、MinIO、S3等),虽然数据源类型上最常见的就这些,但是因为每个都有很多,都需要不同的连接器,因此具体工程量非常巨大。T是ETL核心,起着从原始数据格式到目标数据库格式的结构转换、数据汇聚融合、清洗过滤、加工等各类过程,以前ETL大部分T算子较为简单,比如修改数据字段名、删除一些字段、添加一些字段前缀、对字段格式进行转换(如字符串时间转换为整数时间戳)等。但是面向情报分析应用,就会出现大量语义识别算子需求,如实体识别、事件抽取、主题分类等等,以及最新的基于大模型的一些识别、推理、分析等结果。L阶段很重要,主要是因为我们目标系统存储结构(数据库、数据仓库、数据湖或者混合异构、湖仓一体存储架构),基本上业务需求确定后,我们设计就会确定,并且为了减少管理复杂度,肯定是确定的一套存储结构。
3. ETL发展历程
ETL大概经历了几个发展阶段:
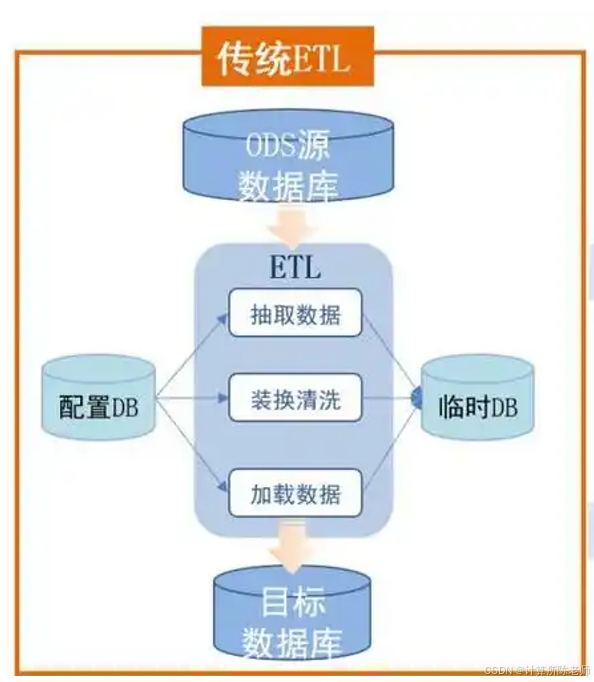
1. 传统ETL,就是朴素ETL,通过开发一套定制化的ETL程序,实现从源数据库将数据提取、清洗并装载到目标数据库。为了一定的灵活性,通过配置数据库进行配置,比如抽取的数据源、清洗规则(如基于正则表达式进行比对)、目标库表等。为了对中间数据进行记录,方便追溯和问题排查,增加临时数据库记录中间数据。
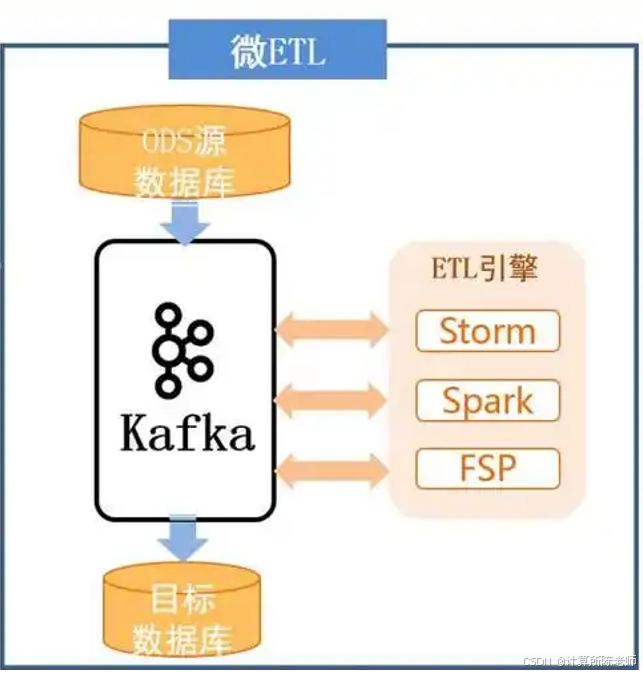
2. 微ETL,基于消息中间件的发布订阅模式。传统ETL虽然简单直观,但是随着业务复杂,处理流程越来越复杂,就会出现很多ETL程序或版本分支(GoIN目前预处理就是有这样的问题),同时各个ETL程序在E和T部分实际上是大量重复的,通常只需要维护一套。这时候出现了基于消息中间件(如Kafka)的发布-订阅式ETL,即数据源统一写入Kafka,数据处理程序和加载程序都对Kafka消息进行订阅。这种消息总线将源数据和目标数据解耦了,并且在处理方面可以利用消息分组机制很容易扩展性能,因此一度是比较流行的ETL架构。
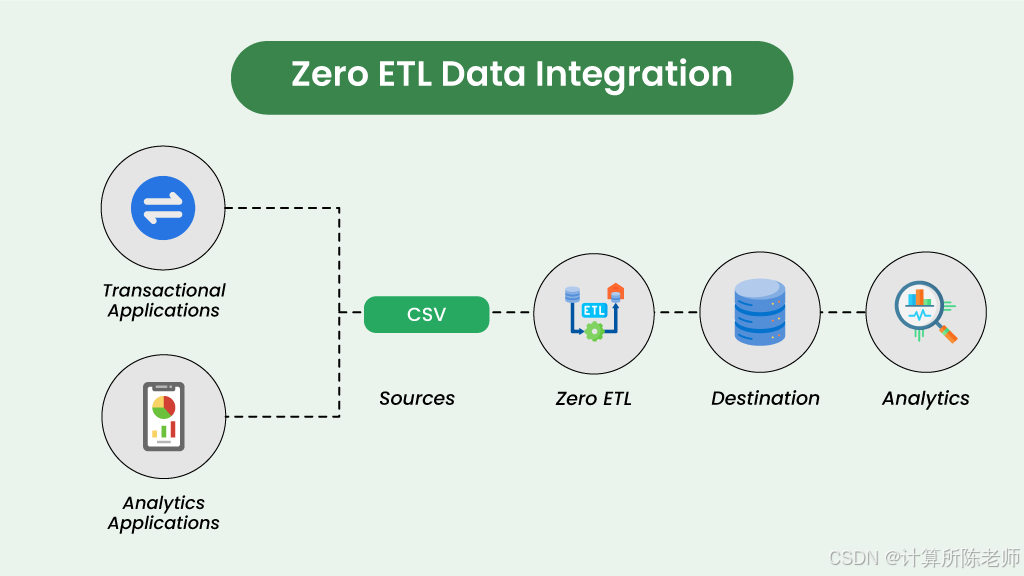
