




 本文介绍了Scala中的特质,强调了它作为接口和抽象类的结合体,允许动态混入和叠加特质。接着讨论了嵌套类及其在Scala中的使用,特别是类型投影的概念。最后,探讨了Scala的隐式转换,包括隐式函数、隐式值和隐式类,以及它们如何扩展类的功能和处理类型转换。
本文介绍了Scala中的特质,强调了它作为接口和抽象类的结合体,允许动态混入和叠加特质。接着讨论了嵌套类及其在Scala中的使用,特别是类型投影的概念。最后,探讨了Scala的隐式转换,包括隐式函数、隐式值和隐式类,以及它们如何扩展类的功能和处理类型转换。
1.Scala 特质
从面向对象来看,接口并不属于面向对象的范畴,而Scala是纯面向对象的语言,所以在Scala中没有接口。Scala语言中,采用特质trait(特征)来代替接口的概念,也就是说,多个类具有相同的特征时,就可以将这个特质独立出来,采用关键字trait声明。 理解trait 等价于(interface + abstract class)
1.1 trait 的声明语法
trait 特质名 {
trait体
}
在 Scala 的 trait 中,它不但可以包括抽象方法、字段还可以包含普通字段和具体方法。在Scala中实现特质,如果没有继承其它类,那么实现第一个特质使用 extends 关键字,后面的使用 with 关键字,Scala中的特质可以多实现扩展,多个特质之间使用 with 关键字进行连接,所以如果你将Scala中的特质看做是一个抽象类或一个普通的类的话,那么相当于Scala间接实现了类的多继承,而如果将特质看成一个接口,那么它跟Java中的接口一样,多个特质之间可以多继承。

Scala的继承是单继承,也就是一个类最多只能有一个直接父类,这种单继承的机制可保证类的纯洁性,比c++中的多继承机制简洁。但对子类功能的扩展有一定影响,所以我们认为,Scala引入trait特质,既可以替代Java的接口, 也是对单继承机制的一种补充。

1.2 特质 trait 动态混入
除了可以在类声明时继承特质以外,还可以在构建对象时混入特质,扩展目标类的功能。动态混入是Scala特有的方式(java没有动态混入),可在不修改类声明/定义的情况下,即动态混入可以在不影响原有的继承关系的基础上,给指定的类扩展功能,非常的灵活,耦合性低 。


1.3 叠加特质trait
构建对象的同时如果混入多个特质,称之为叠加特质,那么特质声明顺序从左到右,方法执行顺序从右到左。
