







前面文章中,我们讲到,希望最终的模型在训练集上有很好的拟合(训练误差小),同时对测试集也要有较好的拟合(泛化误差小)
那么针对模型的拟合,这里引入两个概念:过拟合,欠拟合。
过拟合:是指我们在训练集上的误差较小,但在测试集上的误差较大;
欠拟合:在训练集上的效果就很差。
对于二分类数据,我们可以用下面三个图更直观的理解过拟合与欠拟合:
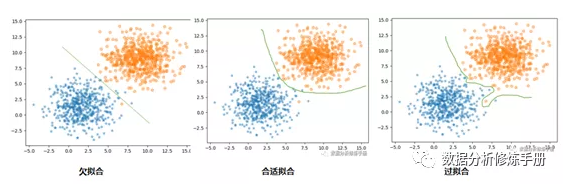
欠拟合
首先来说欠拟合,欠拟合主要是由于学习不足造成的,那么我们可以通过以下方法解决此问题
1、增加特征:增加新的特征,或者衍生特征(对特征进行变换,特征组合)
2、使用较复杂的模型,或者减少正则项
过拟合
其次讨论过拟合,为什么我们的模型会过拟合呢?这里,我总结了一下,将其原因分成两大类:
1、样本问题
样本量太少:
样本量太少可能会使得我们选取的样本不具有代表性,从而将这些样本独有的性质当作一般性质来建模,就会导致模型在测试集上效果很差;
训练集、测试集分布不一致:
对于数据集的划分没有考虑业务场景,有可能造成
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1161
1161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









