







 本文详细介绍了MySQL中的EXPLAIN分析SQL语句,解释了如何有效使用索引。通过实例展示了索引的基本操作,包括最左前缀法则、范围查询、索引失效的情况,如列运算、字符串不加引号、OR条件、模糊查询等。同时,讨论了NULL值、IN操作符对索引的影响,强调了复合索引的优势。
本文详细介绍了MySQL中的EXPLAIN分析SQL语句,解释了如何有效使用索引。通过实例展示了索引的基本操作,包括最左前缀法则、范围查询、索引失效的情况,如列运算、字符串不加引号、OR条件、模糊查询等。同时,讨论了NULL值、IN操作符对索引的影响,强调了复合索引的优势。
在说索引之前,先要说一个东西:explain-分析执行计划
explain
查询出数据库表

使用explain进行sql查询

分析参数含义:
id:相同,顺序执行;不同,大的优先执行。
select_type:simple-简单的select查询;
primary-查询中包含复杂子查询;
subquery-在select或where中包含子查询;
derived-在from列表中包含子查询,把结果放在临时表;
nuion-多个表连接查询使用关键字union。
type:null-不访问任何表、索引,直接返回结果(效率最高);
system-表中只有1条记录;
const-根据主键、索引查询,返回结果只有1条记录;
eq_ref-多表关联查询,返回结果只有1条记录,使用唯一索引查询;
ref-使用非唯一索引进行查询;
range-where之后出现between、in、<、>等操作;
index-只遍历索引树,比all快;
all-遍历全表以找到匹配的行,是遍历数据文件。
执行效率null>system>const>eq_ref>ref>range>index>all
一般至少达到range级别,最好达到ref。
key:possible_keys-显示应用在这张表的索引,1个或多个;
key-实际使用的索引,若为null,表示没有使用索引;
key_len-表示索引使用的字节数,长度越短越好。
rows:扫描行的数量。
Extra:其他额外的执行计划;
using filesort 效率低;
using temporary 效率低;
using index 效率不错。
索引
索引基本操作
1、创建索引
单列索引(name)
create index idx_seller_name on t_user(name);//idx_seller_name为索引名
复合索引(name,status,address)
create index idx_seller_name_sta_addr on t_user(name,status,address);
2、查看索引
show index from t_user;
3、删除索引
drop index idx_seller_name on t_user;
4、查看索引使用情况
当前会话:show status like 'Handler_read%';
全局:show global status like 'Handler_read%';索引的使用
1、遵循最左前缀法则。针对的是复合索引,根据上面创建的复合索引,查询条件必须包含最左列的name索引。
以下查询都使用了索引:
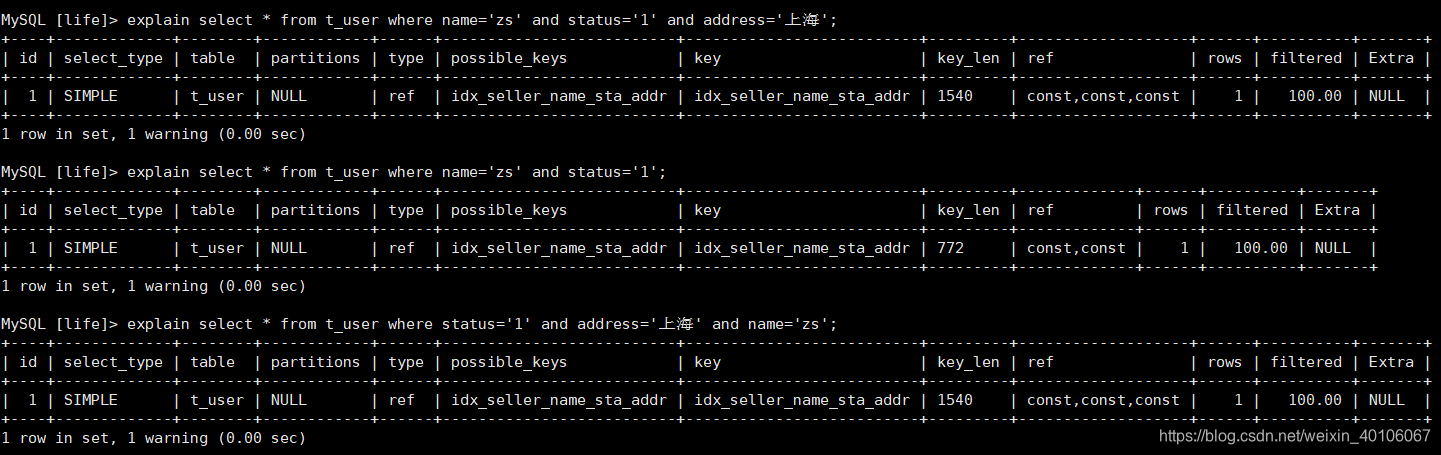
下面情况where字句少了name,导致索引失效:

