







Mask R-CNN论文笔记
该文章基于How to Read a Paper中的方法来编写
第一阶段(5-10分钟)
题目
Mask R-CNN
摘要
- 为物体实例分割提出了一个概念简单、灵活并且通用的框架
- 同时在一张图片中①检测物体和②为每一个实例生成高质量的分割
- 继承于Faster R-CNN,在Faster R-CNN的基础上添加了一个分支用于预测分割mask
- 比Faster RCNN速度稍慢一店点,达到了5fps
- 泛化能力强
1. 简介
- 实例分割(instance segmentation)是物体检测(object detection)和语义分割(sementic segmentation)的结合
- 在Faster RCNN的基础上,添加了一个分支来为每个感兴趣区域(RoI)预测分割mask
- 这个mask分支是一个全卷积网络(FCN),应用到每一个ROI上预测分割mask
- 分割与检测任务是同时进行的
- Faster RCNN不是为输入输出像素对齐设计的,在ROIPool中表现很差,而ROI池是处理实例的核心操作,所以引入了RoI Align来修正ROIPool的偏差。
- 使用RoI Align后mask的影响:
- 精度从10%显著提高到50%
- 解耦了mask预测和类预测。mask分支只做mask分割预测,类型预测的任务交给ROI分类分支去做。而原始的FCN采用逐像素多类分类的方法,对图像进行分割的同时也进行分类,实验证明该方法实例分割效果不佳
- 模型在GPU上运行每帧大约200ms,在8-GPU的机器上运行一两天就可以完成COCO数据集的训练
- 通过对COCO keypoint数据集进行人体姿态估计,展示了该框架的通用性