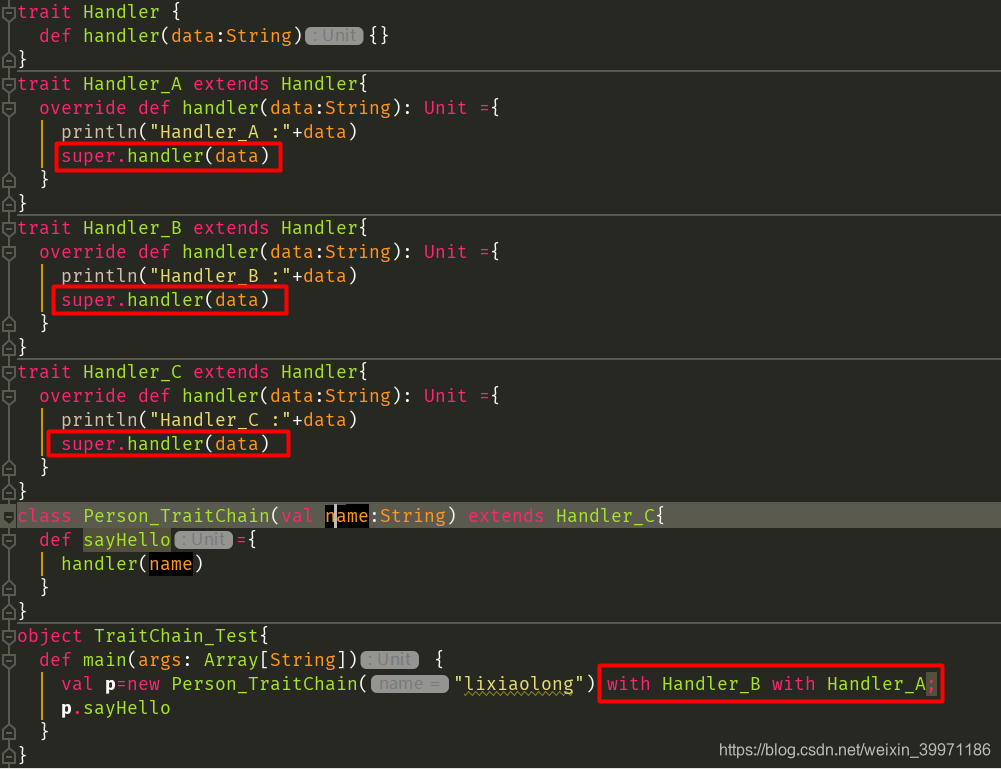
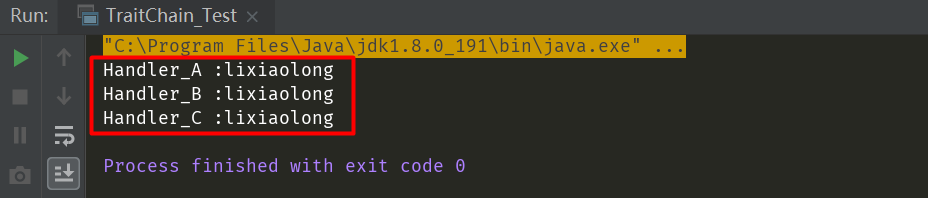
通过上面的案例结果,我们可以看出,在使用了trait特质动态混入并且在每个特质方法中使用super调用父特质的方法,最终程序执行顺序是从右向左,遇到super并不是去调用父特质的方法,而是向左边继续查找特质,然后依次执行上面三个特质的Handler_A、 Handler_B、Handler_C三个方法,如果上述案例中我们不在每个Handler_*方法中调用super.handler(data),那么最终的结果只是会执行Handler_A中的handler方法,所以特质的动态混入虽然灵活耦合性低,但是则需要我们对其原理有清晰的认识,在开发中使用trait动态混入时,则首先必须考虑其混入顺序问题!
叠加特质注意事项和细节:
① Scala叠加特质中,特质声明顺序从左到右,方法执行顺序从右到左
② Scala特质中如果调用super,并不是表示调用父特质的方法,而是向前面(左边)继续查找特质,如果找不到,才会去父特质查找
③ 如果想要调用具体特质的方法,可以指定:super[特质].xxx(…) 其中的泛型必须是该特质的直接超类类型
1.4 特质中重写父特质抽象方法
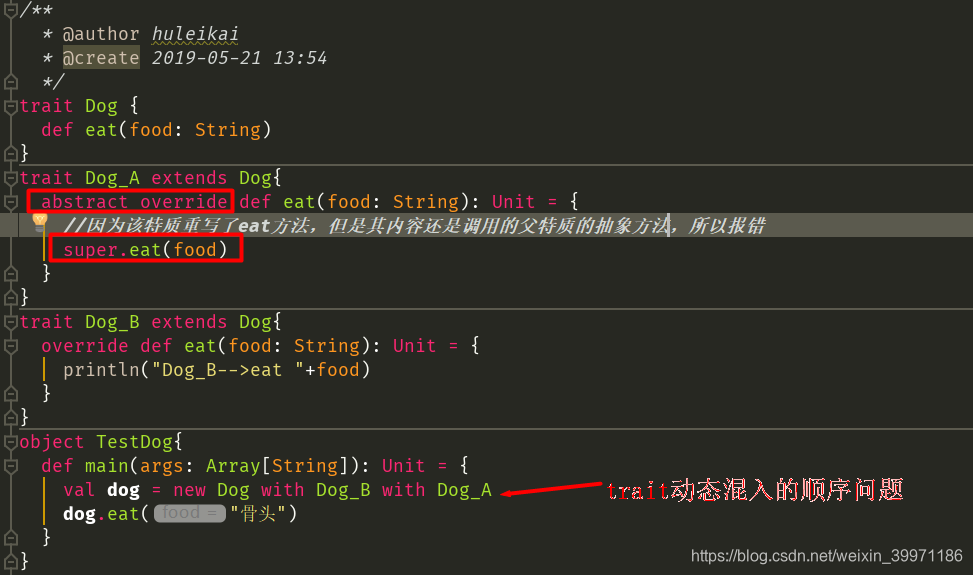
如上所示的案例中,特质Dog中有一个eat抽象方法,在Dog_A特质中重写了父特质Dog的eat抽象方法,但是其重写的内容只是调用了父特质的eat方法,没有其他具体的实现,这样重写完成后的方法还是一个抽象方法,如果我们不给该方法添加 abstract override 关键字,则运行会报错,当我们给某个方法增加了abstract override 后,就是明确的告诉编译器,该方法确实是重写了父特质的抽象方法,但是重写后,该方法仍然是一个抽象方法。当我们在main方法中 new Dog with Dog_B with Dog_A 使用动态混入时,此时程序会先执行Dog_A中的eat方法,然后执行到 super.eat(food) 此时会向左调用Dog_B中的eat方法进行执行,但我们需要注意这种情况下动态混入的顺序问题,如果上述案例将混入顺序换成 new Dog with Dog_A with Dog_B ,那代码将会运行报错!
