



 本文总结了查询Count(*)的两种情况。一是针对单表数据的查询,通过where条件筛选,将is_anchor=1的数据在页面展示。在controller中将字段值放入map,mapper文件中的SQL对应处理。二是查询多张表数据,关键在于where后的条件设置,通过重新编写count(*)实现。在dao层提供了相应的代码实现。
本文总结了查询Count(*)的两种情况。一是针对单表数据的查询,通过where条件筛选,将is_anchor=1的数据在页面展示。在controller中将字段值放入map,mapper文件中的SQL对应处理。二是查询多张表数据,关键在于where后的条件设置,通过重新编写count(*)实现。在dao层提供了相应的代码实现。
1、第一种情况是条件只需要查询一张表中的数据,
主要的SQL语句:
<!-- 分页查询主播列表-->
<select id="findAnchor" resultMap="AppUserResultMap">
SELECT
ta.id,
ta.nickname,
tl.title,
tlv.type as anchorType,
tlv.cash_deposit as cashDeposit,
ta.phone
FROM
t_app_user ta
LEFT JOIN t_liveroom tl ON ta.id = tl.anchor_id
LEFT JOIN t_liveinfo tlv ON ta.id = tlv.user_id and tlv.status=1
WHERE
ta.is_anchor = 1
<if test="id != null and id != '' ">
AND ta.id = #{id,jdbcType=BIGINT}
</if>
<if test="phone != null and phone != ''">
AND ta.phone = #{phone,jdbcType=VARCHAR}
</if>
<if test="nickname != null and status != '' ">
AND ta.nickname = #{nickname,jdbcType=VARCHAR}
</if>
<if test="order != null and order != ''">
order by ${order}
</if>
<if test="pageNumber != null and pageSize !=null ">
limit #{pageNumber,jdbcType=INTEGER},#{pageSize,jdbcType=INTEGER}
</if>
</select>
这个查询主要是查询一张表中的数据,看where 的条件就能看出来。
需要在页面中显示这张表中的数据,只需要把is_anchor=1这个字段值存储到pageable中即可,那就只需要在controller中把
字段的值存在map中即可,但是需要注意的是key值对应的是mapper文件中的映射值。
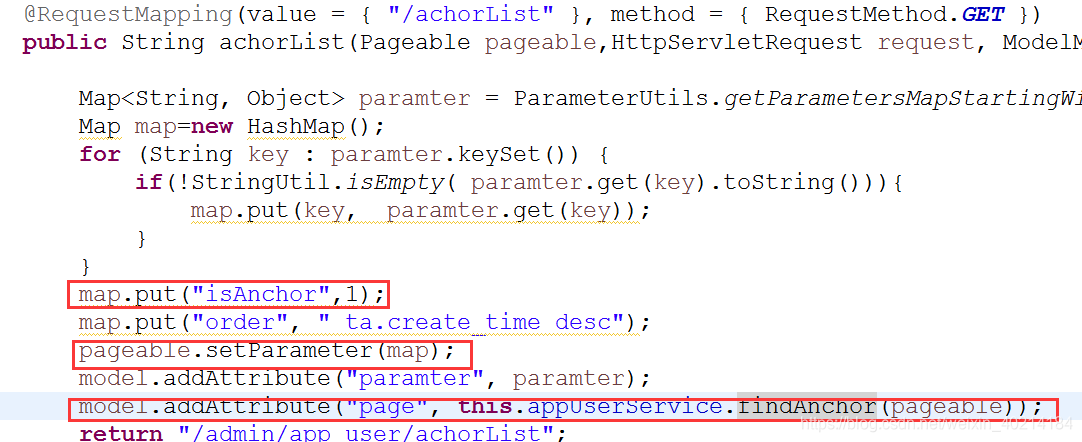
key是与mapper文件中字段映射的
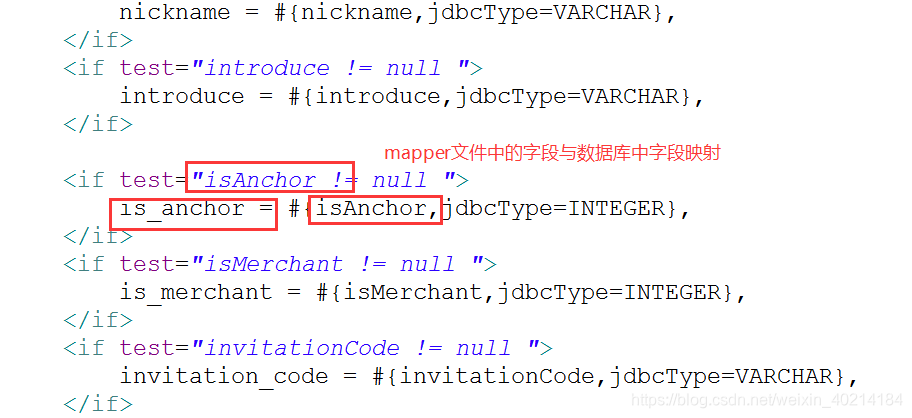
mapper文件中的查询总条数的SQL语句:
<!-- 统计记录数 -->
<select id="count" resultType="long">
SELECT COUNT(id) FROM T_APP_USER a
<where>
<include refid="where_column" />
</where>
</select>
2、页面查询出多张表中的数据
主要思路是重新书写一个count(*),重点是where后的条件。
<!-- 统计记录数 -->
<select id="countLiveinfo" resultType="long">
SELECT
count(*)
FROM
t_liveinfo tl
LEFT JOIN t_app_user ta ON tl.user_id = ta.id
<where> 1=1
<if test="id != null ">
AND tl.user_id = #{id,jdbcType=VARCHAR}
</if>
<if test="phone != null ">
AND ta.phone = #{phone,jdbcType=VARCHAR}
</if>
<if test="nickname != null ">
AND ta.nickName = #{nickname,jdbcType=VARCHAR}
</if>
<if test="type != null ">
AND tl.type = #{type,jdbcType=VARCHAR}
</if>
<if test="statuss != null ">
AND (tl.status = #{statuss,jdbcType=INTEGER} or tl.status = 2)
</if>
</where>
</select>
接下来就是实现层的实现:
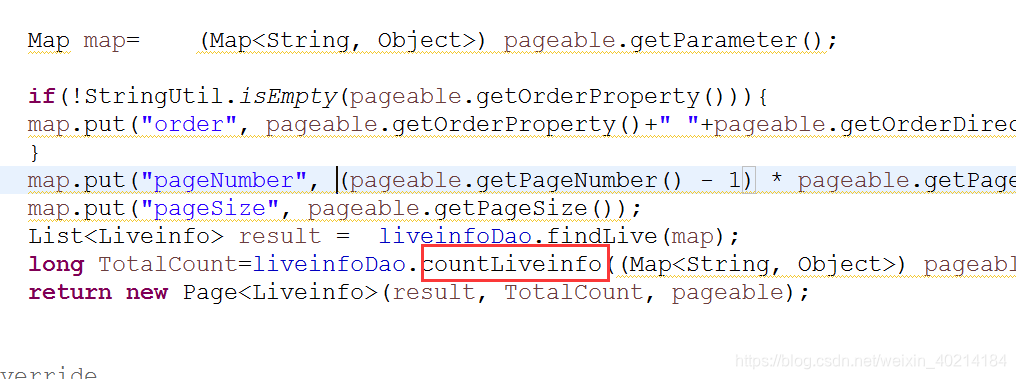
dao层的代码:

这样查询页面中多张表的数据就实现了。

















 963
963

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









