




 本文详细解析了HashMap、LinkedHashMap及TreeMap的区别,探讨了HashMap的线程安全性问题,深入分析了HashMap的部分源码,包括如何确定记录位置、插入元素过程及解决哈希冲突的方法。
本文详细解析了HashMap、LinkedHashMap及TreeMap的区别,探讨了HashMap的线程安全性问题,深入分析了HashMap的部分源码,包括如何确定记录位置、插入元素过程及解决哈希冲突的方法。
Java面试---HashMap
HashMap,LinkedHashMap,TreeMap的区别
HashMap将根据key的hashCode值来找到存储value的位置,如果hash函数比较完美的话,因为可以很快的找到key对应的value存储的位置,所以具有很高的效率,需要注意的一点是,HashMap因为是基于key的hashCode值来存储value的,所以遍历HashMap不会保证它的顺序和插入时的顺序一致,可以说很大概率这个顺序是不一致的,所以如果需要保持插入顺序,你不可以选择HashMap。还要一点是HashMap允许key为null,但是只允许有一个key为null,再次说明,HashMap不是线程安全的,并发环境下你应该首选ConcurrentHashMap,ConcurrentHashMap是一种高效的并发Map,它是线程安全版本的HashMap。
LinkedHashMap是HashMap的子类,它将保持记录的插入顺序。
TreeMap实现了SortedMap接口,很明显,他将对插入的记录排序,在遍历TreeMap的时候,得到的是经过排序的记录,所以,如果你需要对插入的记录做排序的话,选择TreeMap,然后指定比较器就可以了
HashMap线程不安全
在并发环境下,可能同一时刻有多个线程在操作HashMap,因为HashMap中没有任何措施来保护table,所以在并发环境下多个线程是可以同时操作table的,那么比如在put的时候触发了HashMap扩容,那么在扩容的过程中多个线程的原因可能在某个table的index上会形成一个链表的环,那么此后如果有线程通过get来获取记录的时候,如果刚好这个记录在这个环之后,那么获取记录的线程就会造成死循环。
HashMap部分源码分析
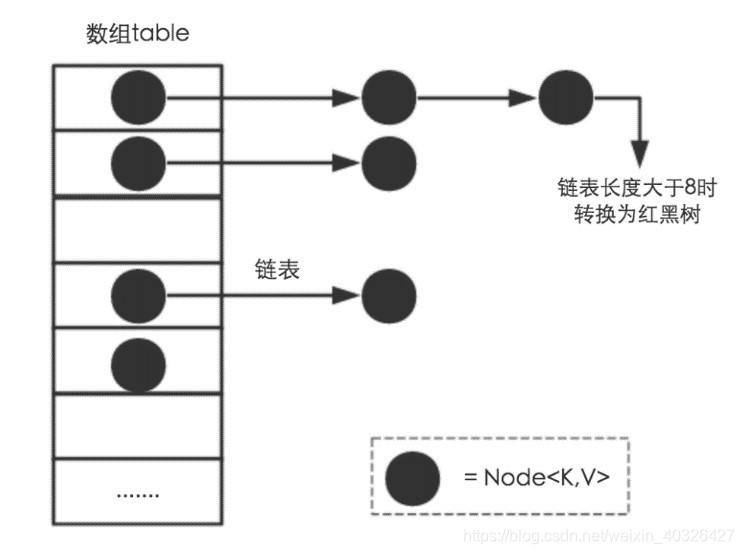
HashMap是通过计算key的hashCode来找到记录的存储位置的,那因为hash函数不会台完美的原因,势必要造成多个记录的key的hashCode一样的情况,上图展示了这种情况,完美情况下,我们希望每一个数组位置上仅有一个记录,但是很多情况下一个数组位置上会落入多个记录,也就是哈希冲突,解决哈希冲突的方法主要有开发地址和链地址,HashMap采用了后者,将hashCode相同的记录放在同一个数组位置上,多个hashCode相同的记录被存储在一条链表上,我们知道,链表上的查询复杂的为O(N),当这个N很大的时候也就成了瓶颈,所以HashMap在链表的长度大于8的时候就会将链表转换为红黑树这种数据结构,红黑树的查询效率高达O(lgN),也就是说,复杂度降了一个数量级,完全可以适用于实际生产环境。下面是链表节点数据结构的代码:
// An highlighted block
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; //哈希值,HashMap用这个值来确定记录的位置
final K key; //记录key
V value; //记录value
