






生产者流程
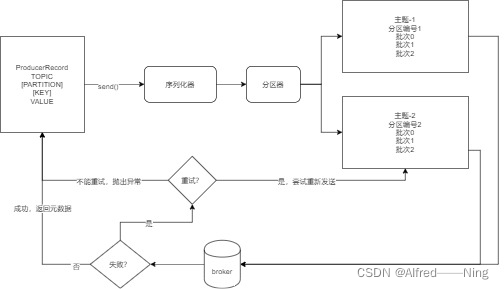
发送流程
- 创建ProducerRecord对象,包含主题和发送内容,可选指定键和分区
- 键值对象序列化成字节数组
- 数据发送给分区器,没有指定分区情况下,根据键选择一个分区
- 分区选择完毕,这条消息添加到一个批次当中,这个批次的所有记录归属于相同主题和分区
- 独立线程将记录批次发送到相应的broker上
- broker返回响应
- 消息写入broker成功,返回RecordMetaData对象,包含主题和分区,以及记录在分区的偏移量
- 消息写入broker失败,返回错误,生产者根据配置进行重试,重试次数达到仍然失败,返回错误信息
发送消息的方式
- 发送忘记:消息发送给服务器,但并不关心它是否正常到达,错误自动重试
- 同步发送:send() 方法发送消息,它会返回一个Future 对象,调用get() 方法进行等待,判断是否发送成功
- 异步发送:send() 方法,并指定一个回调函数,服务器在返回响应时调用该函数
生产者发送消息-Coding
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class MessageProducer {
public static void main(String[] args) {
// 生产者配置
Properties producerConfig = new Properties();
// bootstrap.servers
producerConfig.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka-node01:9092,kafka-node02:9092,kafka-node03:9092,");
// 设置key的序列化器
producerConfig.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 设置value的序列化器
producerConfig.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 创建kafka生产者
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(producerConfig);
String topic = "test-vip";
ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>(topic, "messageKey", "messageValue");
// 同步发送
// try {
// // 如果服务器返回错误,get()抛出异常,发送成功返回RecordMetadata 对象
// producer.send(producerRecord).get();
// } catch (Exception e) {
// e.printStackTrace();
// }
// 异步发送
try {
// 如果服务器返回错误,get()抛出异常,发送成功返回RecordMetadata 对象
producer.send(producerRecord, new ProducerCallBack());
} catch (Exception e) {
e.printStackTrace();
}
}
}
class ProducerCallBack implements Callback {
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
// 如果服务器返回错误,会抛出非空异常
if(e != null){
e.printStackTrace();
}
}
}
生产者配置参数
-
acks: 指定必须要有多少个分区副本收到消息,生产者才会认为消息写入成功
- acks = 0: 生产者在成功写入消息之前不会等待任何来自服务器的响应
- acks = 1: 集群首领节点收到消息,返回相应给生产者确认消息发送成功,否则收到错误响应,生产者重新发送消息
- acks = all: 所有复制节点全部收到消息,集群响应生产者
-
buffer.memory:设置生产者内存缓冲区的大小,生产者用它缓冲要发送到服务器的消息,如果生产者发送消息速度超过发送到服务器的速度,导致生产者空间不足。send() 方法调用要么被阻塞,要么抛出异常取决于max.block.ms:阻塞时长
