






1. 概述
视频/图像质量评价(Video/Image Quality Assessment)是指通过主客观的方式对两幅主体内容相同的图像信息的变化与失真进行感知、衡量与评价。
视频/图像质量评价包括视频/图像的逼真度与可懂度,逼真度是指被评价图像与标准图像的偏离程度,可懂度是指表示图像能向人或计算机提供信息的能力。评价方法分为主观评价方法和客观评价方法两种。主观评分一般是平均主观得分(mean opinion score, MOS)或平均主观得分差(difference mean opinion score, DMOS)来表示。前者是通过对观察者的评分归一化来判断图像质量,后者是通过观察者对无失真图像和有失真图像评价得分差异再归一化来判断图像质量。
客观评价方法是计算机根据算法计算出视频/图像的质量指标。虽然客观评价方法是让计算机尽量从人的主观视角出发来预测特定视频的评分,但不同客观评价指标与主观感受的符合程度差距较大。可以基于预测的准确性、一致性、稳定性、单调性来衡量评价指标本身的好坏。所谓准确性是指主观评价打分和客观评价指标分数的相似性;一致性是指不应仅对某种类型的视频/图像表现良好,而应该对所有类型的视频/图像都可以表现良好;稳定性是指对同一视频/图像每次评价的结果数值应该相同或误差在可接收的范围内;单调性是指评价分数应该如随MOS分的增减呈现相应的单增或单减。衡量客观评价方法的指标是通过客观评价模型输出QR与主观MOS的非线性拟合后变化为MOS_P,准确性体现在MOS与MOS_P的Pearson线性相关系数,一致性体现在MOS_P的离群率,稳定性体现在每次相同输入后输出非线性拟合得到的MOS_P间误差,单调性体现在MOS与MOS_P之间的Spearman阶相关系数。
客观评价方法的应用场景也比较丰富,首先,可以用该评价方法衡量编解码算法以及其软硬件实现的优劣;其次,可以评估视频/图像经过通信传输系统后的损伤来衡量通信传输系统的优劣;再次,可以衡量图像增强、图像重建算法的优劣;最后,评价方法的结果可以反馈给信源端的编码器为下一步的参数设置提供依据,进而有针对性的对编解码损耗、通信传输过程中的损伤进行参数优化与重新配置。
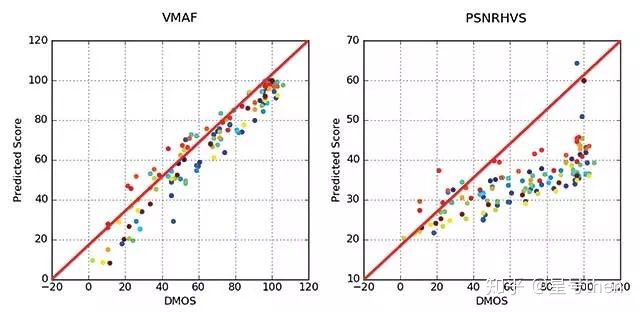
客观评价指标分为三类:基于误差的评价指标、基于感知模型与图像结构信息的评价指标以及基于机器学习的评价指标。基于误差评价指标是将压缩图像和原始图像进行对比,计算两个图像之间的差异(称为噪声或误差),代表指标是均方误差(Mean square error, MSE)、峰值信噪比(Peak signal noise ratio, PSNR)。基于感知模型与图像结构评价指标通过引入人类视觉系统模型(Human Visual System, HVS)将图像质量下降转化为感知结构信息的变化和一些感知现象(亮度、对比度、观看距离)的变化,对人类如何感知这些误差进行数学建模,代表指标是结构相似度(Structure similarity Index, SSIM)、恰可识别阈值(Just Noticeable Difference, JND)。基于机器学习的评价指标一般用来度量长时间视频,从某个可训练的模型开始,将基于误差评价指标或基于感知评价指标结果与主观MOS分数进行比较,并对模型进行微调以使其随时间推移而改善,或是多种评价指标体系的融合,这些多种指标包括度量图像质量的指标和度量时间质量的指标,基于机器学习的评价指标有代表性的指标是视频多评估方法融合(Visual Multimethod Assessment Fusion, VMAF)。