第二阶段(长达一个小时)
- 仔细阅读论文中的图表和其他插图。
- 标记相关的未读参考文献以供进一步阅读(这是了解论文背景的好方法)
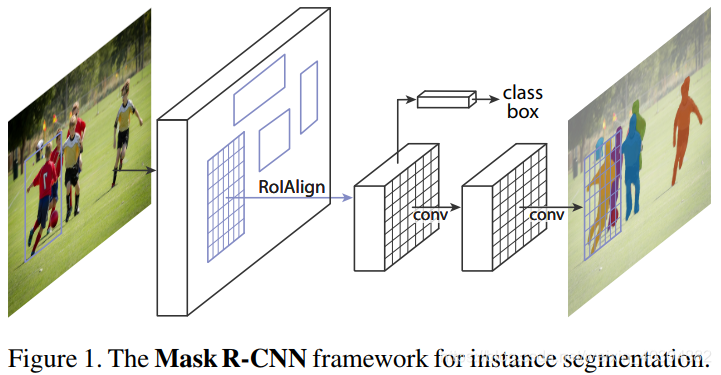


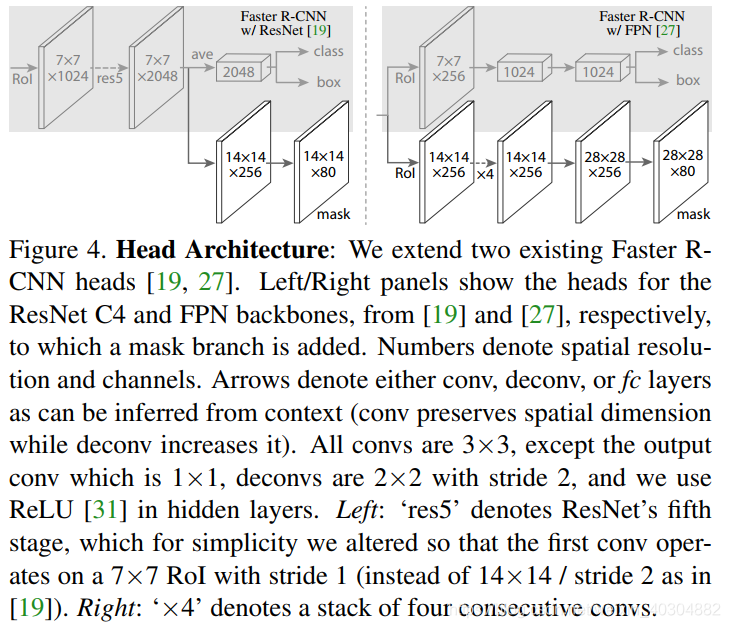

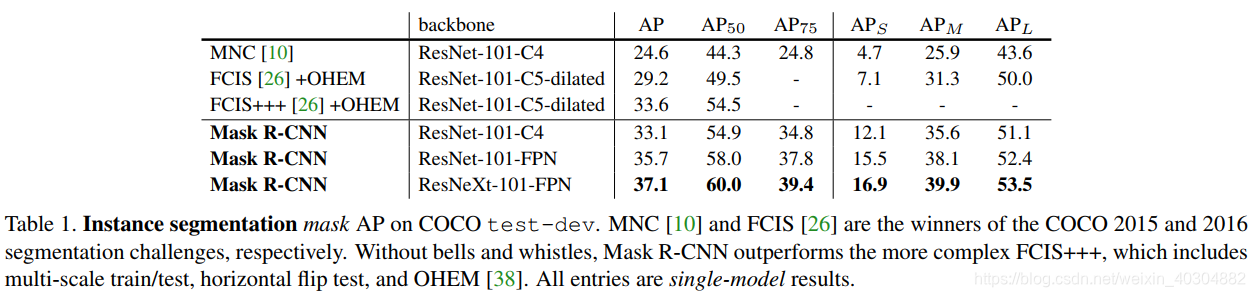

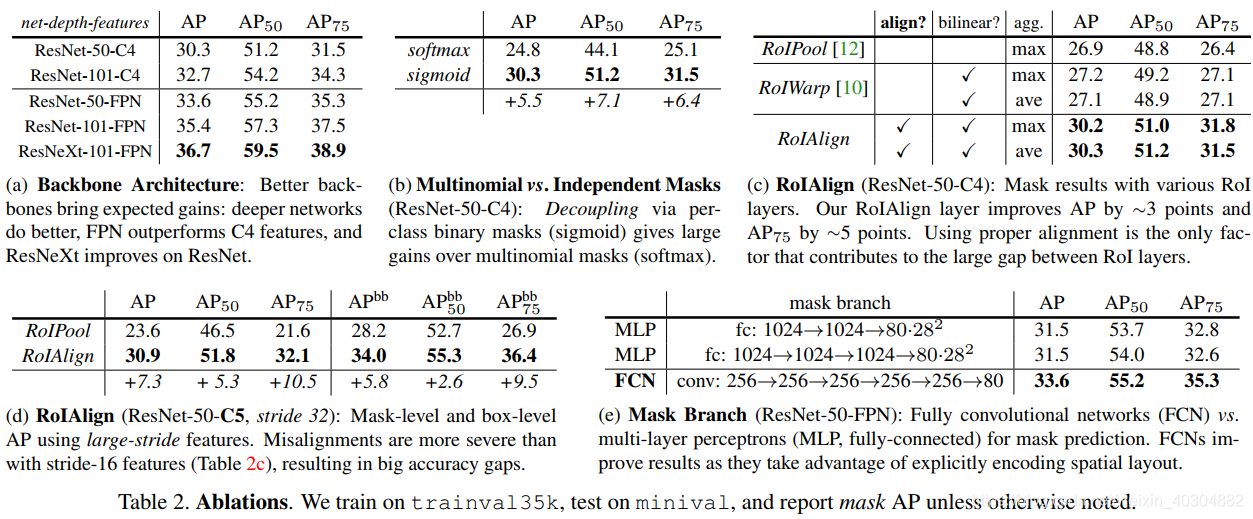
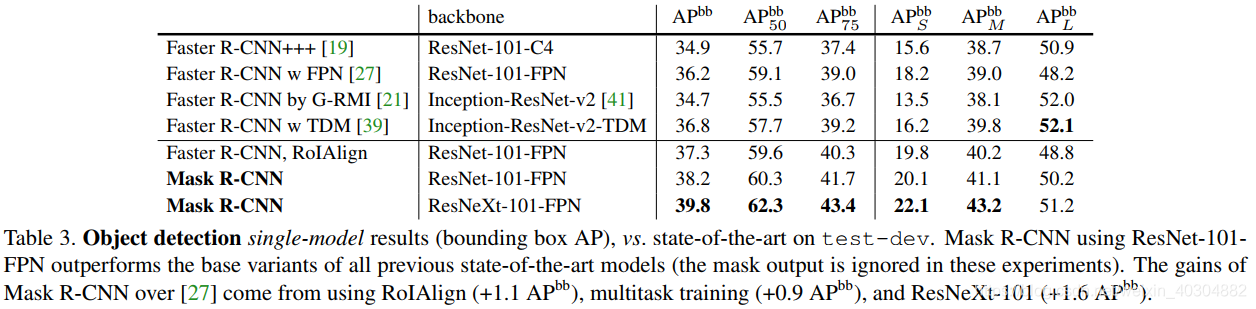

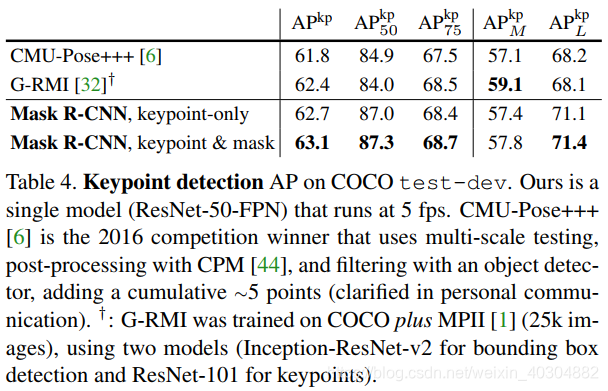
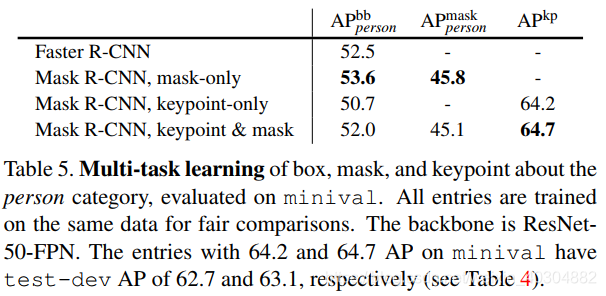
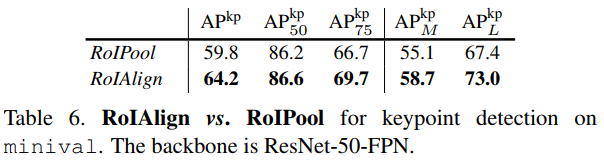
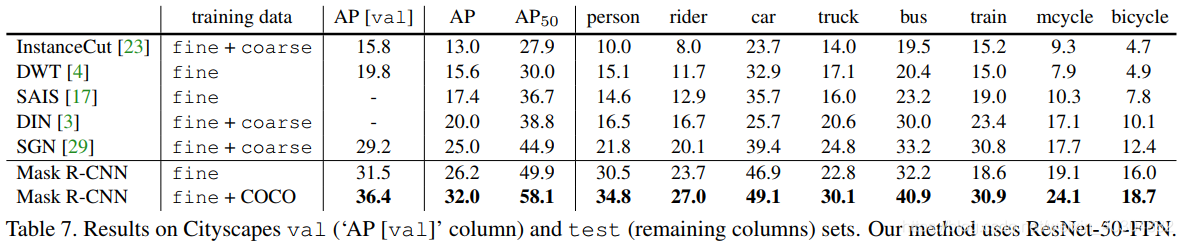
第三阶段(四到五个小时)
第三阶段的关键是尝试虚拟地重新实现论文:也就是说,做出与作者相同的假设,重新创建工作。通过与实际的论文进行比较,你可以很容易地识别出一篇论文的创新点,以及它隐藏的缺点和假设。
2. 相关工作
- 全卷积实例分割FCIS (fully convolutional instance segmentation)同时处理物体的类别,边界框和分割mask,系统速度很快,但是对于重叠的物体分割效果不好,会产生虚假的边缘(如图六所示)
3. Mask R-CNN
基本流程:与Faster R-CNN相同,采用两步骤程序。
第一步使用RPN(Region Proposal Network)产生候选物体边界框。
