









0、前言
真实面试题:
- 使用了reduceByKey()和groupByKey()等xxxByKey()算子一定会产生shuffle吗?
- Spark 如何优化或者减少shuffle?
1、map
1.1、官方的解释
- 输入函数针对源RDD所有元素进行操作,并且返回一个新的RDD

1.2、代码示例
val dataKv: RDD[String] = sc.parallelize(List(
"hello world",
"hello spark",
"hello world",
"hello hadoop",
"hello world",
"hello world"
))
val words: RDD[String] = dataKv.flatMap(_.split(" "))
val kv: RDD[(String, Int)] = words.map((_, 1))
val res: RDD[(String, Int)] = kv.reduceByKey(_ + _)
/**
* 关注这一步
*/
val res1: RDD[(String, Int)] = res.map(x => (x._1, x._2 * 10))
val result: RDD[(String, Iterable[Int])] = res1.groupByKey()
result.foreach(println)
while (true) {
}
1.3、job运行截图
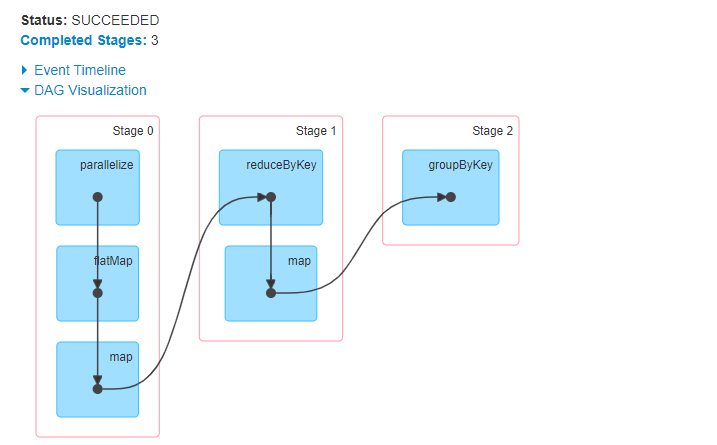
1.4、小结
从上面截图可知,这里产生了两次shuffle,分别是因为使用了reduceByKey()和groupByKey()方法产生的
2、mapValue
2.1、官方的解释
- 输入函数针对源RDD中的Value操作,不改变键值
- 返回原RDD,保留原分区不变

2.2、代码示例
val dataKv: RDD[String] = sc.parallelize(List(
"hello world",
"hello spark",
"hello world",
"hello hadoop",
"hello world",
"hello world"
))
val words: RDD[String] = dataKv.flatMap(_.split(" "))
val kv: RDD[(String, Int)] = words.map((_, 1))
val res: RDD[(String, Int)] = kv.reduceByKey(_ + _)
/**
* 关注这一步:上文使用的是 map(x => (x._1, x._2 * 10))
*/
val res1: RDD[(String, Int)] = res.mapValues(x => x * 10)
val result: RDD[(String, Iterable[Int])] = res1.groupByKey()
result.foreach(println)
while (true) {
}
2.3、job运行截图
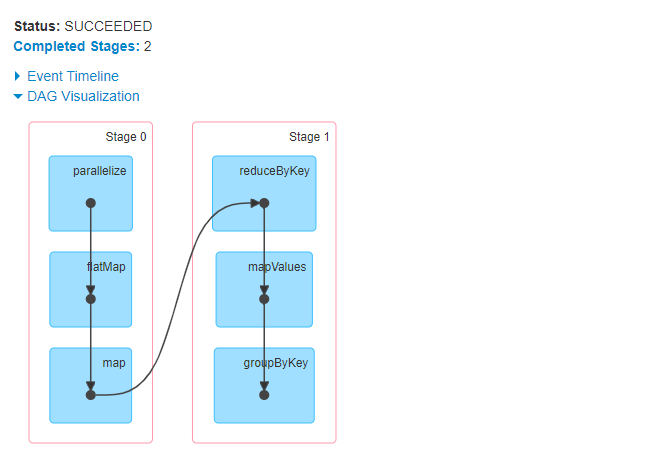
2.4、小结
- 从上面截图可知,这里产生了一次shuffle,此处代码与上文不同的是使用了mapValue,而不是map
- 代码块中使用了reduceByKey()和groupByKey(),却只产生一次shuffle,这里先给出结论使用reduceByKey()等xxxByKey()算子不一定会产生shuffle
- 产生一次shuffle的原因:
- 第一次使用reduceByKey(),已经将RDD按照Key相应关系进行排列
- mapValue不会修改RDD中的Key的对应关系
3、对比
我们回到上文两个算子的官方解释寻找不同点:
- map会改变源RDD,且将函数作用于Key和Value,并返回一个新的RDD
- mapValue则是将函数作用于源RDD的Value且不产生新的RDD,既:源RDD的分区不受到影响
下面我们用一张不是很正确的图来解释下,我们可以看到,map会将源RDD的分区关系进行打散,因为涉及到修改Key操作,且返回了新的RDD,而mapValue则不会影响到分区依赖关系,因为不涉及修改Key
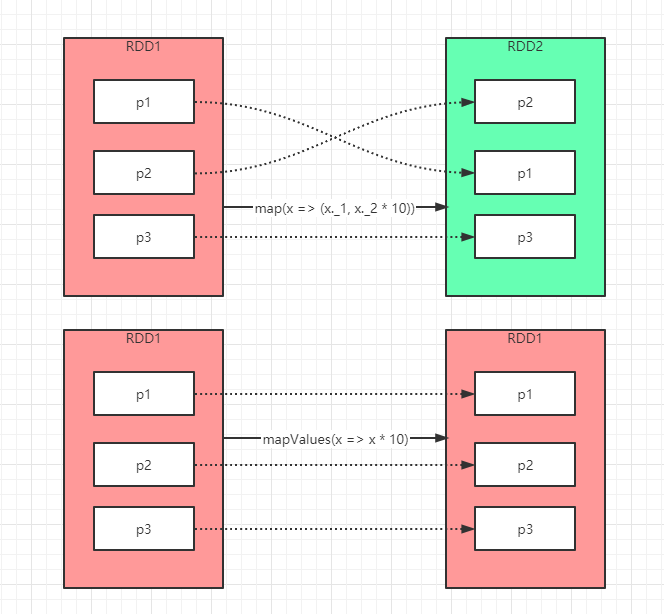
- 由前面文章(Spark基础02-RDD数据集操作)提到的Spark的人性化优化,spark在针对我们代码算子的使用情况,进一步优化我们的程序,减少了shuffle次数,进一步减少stage数量
4、总结
- 使用了reduceByKey等shuffle算子不一定会产生shuffle,因为Spark会根据算子特定优化,在特定场景不会产生shuffle
- 善用mapValue和flatMapValue等算子减少对Key操作,可以有效的减少shuffle,如上演示的案例

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