此外,从对参考视频/图像的依赖上,还可以分为全参考方法(Full reference, FR)、半参考/部分参考方法(Reduced reference, RR)和无参考(No reference, NR)方法三类评价方法。全参考方法需要提供一个无失真的原始图像,经过对二者的比对得到一个对失真图像的评价结果,前文所提的MSE、PSNR、SSIM以及视觉信息保真度(Visual information fidelity, VIF)、视觉信噪比(Visual signal to noise ratio, VSPR)、最显著失真(Most apparent distortion, MAD)、图像差异预测(Image difference prediction, IDP)等都是全参考方法。半参考/部分参考方法是指参考的不是原视频/图像,而是从原视频/图像中提取的某些特征或是添加的一些信息,并通过无损伤的辅助信道传至信宿,在对经过有损伤的主信道传输过来的视频/图像进行特征提取,来分析这些特征信息的损耗程度,进而反映视频/图像的质量受损程度。典型的评价方法有:基于特征提取的方法、基于谐波强度的方法以及基于小波域统计模型的方法。无参考方法是完全没有原视频/图像来进行视频/图像质量评价,一般方法是将质量因素分解为某类失真、效应或噪声,然后建立相应的评价模型。由于互联网视频应用的爆发增长以及其参考源难以获取的特性,无参考质量评价方法成为近些年来的研究热点,时域ITU-P.910和空间域ITU-P.910是无参考方法。
2. 客观指标
2.1 均方误差(Mean square error, MSE)
原理与框架:原始参考帧和失真帧直接做差取平方求和,此外一些其他传统评价指标如绝对误差(Mean absolute error, MAE)、根均方误差(Root mean square error, RMSE)、标准偏差(Standard deviation, STD)效果也类似
公式:
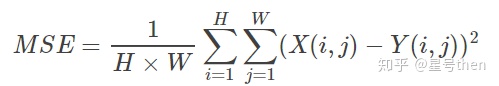
优点:计算复杂度低
缺点:和主观评价差距较大
2.2 峰值信噪比(Peak signal noise ratio, PSNR)
原理与框架:峰值信号的能量与噪声的平均能量之比,通常表示的时候取log变成分贝,由于MSE为真实图像与含噪图像之差的能量均值,而两者的差即为噪声,因此PSNR即峰值信号能量与MSE之比。PSNR是最普遍、最广泛使用的评鉴画质的客观量测法,虽然和人眼看到的视觉品质不完全一致,但目前仍作为对照其他指标的基线。
公式:
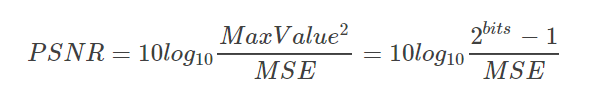
优点:计算复杂度低
缺点:和主观评价有一定差距,颜色变化会导致较低的分数
2.3 结构相似度(Structure similarity Index, SSIM)
原理与框架:人眼感知敏感性有三大特点:对空间频率较低的对比差异敏感度较高,人眼对亮度对比差异的敏感度较色度高,人眼对一个区域的感知结果会受到其周围邻近区域的影响,于是需要将色彩空间转换到HVS空间来进行评估。SSIM是从亮度、对比度与结构来对两幅图像的相似性进行评估。框图如下:
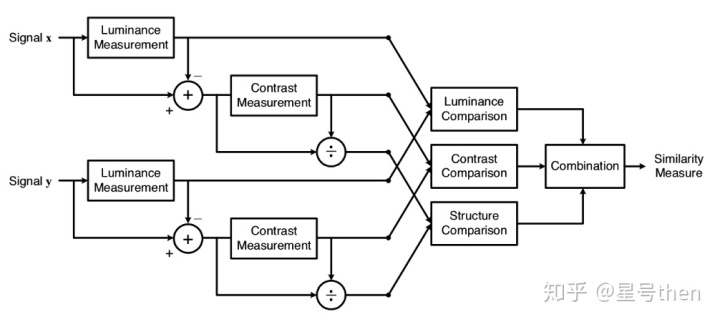
在实现上,亮度用均值来表示,对比度用均值归一化的方差表示,结构用相关系数即统计意义上的协方差与方差乘积比值来表征。此外,SSIM应用于局部可抵抗失真程度突变,效果会更好。实际是对各种局部窗口的SSIM做平均,并用高斯加权函数对每个局部的统计值进行加权防止出现块效应。
公式:(先求均值、方差、协方差,再求亮度因子、对比度因子、结构相似因子,最后将三个因子乘在一起)
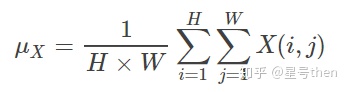
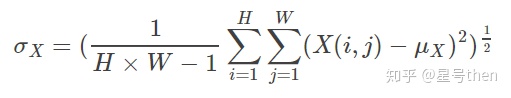
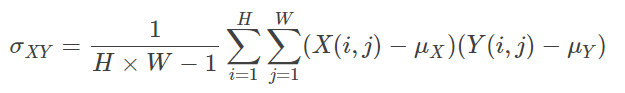
