






 本文详细探讨了特征工程的重要性,包括特征抽取(字典与文本)、数据预处理(归一化、标准化与缺失值处理)、特征选择(VarianceThreshold)以及降维技术(主成分分析)。通过实例演示了如何应用sklearn进行特征操作,提升机器学习模型性能。
本文详细探讨了特征工程的重要性,包括特征抽取(字典与文本)、数据预处理(归一化、标准化与缺失值处理)、特征选择(VarianceThreshold)以及降维技术(主成分分析)。通过实例演示了如何应用sklearn进行特征操作,提升机器学习模型性能。
文章目录
1、特征工程是什么
特征工程是将原始数据转换为更好地代表预测模型的潜在问题的特征的过程,从而提高了对未知数据的模型准确性
2、特征工程的意义
直接影响模型的预测结果。
机器学习无需对重复值进行处理,但是对文本、字符需要进行处理,特征值化是为了计算机更好的去理解数据。
3、数据的特征抽取
1、特征抽取针对非连续型数据
2、特征抽取对文本等进行特征值化
3、用sklearn.feature_extraction
3.1 字典特征抽取
类:sklearn.feature_extraction.DictVectorizer
实例化:
DictVectorizer(sparse=True,…)
方法:
DictVectorizer.fit_transform(X)
X:字典或者包含字典的迭代器
返回值:返回sparse矩阵
DictVectorizer.inverse_transform(X)
X:array数组或者sparse矩阵
返回值:转换之前数据格式
DictVectorizer.get_feature_names()
返回类别名称
DictVectorizer.transform(X)
按照原先的标准转换
from sklearn.feature_extraction import DictVectorizer
def dictvec():
"""
字典数据抽取
:return: None
"""
# 实例化
dict = DictVectorizer(sparse=False)
# 调用fit_transform
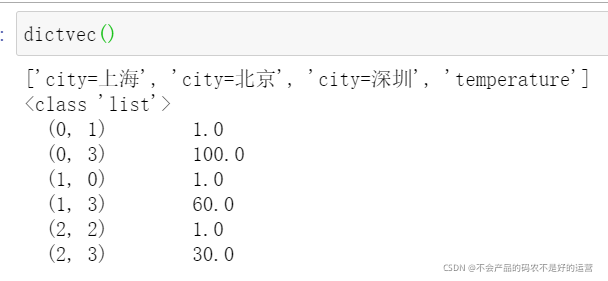
data = dict.fit_transform([{'city': '北京','temperature': 100}, {'city': '上海','temperature':60}, {'city': '深圳','temperature': 30}])
print(dict.get_feature_names())
print(dict.inverse_transform(data))
print(data)
return None
sparse = False:意思是不产生稀疏矩阵,此时data的type是<class ‘numpy.ndarray’>
 sparse = True,此时data的type是<class ‘scipy.sparse.csr.csr_matrix’>
sparse = True,此时data的type是<class ‘scipy.sparse.csr.csr_matrix’>
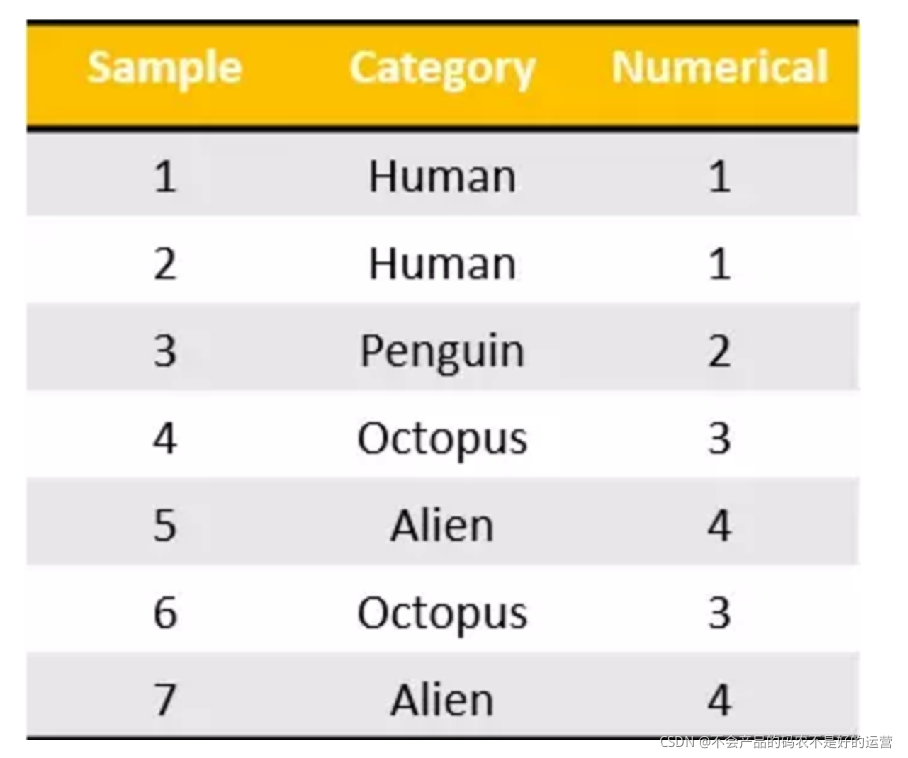
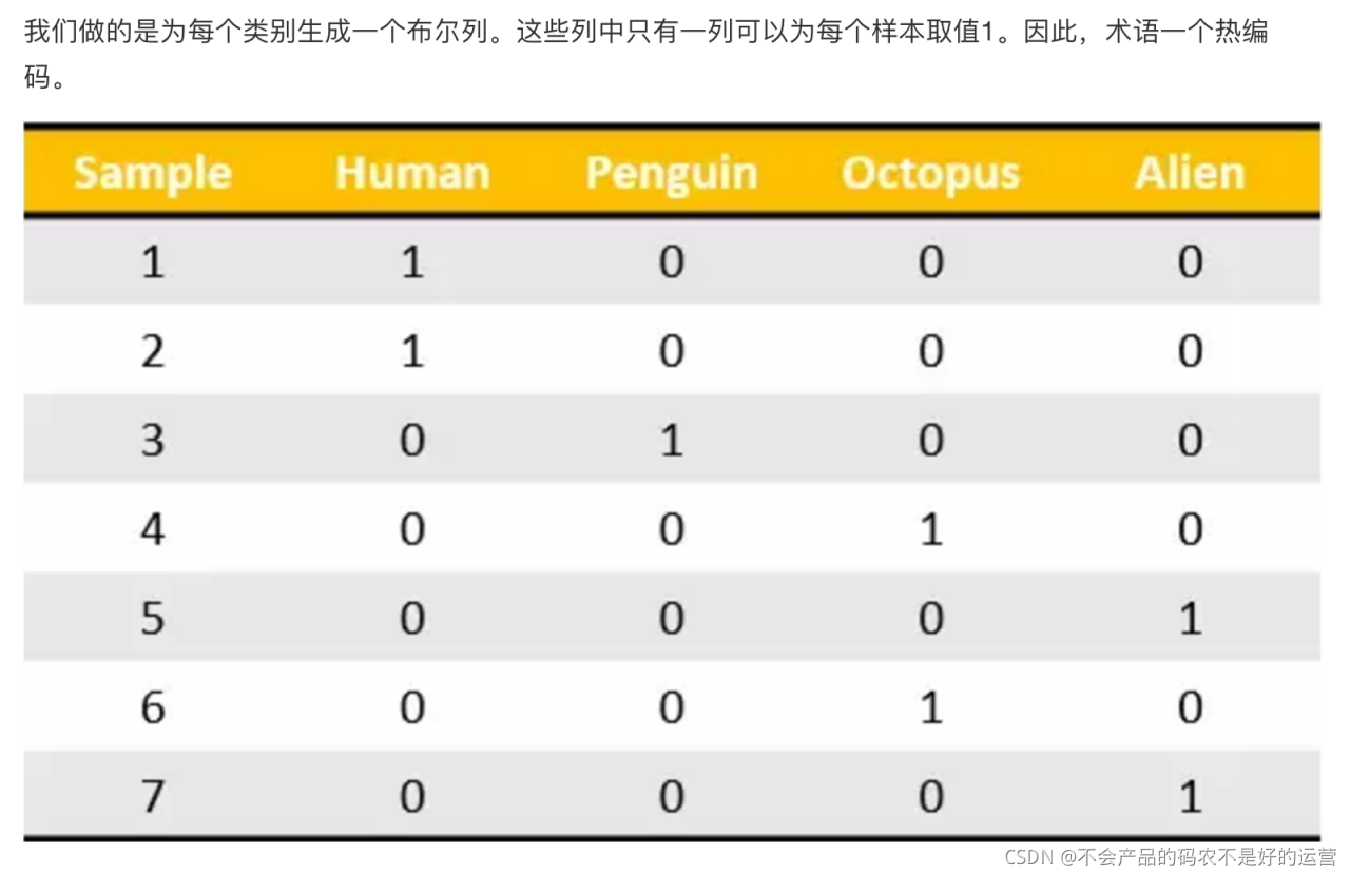
one-hot编码:
3.2 文本特征抽取
对文本数据进行特征值化
类:sklearn.feature_extraction.text.CountVectorizer