第二步使用RoIPool从每个候选框中提取特征,执行分类和边界框回归,并为每个RoI输出一个二进制mask。
损失函数:将每个采样RoI上的多任务损失定义为
L
=
L
c
l
s
+
L
b
o
x
+
L
m
a
s
k
L = L_{cls} + L_{box} + L_{mask}
L=Lcls+Lbox+Lmask
mask分支为每个RoI提供一个
K
m
2
Km^2
Km2维的输出,它编码K个分辨率为m×m的二进制mask,K类中的每一个类对应一个m×m的二进制mask。
L
m
a
s
k
L_{mask}
Lmask被定义为平均二进制交叉熵损失,且只与真实类别k有关。
Mask的表现形式:mask是对输入图像的空间轮廓的一个编码,所以很自然地通过卷积提供的像素一一对应来实现。
RoIAlign:RoIPool是从每个RoI中提取小特征图(如7×7)的标准操作。RoIPool首先将一个浮点数RoI量化为特征图的离散粒度,然后将这个量化的RoI细分为空间bin,空间bin本身也进行了量化,最后对每个bin所覆盖的特征值进行汇总(通常通过max pooling)。通过计算[x/16]对连续坐标x进行量化,其中16为feature map stride,[·]为舍入;同样,量子化是在分成bins时进行的(例如,7×7)。这些量化在RoI和提取的特征之间引入了不一致。虽然这可能不会影响分类,但它对预测像素精确的mask有很大的负面影响。
为了解决这个问题,我们提出了一个RoIAlign层,它消除了RoIPool的严格量化,将提取的特征与输入适当地对齐。