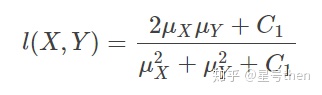
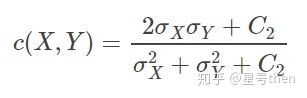
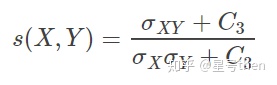
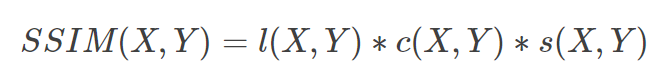
当C3 = C2/2时,SSIM可简化成

此外可以求其平均值,即MSSIM
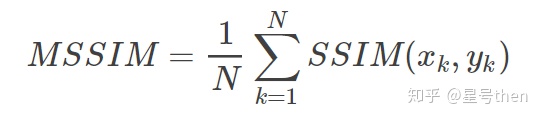
优点:通过感知结构信息来评价失真更接近人眼
缺点:人类视觉系统很是高度非线性的,仅仅比较两个信号结构的相似性是不够的,还有很大的空间未被挖掘
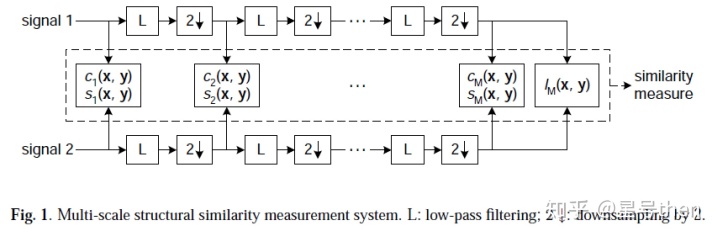
2.4 多尺度结构相似度(Multi Scale Structural Similarity Index, MS-SSIM)
原理与框架:图像细节的可感知性取决于图像信号的像素点密度、图像到观察者的距离以及观察者自身的感知能力。当这些因素不同时,对给定图像的主观评价也会不尽相同。比如一个1080P但较模糊的画面可能评分会比720P较锐利的画面评分还要高,故2.3的单尺度方法可能仅适用于特定场景,而多尺度方法是可以试用不同分辨率下的方法。框图如下:
公式:
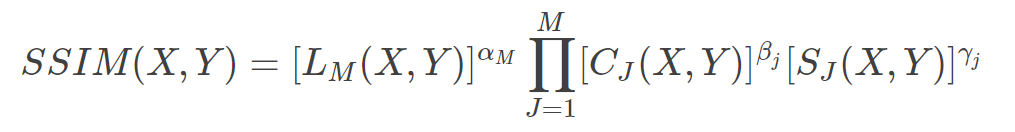
优点:相对于单尺度的SSIM能够适应不同分辨率与更广泛的场景
缺点:这种通过低通和下采样的方法仍比较粗糙,还没有充分利用人类视觉系统高度非线性的特点
2.5 恰可识别阈值(Just Noticeable Difference, JND)
原理与框架:JND模型主要考虑了HVS的亮度掩盖、纹理掩盖和时域掩盖的特性,采用非线性关系来对三者的效果进行叠加,其中亮度对比度阈值是通过像素点处局部平均背景亮度值加权得到,纹理检测通过4个方向的高通滤波器计算得到,且取最大为纹理阈值,接下来将这两种阈值相加,并加上其重叠效果,得到空间域的JND模型。在此基础上通过帧间亮度差异的分段函数,给出时域掩盖效果,乘以空间域JND模型,得到时空域的JND模型。此外,其变种还有在变换域上实现的,如DCT域或小波域。
公式:(先求亮度掩盖、纹理掩盖,再求空间域/时间域的JND,最后调整叠加参数常量获得最有结果)
亮度阈值:

纹理阈值:
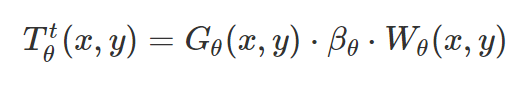
其中G是像素点(x,y)的边缘梯度,β是不同颜色通道的经验参数,W是高斯低通滤波器处理后的相关系数矩阵。
空域JND:
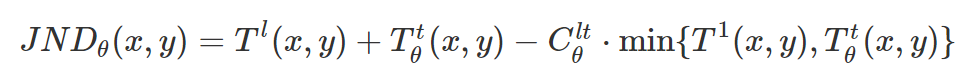
其中第一项Tl是亮度阈值的JNDfb(x,y),C是叠加常量,反映了两种掩盖的重叠程度。
优点:利用JND 比较接近HVS,符合人眼主观感知,甚至可以用该模型对失真图像进行修正来消除不可察觉误差
缺点:暂未发现
输出值含义:
JND 分值范围: 0~100 分, 0 分最好。
JND 值是以图像画面上的 32X32 像素块为计算单位,业界推荐的分析结果是:
JND=0 ,同等于原始图像;
JND=1 时,一般观察者察觉不出图像的损伤;
JND=3 时,一般观察者在专家的帮助下找出图像的损伤;
JND=10 时,一般观察者感到图像损伤;
JND>10 以上的视频压缩设备不能用于广播系统 ( 建议不将这样设备用做视频通信系统的信源设备 )
星号then:视频/图像质量评价综述(二)zhuanlan.zhihu.com

















 2934
2934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