CountVectorizer(max_df=1.0,min_df=1,…)
返回词频矩阵
CountVectorizer.fit_transform(X,y)
X:文本或者包含文本字符串的可迭代对象
返回值:返回sparse矩阵
CountVectorizer.inverse_transform(X)
X:array数组或者sparse矩阵
返回值:转换之前数据格式
CountVectorizer.get_feature_names()
返回值:单词列表
def countvec():
"""
对文本进行特征值化
:return: None
"""
cv = CountVectorizer()
data = cv.fit_transform(["人生 苦短,我 喜欢 python", "人生漫长,不用 python"])
print(cv.get_feature_names())
print(data.toarray())
return None

- 其中fit_transform(X)中的x需得用空格分开,因为英文中文章都是按空格风格单词的,因此中文没分开需要先分词;
- 单个汉字、字母不进行统计
import jieba
def cutword():
con1 = jieba.cut("今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。")
con2 = jieba.cut("我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。")
con3 = jieba.cut("如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。")
# 转换成列表
content1 = list(con1)
content2 = list(con2)
content3 = list(con3)
# 吧列表转换成字符串
c1 = ' '.join(content1)
c2 = ' '.join(content2)
c3 = ' '.join(content3)
return c1, c2, c3
def hanzivec():
"""
中文特征值化
:return: None
"""
c1, c2, c3 = cutword()
print(c1, c2, c3)
cv = CountVectorizer()
data = cv.fit_transform([c1, c2, c3])
print(cv.get_feature_names())
print(data.toarray())
return None
一种文本分类的算法,tf-idf:
-
思想:如果某个词或短语在一篇文章中出现的概率高,
并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。 -
作用:用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度
类:sklearn.feature_extraction.text.TfidfVectorizer
TfidfVectorizer(stop_words=None,…)
返回词的权重矩阵
TfidfVectorizer.fit_transform(X,y)
X:文本或者包含文本字符串的可迭代对象
返回值:返回sparse矩阵
TfidfVectorizer.inverse_transform(X)
X:array数组或者sparse矩阵
返回值:转换之前数据格式