1.5 特质中的具体字段和抽象字段
特质中可以定义具体字段,如果初始化了就是具体字段,如果不初始化就是抽象字段。混入该特质的类就具有了该字段,字段不是继承,而是直接加入类成为本类的字段,其底层就是生成对应修饰符为private的属性。
特质中未被初始化的抽象字段在具体的子类中必须被重写!
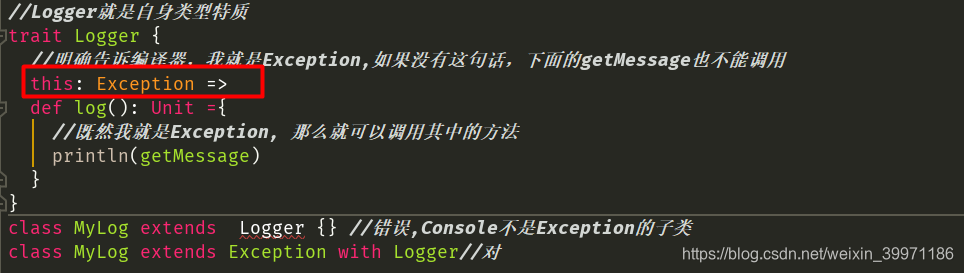
1.6 特质trait自身类型
自身类型:主要是为了解决特质之间的循环相互依赖问题,同时可以确保特质在不扩展某个类的情况下,依然可以做到限制混入该特质的其他类的类型。
2.Scala 嵌套类
在Java中,一个类的内部又完整的嵌套了另一个完整的类结构。被嵌套的类称为内部类(inner class),嵌套其他类的类称为外部类。内部类最大的特点就是可以直接访问私有属性,并且可以体现类与类之间的包含关系。在Scala中,你几乎可以在任何语法结构中内嵌任何语法结构,如在类中可以再定义一个类,这样的类就是嵌套类,嵌套类类似于Java中的内部类。
Scala嵌套类的使用:
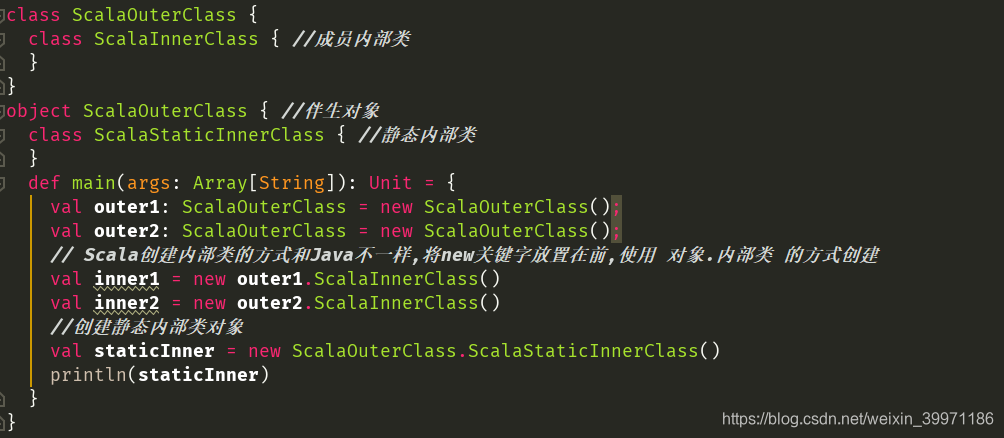
在内部类中访问外部类的属性:
① 内部类如果想要访问外部类的属性,可以通过外部类对象访问。即:访问方式:外部类名.this.属性名
② 内部类如果想要访问外部类的属性,也可以通过外部类别名访问。即:访问方式:外部类名别名.属性名
class ScalaOuterClass {
myOuter => //这样写,你可以理解成这样写,myOuter就是代表外部类的一个实例对象.