-
compression.type:默认情况下,消息发送时不会被压缩。该参数可以设置为snappy、gzip 或lz4,它指定了
消息被发送给broker 之前使用哪一种压缩算法进行压缩。可选值:snappy,gazip等 -
retries: 生产者可以重发消息的次数,如果达到这个次数,生产者会放弃重试并返回错误;。默认情况下,生产者会在每次重试之间等待100ms,取决于retry.backoff.ms 参数
-
batch.size: 指定一个批次使用的内存大小 字节数
-
linger.ms: 参数指定了生产者在发送批次之前等待更多消息加入批次的时间
-
client.id: 任意的字符串,服务器会用它来识别消息的来源
-
max.in.flight.requests.per.connection: 指定了生产者在收到服务器响应之前可以发送多少个消息,值越高,内存占据越多设为1 可以保证消息是按照发送的顺序写入服务器的,即使生了重试。
-
timeout.ms: 指定broker 等待同步副本返回消息确认的时间,与asks 的配置相匹配——如果在指定时间内没有收到同步副本的确认,那么broker 就会返回一个错误
-
request.timeout.ms: 生产者在发送数据时等待服务器返回响应的时间
-
metadata.fetch.timeout.ms: 指定了生产者在获取元数据(时等待服务器返回响应的时间。如果等待响应超时,那么生产者要么重试发送数据,要么返回一个错误抛出异常或执行回调
-
max.block.ms: 调用send() 方法或使用partitionsFor() 方法获取元数据时生产者的阻塞时间,超出该时间,生产者抛出异常
-
max.request.size: 控制生产者发送的请求大小。它可以指能发送的单个消息的最大值,也可以指
单个请求里所有消息总的大小 -
message.max.bytes: 该参数由broker设置,与max.request.size要匹配
-
receive.buffer.bytes;send.buffer.bytes:TCP socket 接收和发送数据包的缓冲区大小,设为-1,就使用操作系统的默认值
发送消息的顺序问题
kafka保证单个分区内有序,但如果retries 设为非零整数max.in.flight.requests.per.connection设为比1 大的数,那么就由可能发生顺序相反。保证严格顺序下,可以设置:retries 设为0;max.in.flight.requests.per.connection = 1
序列化器
- Avro序列化(常用)
- json(常用)
- 自定义(不推荐)
分区
默认分区器
- 消息键可以设置为null, 如果使用默认的分区器,记录将随机的发送到主题内各个可用的分区。分区使用**轮询(Round Robin)**算法将消息均衡地分布到各个分区上
- 键不为null,根据散列值将消息映射到特定的分区,同一个键总是被映射到同一个分区
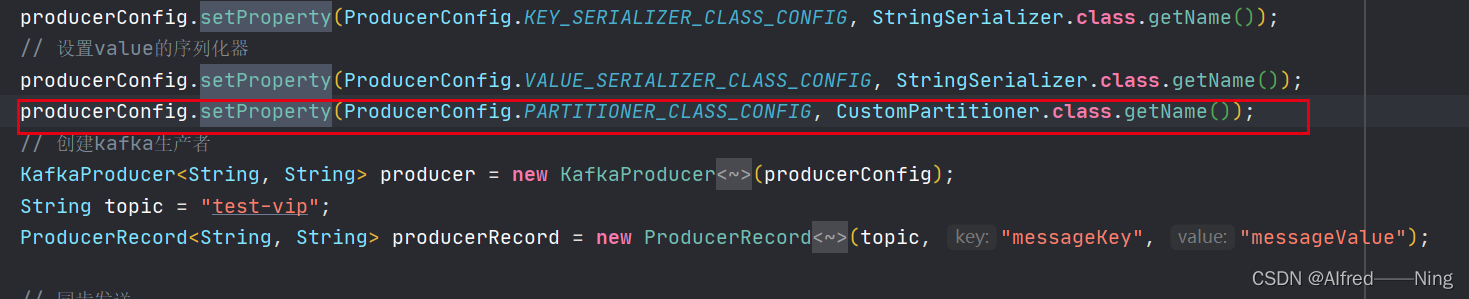
自定义分区器
public class CustomPartitioner implements Partitioner {
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
Integer numPartitions = cluster.partitionCountForTopic(topic);
// 分区逻辑
if ((keyBytes == null) || (!(key instanceof String))){
throw new InvalidRecordException("expect the record has the key");
}
if("svip".equals(key.toString())){
// 返回分区编号
return numPartitions - 1;
}
return (Math.abs(Utils.murmur2(keyBytes) % (numPartitions - 2)));
}
public void close() {
}
public void configure(Map<String, ?> map) {
}
}
配置生产者调用:


















 236
236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











