




 Java注解是一种元数据机制,用于提供关于程序但不参与程序运行的数据。元注解如@Retention和@Target用于定义注解的行为和使用范围。@Retention指定了注解的存储方式,如SOURCE、CLASS和RUNTIME,影响注解在源码、编译时或运行时的可见性。@Target则限制注解可以应用的Java元素类型。注解的应用场景包括IDE语法检查、APT注解处理器和运行时反射。
Java注解是一种元数据机制,用于提供关于程序但不参与程序运行的数据。元注解如@Retention和@Target用于定义注解的行为和使用范围。@Retention指定了注解的存储方式,如SOURCE、CLASS和RUNTIME,影响注解在源码、编译时或运行时的可见性。@Target则限制注解可以应用的Java元素类型。注解的应用场景包括IDE语法检查、APT注解处理器和运行时反射。
注解
Java 注解(Annotation)又称 Java 标注,是 JDK5.0 引入的一种注释机制。 注解是元数据的一种形式,提供有关
于程序但不属于程序本身的数据。注解对它们注解的代码的操作没有直接影响。
注解声明
声明一个注解类型
Java中所有的注解,默认实现Annotation 接口:
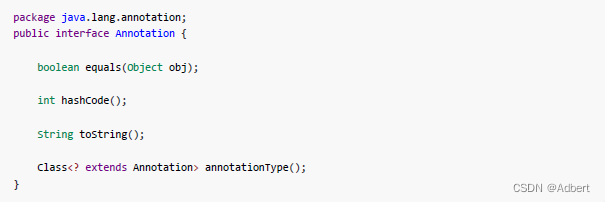
与声明一个"Class"不同的是,注解的声明使用@interface 关键字。一个注解的声明如下:

元注解
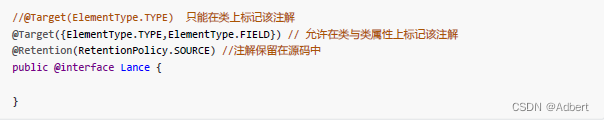
在定义注解时,注解类也能够使用其他的注解声明。对注解类型进行注解的注解类,我们称之为 metaannotation(元注解)。一般的,我们在定义自定义注解时,需要指定的元注解有两个 :
另外还有@Documented 与 @Inherited 元注解,前者用于被javadoc工具提取成文档,后者表示允许子类继承父类中定义的注解。
@Target
注解标记另一个注解,以限制可以应用注解的 Java 元素类型。目标注解指定以下元素类型之一作为其值:
ElementType.ANNOTATION_TYPE 可以应用于注解类型。
ElementType.CONSTRUCTOR 可以应用于构造函数。
ElementType.FIELD 可以应用于字段或属性。
ElementType.LOCAL_VARIABLE 可以应用于局部变量。
ElementType.METHOD 可以应用于方法级注解。
ElementType.PACKAGE 可以应用于包声明。
ElementType.PARAMETER 可以应用于方法的参数。
ElementType.TYPE 可以应用于类的任何元素。
@Retention
注解指定标记注解的存储方式:
RetentionPolicy.SOURCE - 标记的注解仅保留在源级别中,并被编译器忽略。
RetentionPolicy.CLASS - 标记的注解在编译时由编译器保留,但 Java 虚拟机(JVM)会忽略。
RetentionPolicy.RUNTIME - 标记的注解由 JVM 保留,因此运行时环境可以使用它。
@Retention 三个值中 SOURCE < CLASS < RUNTIME,即CLASS包含了SOURCE,RUNTIME包含SOURCE、CLASS。下文会介绍他们不同的应用场景。
例子:
注解类型元素
在上文元注解中,允许在使用注解时传递参数。我们也能让自定义注解的主体包含 annotation type element (注解类型元素) 声明,它们看起来很像方法,可以定义可选的默认值。
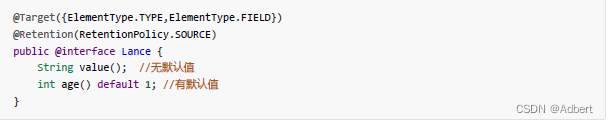
注意:在使用注解时,如果定义的注解中的类型元素无默认值,则必须进行传值。