TfidfVectorizer.get_feature_names()
返回值:单词列表
def tfidfvec():
"""
中文特征值化
:return: None
"""
c1, c2, c3 = cutword()
print(c1, c2, c3)
tf = TfidfVectorizer()
data = tf.fit_transform([c1, c2, c3])
print(tf.get_feature_names())
print(data.toarray())
return None
4、数据的特征处理
通过特定的统计方法(数学方法)将数据转换成算法要求的数据
4.1 方法
1、数值型数据::标准缩放:
4.1.1 归一化
通过对原始数据进行变换把数据映射到(默认为[0,1])之间
特征同等重要时运用归一化,目的是使某一个特征不会对预测结果有很大的影响,比如一个特征的样本值都在10000以上,其它特征的样本值在10左右。
最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性较差,只适合传统精确小数据场景。
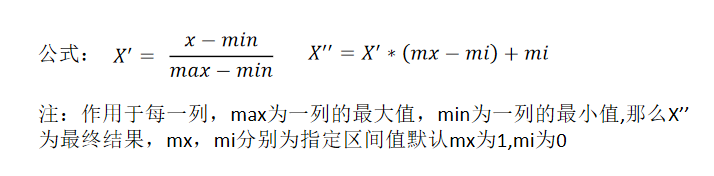
方法:sklearn.preprocessing.MinMaxScaler
MinMaxScalar(feature_range=(0,1)…)
每个特征缩放到给定范围(默认[0,1])
MinMaxScalar.fit_transform(X)
X:numpy array格式的数据[n_samples,n_features]
返回值:转换后的形状相同的array
def mm():
"""
归一化处理
:return: NOne
"""
mm = MinMaxScaler(feature_range=(0, 1))
data = mm.fit_transform([[90,2,10,40],[60,4,15,45],[75,3,13,46]])
print(data)
return None
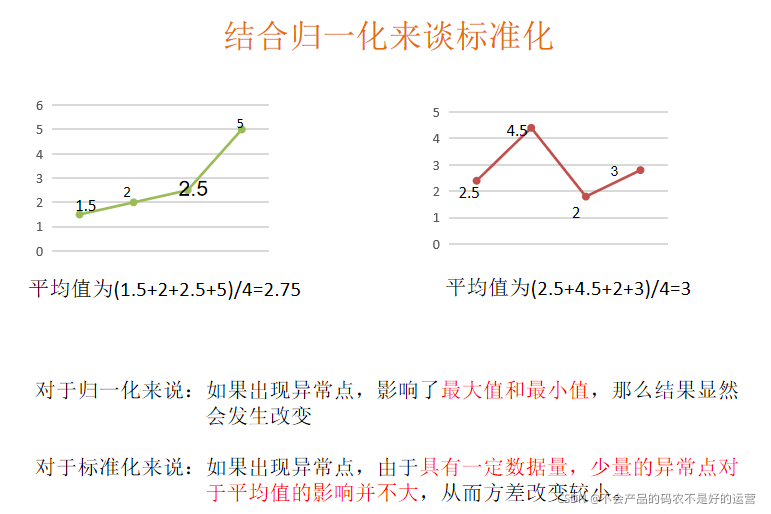
4.1.2、标准化
通过对原始数据进行变换把数据变换到均值为0,方差为1范围内
在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。

scikit-learn.preprocessing.StandardScaler
StandardScaler(…)
处理之后每列来说所有数据都聚集在均值0附近方差为1
StandardScaler.fit_transform(X,y)
X:numpy array格式的数据[n_samples,n_features]
返回值:转换后的形状相同的array
StandardScaler.mean_
原始数据中每列特征的平均值
StandardScaler.std_
原始数据每列特征的方差
def stand():
"""
标准化缩放
:return:
"""
std = StandardScaler()
data = std.fit_transform([[ 1., -1., 3.],[ 2., 4., 2.],[ 4., 6., -1.]])
print(data)
return None
4.1.3、缺失值
要么删除,要么填充(一般按特征填充)
一般用pandas进行缺失值处理,缺失值数据类型为np.nan,float类型,如果不是np.nan而是空字符串这种,需要先使用repalce(’’,np.nan),然后再用pd.fillna(…)