Node<K,V> next;//链表下一个节点
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
下面是上图中展示的数组:
transient Node<K,V>[] table;
HashMap如何确定记录的table位置?
要确定记录在table中的index,然后才能去table的index上的链表或者红黑树里面去寻找记录。下面的方法hash展示了HashMap是如何计算记录的hashCode值的方法:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
上面的hash方法仅仅是第一步,它只是计算出了hashCode值,但是还可以确定table中的index,接下来的一步需要做的就是根据hashCode来定位index,也就是需要对hashCode取模(hashCode % length),length是table的长度,但是我们知道,取模运算是较为复杂的计算,是非常耗时的计算,那有没有方法不通过取模计算而达到取模的效果呢,答案是肯定的,上文中提到,table的长度必然是2的n次方,这点很重要,HashMap通过设定table的长度为2的n次方,在取模的时候就可以通过下面的算法来进行:
int index = hashCode & (length -1)
HashMap插入元素的过程详解?
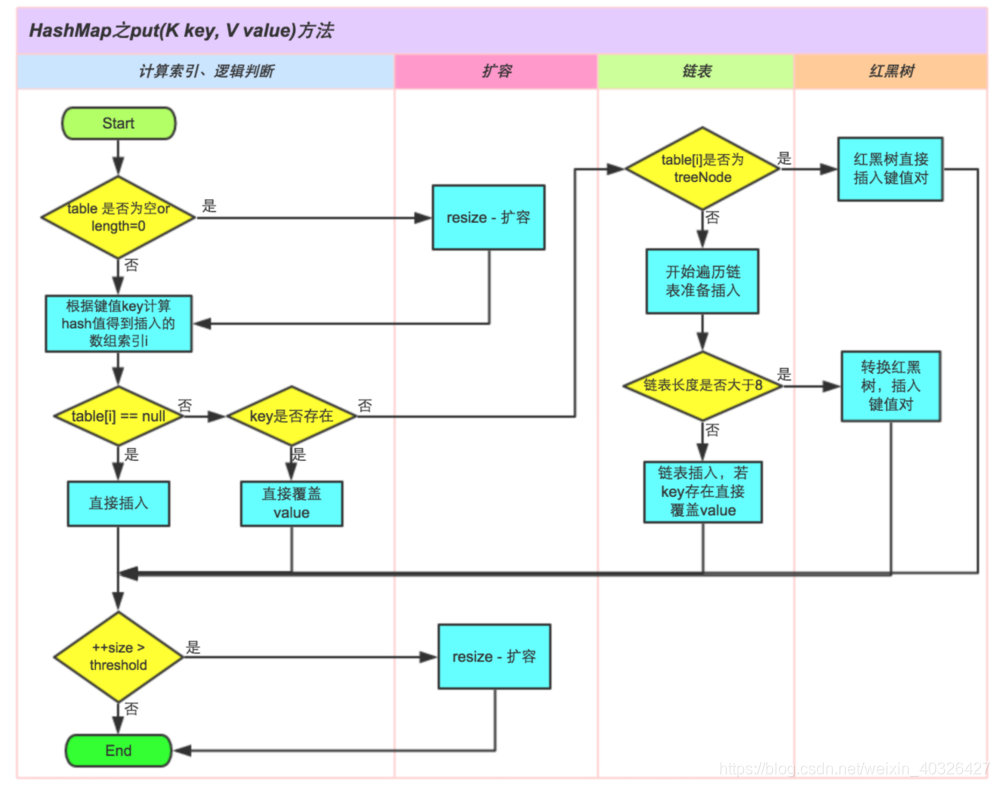 1. 首先判断table是否为null或者长度为0,如果是,那么调用方法resize来初始化table,resize的细节将在下文中进行分析,这个方法用来对HashMap的table数组扩容,它将发生在初始化table以及table中的记录数量达到阈值之后。
1. 首先判断table是否为null或者长度为0,如果是,那么调用方法resize来初始化table,resize的细节将在下文中进行分析,这个方法用来对HashMap的table数组扩容,它将发生在初始化table以及table中的记录数量达到阈值之后。
2. 然后计算记录的hashCode,以及根据上文中提到的方法来计算记录在table中的index,如果发现index未知上为null,则调用newNode来创建一个新的链表节点,然后放在table的index位置上,此时表面没有哈希冲突。
3. 如果table的index位置不为空,那么说明造成了哈希冲突,这时候如果记录和index位置上的记录相等,则直接覆盖,否则继续判断
4. 如果index位置上的节点TreeNode,如果是,那么说明此时的index位置上是一颗红黑树,需要调用putTreeVal方法来将这新的记录插入到红黑树中去。否则走下面的逻辑。
5. 如果index位置上的节点类型不是TreeNode,那么说明此位置上的哈希冲突还没有达到阈值,还是一个链表结构,那么就根据插入链表插入新节点的算法来找到合适的位置插入,这里面需要注意的是,新插入的记录会覆盖老的记录,如果这个新的记录是首次插入,那么就会插入到该index位置上链表的最尾部,这里面还需要一次判断,如果插入了新的节点之后达到了阈值,那么就需要调用方法treeifyBin来讲链表转化为红黑树。
6. 在插入完成之后,哈希桶中记录的数量是否达到了哈希桶设置的阈值,如果达到了,那么就需要调用方法resize来扩容。

















 5673
5673

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