注解应用场景
按照@Retention 元注解定义的注解存储方式,注解可以被在三种场景下使用:
SOURCE
RetentionPolicy.SOURCE ,作用于源码级别的注解,可提供给IDE语法检查、APT等场景使用。
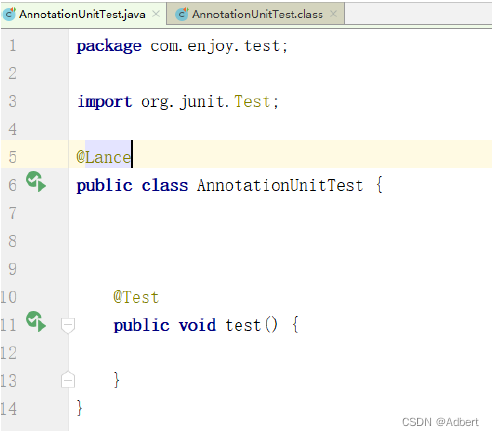
在类中使用SOURCE 级别的注解,其编译之后的class中会被丢弃。
IDE语法检查
在Android开发中, support-annotations 与androidx.annotation) 中均有提供@IntDef 注解,此注解的定义如下:

Java中Enum(枚举)的实质是特殊单例的静态成员变量,在运行期所有枚举类作为单例,全部加载到内存中。比常量多5到10倍的内存占用。
此注解的意义在于能够取代枚举,实现如方法入参限制。
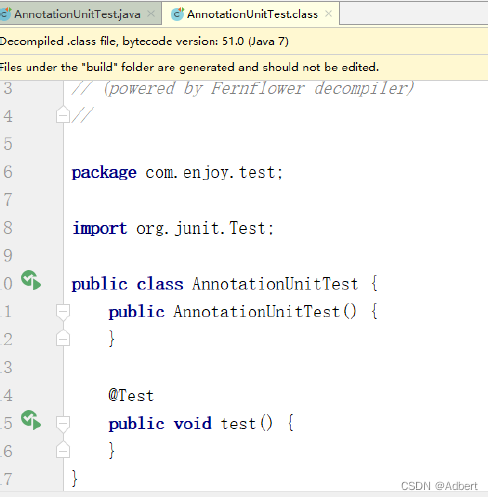
如:我们定义方法test ,此方法接收参数teacher 需要在:Lance、Alvin中选择一个。如果使用枚举能够实现为:

而现在为了进行内存优化,我们现在不再使用枚举,则方法定义为:

然而此时,调用test 方法由于采用基本数据类型int,将无法进行类型限定。此时使用@IntDef增加自定义注解:

此时,我们再去调用test 方法,如果传递的参数不是LANCE 或者ALVIN 则会显示 Inspection 警告(编译不会报错)。
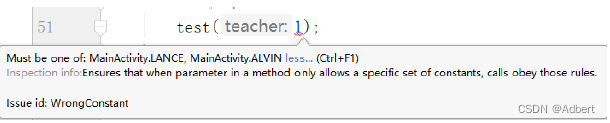
可以修改此类语法检查级别:
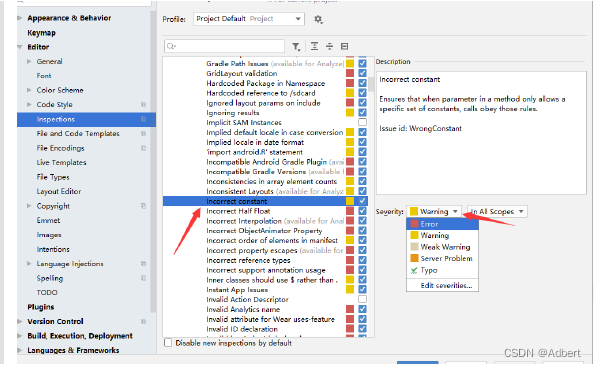
以上注解均为SOURCE 级别,本身IDEA/AS 就是由Java开发的,工具实现了对Java语法的检查,借助注解能对被注解的特定语法进行额外检查。
APT注解处理器
APT全称为:"Anotation Processor Tools",意为注解处理器。顾名思义,其用于处理注解。编写好的Java源文件,需要经过javac 的编译,翻译为虚拟机能够加载解析的字节码Class文件。注解处理器是 javac 自带的一个工具,用来在编译时期扫描处理注解信息。你可以为某些注解注册自己的注解处理器。 注册的注解处理器由javac调起,并将注解信息传递给注解处理器进行处理。