sklearn.preprocessing.Imputer
Imputer(missing_values='NaN', strategy='mean', axis=0(按特征值填充))
完成缺失值插补
Imputer.fit_transform(X,y)
X:numpy array格式的数据[n_samples,n_features]
返回值:转换后的形状相同的array
def im():
"""
缺失值处理
:return:NOne
"""
# NaN, nan
im = Imputer(missing_values='NaN', strategy='mean', axis=0)
data = im.fit_transform([[1, 2], [np.nan, 3], [7, 6]])
print(data)
return None
2、类别型数据::one-hot编码
3、时间类型: 时间的切分
4.2 API
sklearn. preprocessing
5、数据的特征选择
需要选择的原因:
- 冗余:部分特征的相关度高,容易消耗计算性能
- 噪声:部分特征对预测结果有负影响
特征选择就是单纯地从提取到的所有特征中选择部分特征作为训练集特征,特征在选择前和选择后可以改变值、也不改变值,但是选择后的特征维数肯定比选择前小,毕竟我们只选择了其中的一部分特征。
5.1 特征选择方法
5.1.1 Filter(过滤式):VarianceThreshold
VarianceThreshold(threshold = 0.0)
删除所有低方差特征
Variance.fit_transform(X,y)
X:numpy array格式的数据[n_samples,n_features]
返回值:训练集差异低于threshold的特征将被删除。
默认值是保留所有非零方差特征,即删除所有样本中具有相同值的特征。
def var():
"""
特征选择-删除低方差的特征
:return: None
"""
var = VarianceThreshold(threshold=1.0)
data = var.fit_transform([[0, 2, 0, 3], [0, 1, 4, 3], [0, 1, 1, 3]])
print(data)
return None
5.1.2 Embedded(嵌入式):正则化、决策树
5.1.3 Wrapper(包裹式)
6、降维
6.1 主成分分析法
本质:PCA是一种分析、简化数据集的技术,当特征数量达到上百时,考虑降维
目的:是数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量信息。
作用:可以削减回归分析或者聚类分析中特征的数量

PCA(n_components=None)
将数据分解为较低维数空间
PCA.fit_transform(X)
X:numpy array格式的数据[n_samples,n_features]
返回值:转换后指定维度的array
n_components:
小数 0-1 如0.9表示保留90%信息
整数(较少用到):减少到的特征数量
def pca():
"""
主成分分析进行特征降维
:return: None
"""
pca = PCA(n_components=0.9)
data = pca.fit_transform([[2,8,4,5],[6,3,0,8],[5,4,9,1]])
print(data)
return None


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