3. noETL或zeroETL阶段,顾名思义,就是完全不需要传统上的ETL过程的数据分析阶段,在分析计算时直接访问各类数据源并实现快速计算。这在某些需要经常更换数据源或无法获得全量原始数据(可能由于权限隔离的原因,源数据只能按需访问)的场景下非常有用。
其他相相关关概念还有:
(1)ELT,将T和L顺序进行交换,本质上由于存算分离等架构,使得目标数据系统具有较高的计算性能,因此可以将数据不做处理或做非常简单的处理即入库,在应用分析时直接计算,实现灵活的分析计算。
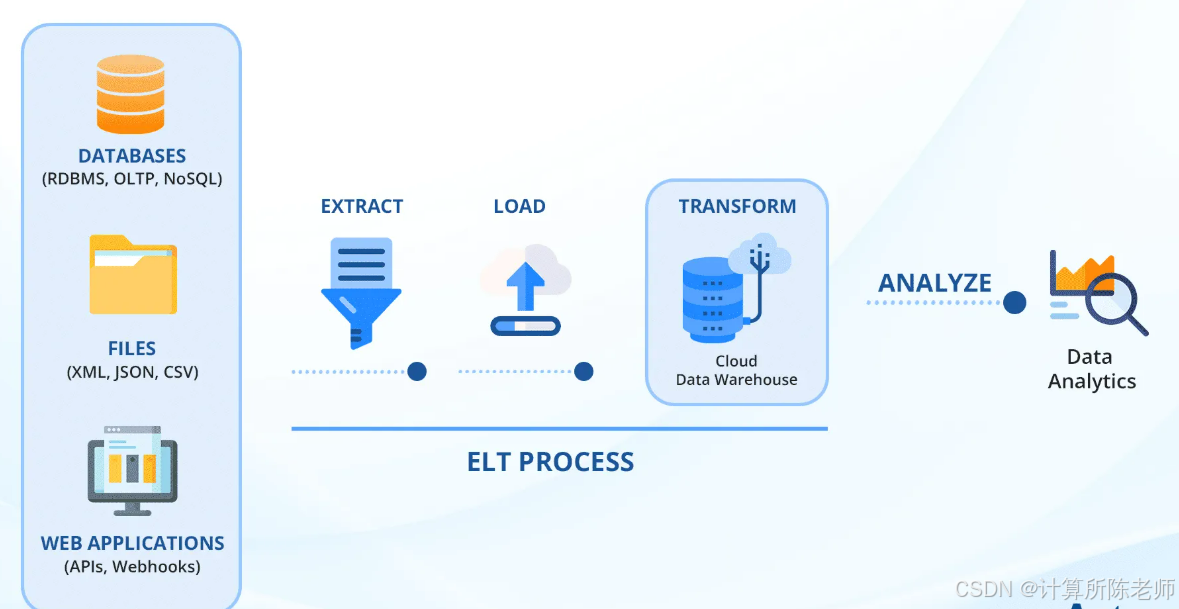
(2)逆ETL,是将ETL反过来,将数据仓库作为数据源,通过数据转换处理,最后将数据加载到操作型数据库中。
4. ETL性能考虑
对于传统ETL,为了提升处理性能,几个方式:
- 多线程,充分利用CPU多核能力
- 多进程,克服多线程存在的资源竞争问题,进一步提高CPU利用率
- 手工分布式,通过横向增加服务器,手工划分数据进行并行处理,提升性能
- 基于分布式计算框架,利用Hadoop MapReduce、Spark、Flink、Storm等分布式计算框架提升。
在10多年前参与的ADA系统中,就是采用了MapReduce实现大规模网页信息知识抽取,但是时延比较严重。后来换成了Kafka+Storm的流式微ETL架构,缩短了数据处理延迟并提升了整体处理性能。
基于消息中间件的微ETL架构一方面是在软件接口方面实现了数据源与目标数据库的解耦,大家只要在业务数据结构上进行统一即可,另外一方面的优势在于性能可弹性扩展。如果数据量非常大,可以对Kafka进行横向扩展,增加broker和分区数量,消费者读取数据的时候将随机访问一个分区,由于消费者可以灵活地选择多线程、多进程、分布式计算框架等进行实现,数据处理性能非常容易扩展。
5. 当前ETL问题
基于目前数据预处理/数据治理相关工作,主要问题可以总结成几个方面:
- 维护困难:已有ETL处理散落在多个Python项目分支和大量代码片段中,相关研发人员经常会临时建立一个新的项目进行数据处理,时间久了之后,可能连他自己都不记得具体逻辑,交接就更为困难,往往需要重新梳理代码逻辑