2、where字句中范围查询条件后面的列不能使用索引

可以看出key_len值变小了,是因为address和name索引失效了。
3、不要在索引列进行运算,会使索引失效

4、字符串不加单引号,会使索引失效
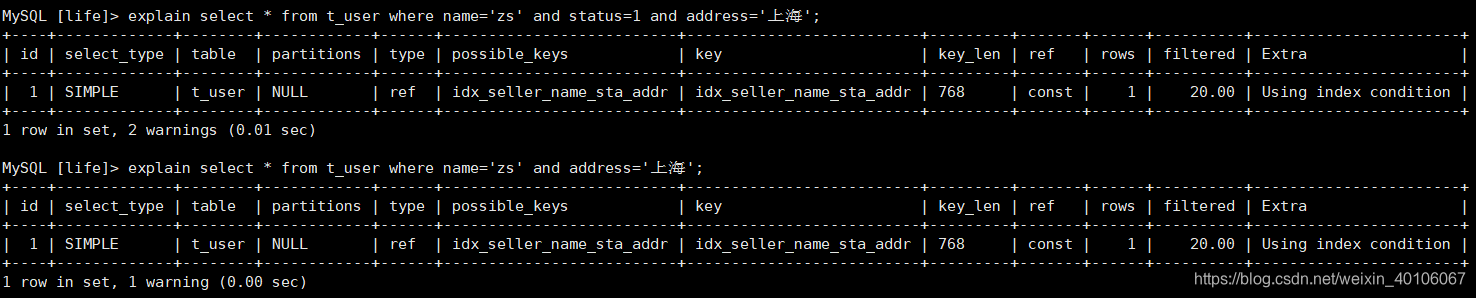
5、尽量使用覆盖索引,避免select *
查询的列必须为索引列