CLASS
定义为CLASS 的注解,会保留在class文件中,但是会被虚拟机忽略(即无法在运行期反射获取注解)。此时完全符合此种注解的应用场景为字节码操作。如:AspectJ、热修复Roubust中应用此场景。
所谓字节码操作即为,直接修改字节码Class文件以达到修改代码执行逻辑的目的。在程序中有多处需要进行是否登录的判断。
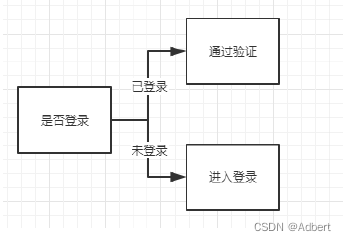
如果我们使用普通的编程方式,需要在代码中进行if-else 的判断,也许存在十个判断点,则需要在每个判断点加入此项判断。此时,我们可以借助AOP(面向切面)编程思想,将程序中所有功能点划分为: 需要登录与无需登录两种类型,即两个切面。对于切面的区分即可采用注解。
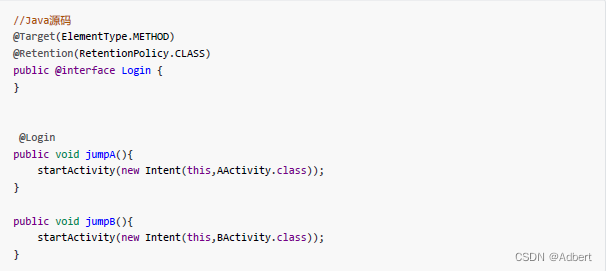
在上诉代码中, jumpA 方法需要具备登录身份。而Login 注解的定义被设置为CLASS 。因此我们能够在该类所编译的字节码中获得到方法注解Login 。在操作字节码时,就能够根据方法是否具备该注解来修改class中该方法的内容加入if-else 的代码段:


注解能够设置类型元素(参数),结合参数能实现更为丰富的场景,如:运行期权限判定等。
RUNTIME
注解保留至运行期,意味着我们能够在运行期间结合反射技术获取注解中的所有信息。
反射
一般情况下,我们使用某个类时必定知道它是什么类,是用来做什么的,并且能够获得此类的引用。于是我们直接对这个类进行实例化,之后使用这个类对象进行操作。
反射则是一开始并不知道我要初始化的类对象是什么,自然也无法使用 new 关键字来创建对象了。这时候,我们使用 JDK 提供的反射 API 进行反射调用。反射就是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意方法和属性;并且能改变它的属性。是Java被视为动态语言的关键。
Java反射机制主要提供了以下功能:
1、在运行时构造任意一个类的对象
2、在运行时获取或者修改任意一个类所具有的成员变量和方法
3、在运行时调用任意一个对象的方法(属性)
Class
反射始于Class,Class是一个类,封装了当前对象所对应的类的信息。一个类中有属性,方法,构造器等,比如说有一个Person类,一个Order类,一个Book类,这些都是不同的类,现在需要一个类,用来描述类,这就是Class,它应该有类名,属性,方法,构造器等。Class是用来描述类的类。
Class类是一个对象照镜子的结果,对象可以看到自己有哪些属性,方法,构造器,实现了哪些接口等等。对于每个类而言,JRE 都为其保留一个不变的 Class 类型的对象。一个 Class 对象包含了特定某个类的有关信息。 对象只能由系统建立对象,一个类(而不是一个对象)在 JVM 中只会有一个Class实例。
获得 Class 对象
获取Class对象的三种方式
1. 通过类名获取 类名.class
2. 通过对象获取 对象名.getClass()
3. 通过全类名获取 Class.forName(全类名) classLoader.loadClass(全类名)
使用 Class 类的 forName 静态方法
![]()
直接获取某一个对象的 class

调用某个对象的 getClass() 方法

判断是否为某个类的实例
一般地,我们用 instanceof 关键字来判断是否为某个类的实例。同时我们也可以借助反射中 Class 对象的isInstance() 方法来判断是否为某个类的实例,它是一个 native 方法:
![]()
判断是否为某个类的类型
![]()
创建实例
通过反射来生成对象主要有两种方式。
1、使用Class对象的newInstance()方法来创建Class对象对应类的实例。