- 复用困难:由于已有的ETL零散无法有效维护,因此也难以有效复用,在新项目中或者基于一个大项目建立新的分支,或者另起炉灶,最后发现很多重复的代码,浪费很多精力。数据处理需求较为复杂时,往往需要花费大量时间,且中间总是出现这样或那样的问题。
- 性能低下:很多研发人员由于基本简答粗暴的方式进行处理,虽然短时间节省了时间,但是性能往往比较低下,难以应对大规模数据场景,导致客户抱怨。基于大数据计算框架(如Spark Flink等)进行设计开发,可以比较容易解决性能问题,但对很多研发人员来说门槛较高,且不容易优化性能。在很多公司,大数据开发和后台研发是分工明确的两个岗位,小团队可能根本没有大数据岗位。
- 实施周期长:ETL往往需要进行业务分析、数据分析、数据建模设计、处理流程设计、编码开发、调试、部署等复杂过程,导致实施周期比较长。尽管这个过程前面部分往往是必需的,但是如果能够提高在流程设计、编码开发等阶段的时间,就可以缩短总的实施周期。
尽管ETL技术持续发展,已经有一些noETL的趋势,但是要为了持续积累高质量数据,有效支撑应用分析,开展ETL技术研究仍然是非常必要的。同时,结合目前存在问题,提出以下需求,作为框架的研究动机:
- 如何实现开箱即用?能否针对一类情报分析场景(如开源情报)持续积累开箱即用的ETL数据处理流程?显然,如果只做框架是没法做到开箱即用的。
- 如何对复杂流程进行管理?由于目前的流程逻辑散步在大量源代码中,因此无法有效管理流程。需要设计一个抽象层用来表示流程,实现业务逻辑一目了然。
- 如何实现流程灵活可配?对相应场景的大部分处理任务,应该能够通过低代码或无代码的方式进行流程配置,并支持随时可修改,从而应对各种各样业务需求。此外基础算子必须非常丰富,基于丰富的算子库才能实现流程灵活可配。
- 如何实现性能弹性扩展?框架既要比较简单,可以快捷启动运行,也可以与分布式计算框架进行对接,从而实现性能提升。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