当Extra值为Using index condition时,表示查询会有回表查询操作,效率低;将select * 改成select 索引列之后变成Using index。
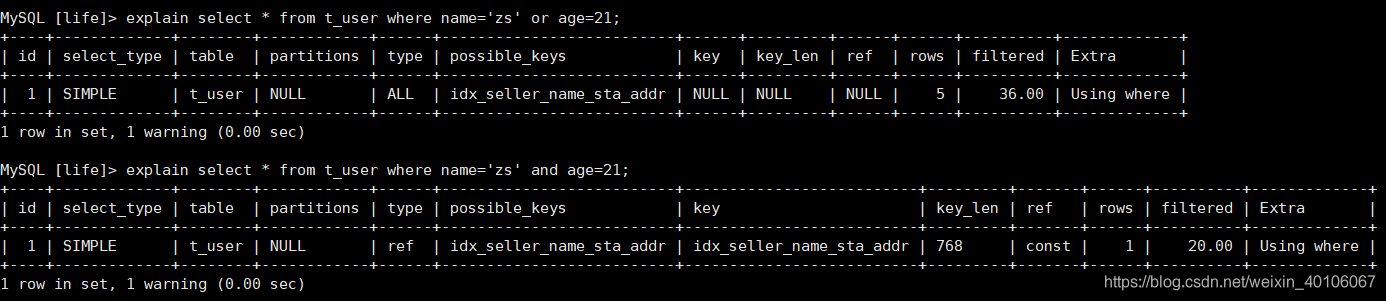
6、用or分割开的条件,若or前的条件中的列有索引,而后面的列中没有索引,则涉及到列的索引都不会被用到。(针对单列索引)
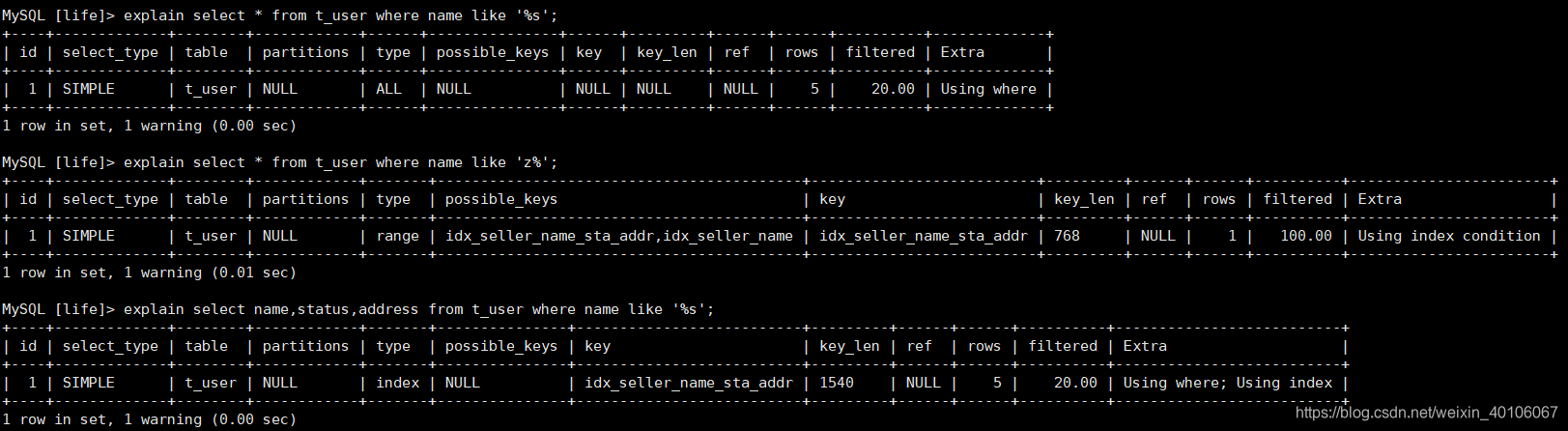
7、模糊查询
若以%开头进行模糊匹配,索引失效;
若只是尾部用%进行模糊匹配,索引不失效。
以%开头进行模糊匹配, 解决办法:使用覆盖索引。
8、若mysql评估使用索引比全表查询更慢,则不使用索引。
9、 is null,is not null走索引有时会失效。
select * from t_user where name is null;
如果t_user表中name字段都不为null,则走索引;
如果t_user表中name字段多数为null,则不走索引;
select * from t_user where name is not null;
如果t_user表中name字段都不为null,则不走索引;
如果t_user表中name字段多数为null,则走索引;10、in走索引,not in索引失效
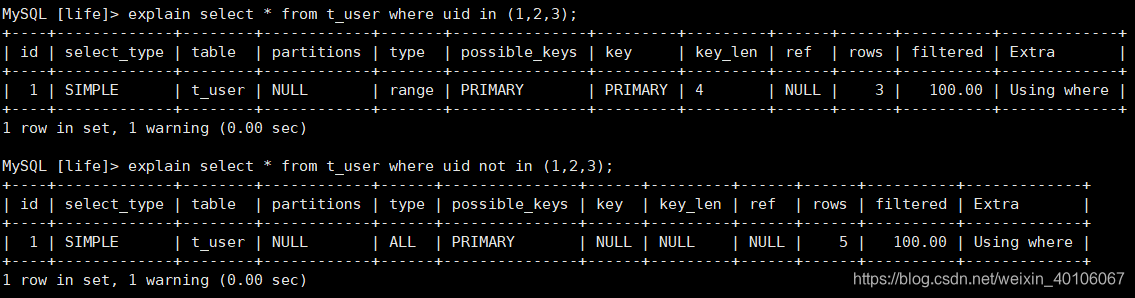
11、尽量使用复合索引,少使用单列索引。
因为复合索引相当于创建了多个索引,而单列索引,数据库会选择一个最优的索引来使用,并不会使用全部索引。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









