







 本文介绍MapReduce Shell的应用,包括查看与管理Job任务的方法,以及MapReduce的技术特征,如横向扩展、错误恢复机制、数据本地性、顺序数据处理、推测执行、可扩展性和抽象机制。
本文介绍MapReduce Shell的应用,包括查看与管理Job任务的方法,以及MapReduce的技术特征,如横向扩展、错误恢复机制、数据本地性、顺序数据处理、推测执行、可扩展性和抽象机制。
四、 MapReduce Shell 应用
1、MapReduce 的二级命令
mapred 称为一级命令,直接输入 mapred 回车,即可查看二级命令:
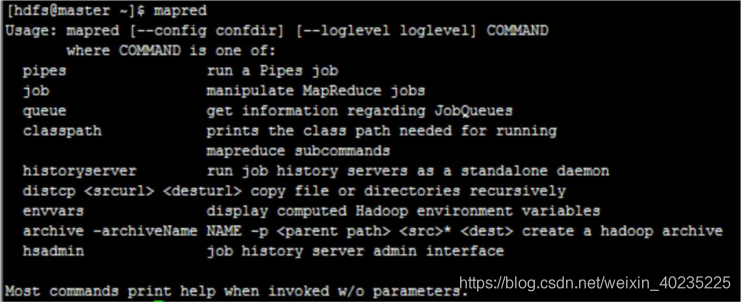
2、MapReduce 的三级命令
输入一级命令 mapred 后,再任意输入一个二级命令,即可查看三级命令:
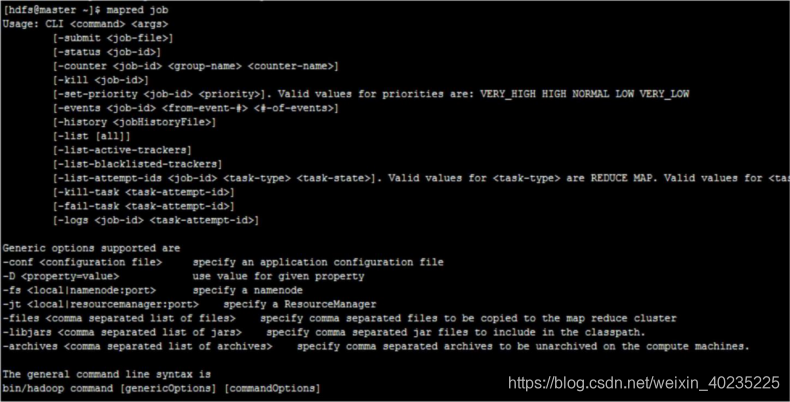
3、MapReduce shell 应用
查看当前正在执行的 job 任务
先提交一个 WordCount 任务,然后使用 mapred job -list 查看任务列表
终止(kill)一个任务的执行
构造场景:先提交一个 WordCount job,然后通过 kill job-id 来终止任务
查看一个 job 的日志
命令格式为:mapred job -logs job-id
五、 MapReduce 技术特征
1、向“外”横向扩展,而非向“上”纵向扩展
- 集群的构建完全选用价格便宜、易于扩展的低端商用服务器,而非价格昂贵不易扩展的商用服务
- 大规模数据处理和大规模数据存储的需要,讲求集群综合能力,而非单台机器处理能力,横向增加机器节点数据量
2、失效被认为是常态
- 使用大量普通服务器,节点硬件和软件出错是常态
- 具备多种有效的错误检测和恢复机制,在某个计算节点失效后会自动转移到别的计算节点。某个任务节点失败后其他节点能够无缝接管失效节点的计算任务
- 当失效节点恢复后自动无缝加入集群,不需要管理员人工进行系统配置
3、移动计算,把处理向数据迁移(数据本地性)
- 采用代码/数据互定位的功能,计算和数据在同一个机器节点或者是同一个机架中,发挥数据本地化特点
- 可避免跨机器节点或是机架传输数据,提高运行效率
4、顺序处理数据、避免随机访问数据
- 磁盘的顺序访问远比随机访问快得多,因此 MapReduce 设计为面向顺序式大规模数据的磁盘访问处理
- 利用集群中的大量数据存储节点同时访问数据,实现面向大数据集批处理的高吞吐量的并行处理
5、推测执行
- 一个作业由若干个 Map 任务和 Reduce 任务构成,整个作业完成的时间取决于最慢的任务的完成时间。由于节点硬件、软件问题,某些任务可能运行很慢
- 采用推测执行机制,发现某个任务的运行速度远低于任务平均速度,会为慢的任务启动一个备份任务,同时运行。哪个先运行完,采用哪个结果。
6、平滑无缝的可扩展性
- 可弹性的增加或减少集群计算节点来调节计算能力
- 计算的性能随着节点数的增加保持接近线性程度的增长
7、为应用开发这隐藏系统底层细节
- 并行编程有很多困难,需要考虑多线程中复杂繁琐的细节,诸如分布式存储管理、数据分发、数据通信和同步、计算结果收集等细节问题。
- MapReduce 提供了一种抽象机制将程序员与系统层细节隔离开,程序员只需关注业务,其他具体执行交由框架处理即可。

















 266
266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