我们避免任何量化的RoI边界或bins(即,我们用x/16来代替[x/16])。我们使用双线性插值[22]来计算每个RoI bin中四个定期采样点的输入特征的精确值,并将结果聚合(使用max或average),详情请参见图3。我们注意到,只要不进行量化,结果对精确的采样位置或采样的点数并不敏感。
RPN网络会提出若干RoI的坐标以[x,y,w,h]表示,然后输入RoI Pooling,输出7x7大小的特征图供分类和定位使用。问题就出在RoI Pooling的输出大小是7x7上,如果RON网络输出的RoI大小是8*8的,那么无法保证输入像素和输出像素是一一对应,首先他们包含的信息量不同(有的是1对1,有的是1对2),其次他们的坐标无法和输入对应起来(1对2的那个RoI输出像素该对应哪个输入像素的坐标?)。这对分类没什么影响,但是对分割却影响很大。RoIAlign的输出坐标使用插值算法得到,不再量化;每个grid中的值也不再使用max,同样使用差值算法。
网络体系结构:
为了演示我们的方法的通用性,我们用多个架构实例化了Mask R-CNN。为了清晰起见,我们将其区分为:(i)用于整个图像特征提取的卷积主干架构,以及(ii)分别应用于每个RoI的 用于边界框识别(分类和回归)和mask预测的网络头
- 最初使用ResNets[19]实现的Faster R-CNN从第4阶段的最后一层卷积层(我们称之为C4)中提取特征。例如,这种带有ResNet-50的主干用ResNet-50- c4表示。
- 我们还探索了另一种更有效的主干,称为特征金字塔网络(FPN)。FPN使用具有横向连接的自顶向下架构,从单尺度输入构建网络内特征金字塔。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