2、先通过Class对象获取指定的Constructor对象,再调用Constructor对象的newInstance()方法来创建实例。这种方法可以用指定的构造器构造类的实例。

获取构造器信息
得到构造器的方法

获取类构造器的用法与上述获取方法的用法类似。主要是通过Class类的getConstructor方法得到Constructor类的一个实例,而Constructor类有一个newInstance方法可以创建一个对象实例:
![]()
获取类的成员变量(字段)信息
获得字段信息的方法

调用方法
获得方法信息的方法

当我们从类中获取了一个方法后,我们就可以用 invoke() 方法来调用这个方法。invoke 方法的原型为:
![]()
利用反射创建数组
数组在Java里是比较特殊的一种类型,它可以赋值给一个Object Reference 其中的Array类为
java.lang.reflect.Array类。我们通过Array.newInstance()创建数组对象,它的原型是:
![]()
反射获取泛型真实类型
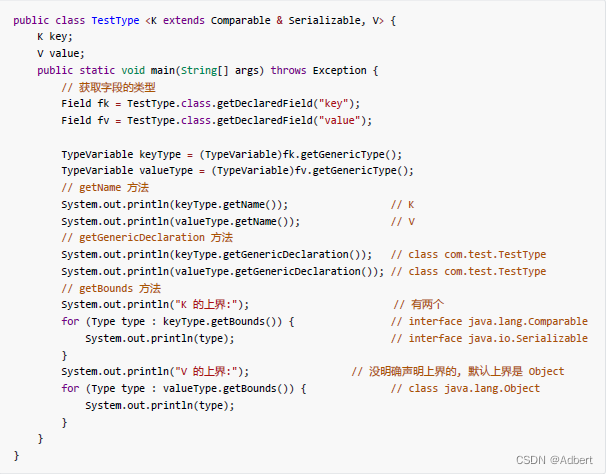
当我们对一个泛型类进行反射时,需要的到泛型中的真实数据类型,来完成如json反序列化的操作。此时需要通过Type 体系来完成。Type 接口包含了一个实现类(Class)和四个实现接口,他们分别是:
TypeVariable
泛型类型变量。可以泛型上下限等信息;
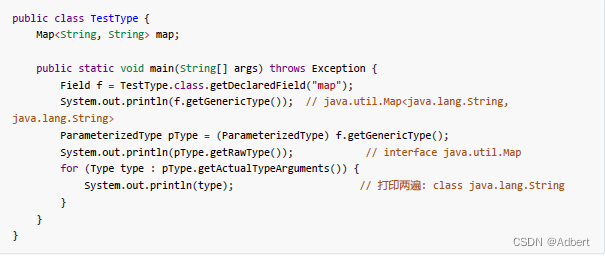
ParameterizedType
具体的泛型类型,可以获得元数据中泛型签名类型(泛型真实类型)
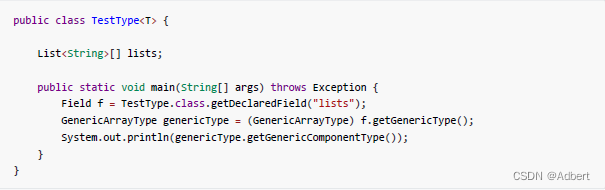
GenericArrayType
当需要描述的类型是泛型类的数组时,比如List[],Map[],此接口会作为Type的实现。
WildcardType
通配符泛型,获得上下限信息;
TypeVariable
ParameterizedType
GenericArrayType
WildcardType

Gson反序列化

为什么TypeToken要定义为抽象类?
Response<Data> resp = gson.fromJson(json, new TypeToken<Response<Data>>() {
}.getType());
在进行GSON反序列化时,存在泛型时,可以借助TypeToken 获取Type以完成泛型的反序列化。但是为什么TypeToken 要被定义为抽象类呢?
因为只有定义为抽象类或者接口,这样在使用时,需要创建对应的实现类,此时确定泛型类型,编译才能够将泛型signature信息记录到Class元数据中。

















 1459
1459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