//当给外部指定别名时,需要将外部类的属性放到别名后.
var name : String = "scott"
private var sal : Double = 1.2
class ScalaInnerClass { //成员内部类
def info() = {
println("name = " + ScalaOuterClass.this.name + " age =" + ScalaOuterClass.this.sal)
println("-----------------------------------")
println("name = " + myOuter.name + " age =" + myOuter.sal)
}
}
}
注意:当给外部指定别名时,需要将外部类的属性放到别名后!
Scala中的嵌套类——类型投影:
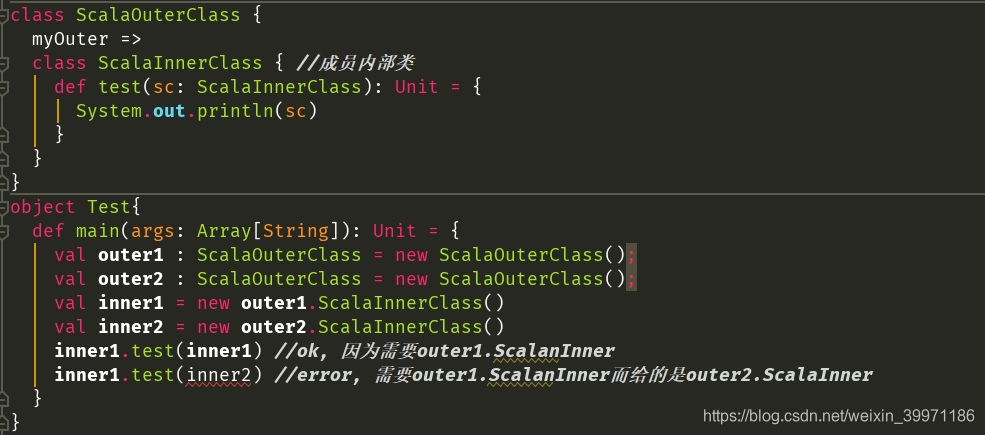
在上面的这个案例中,Java中的内部类从属于外部类,因此在java中 inner.test(inner2) 就可以,因为是按类型来匹配的,而Scala中内部类从属于外部类的对象,所以外部类的对象不一样,创建出来的内部类也不一样,无法互换使用。
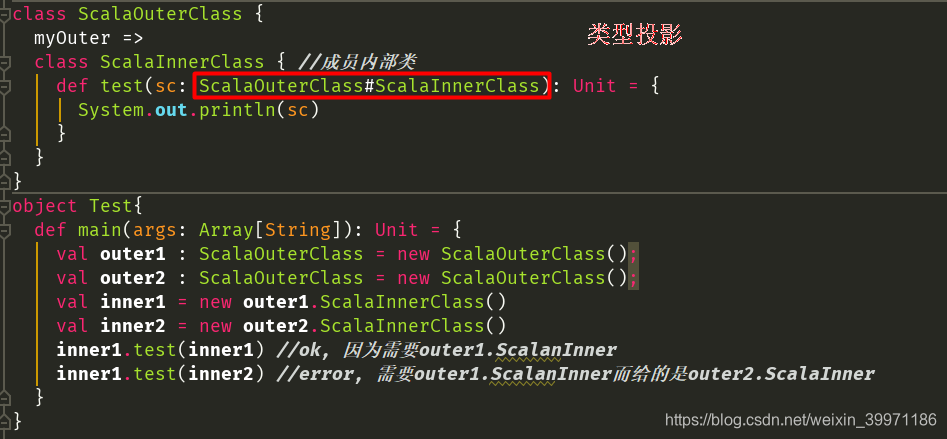
类型投影:在方法声明上,如果使用 外部类#内部类 的方式,表示忽略内部类的对象关系,等同于Java中内部类的语法操作,我们将这种方式称之为类型投影(即:忽略对象的创建方式,只考虑类型)
3.Scala 隐式转换
3.1 隐式函数
隐式转换函数是以 implicit 关键字声明的带有单个参数的函数。这种函数将会自动应用,将值从一种类型转换为另一种类型,使用隐式函数可以优雅的解决数据类型转换。

反编译之后看底层源码一目了然:
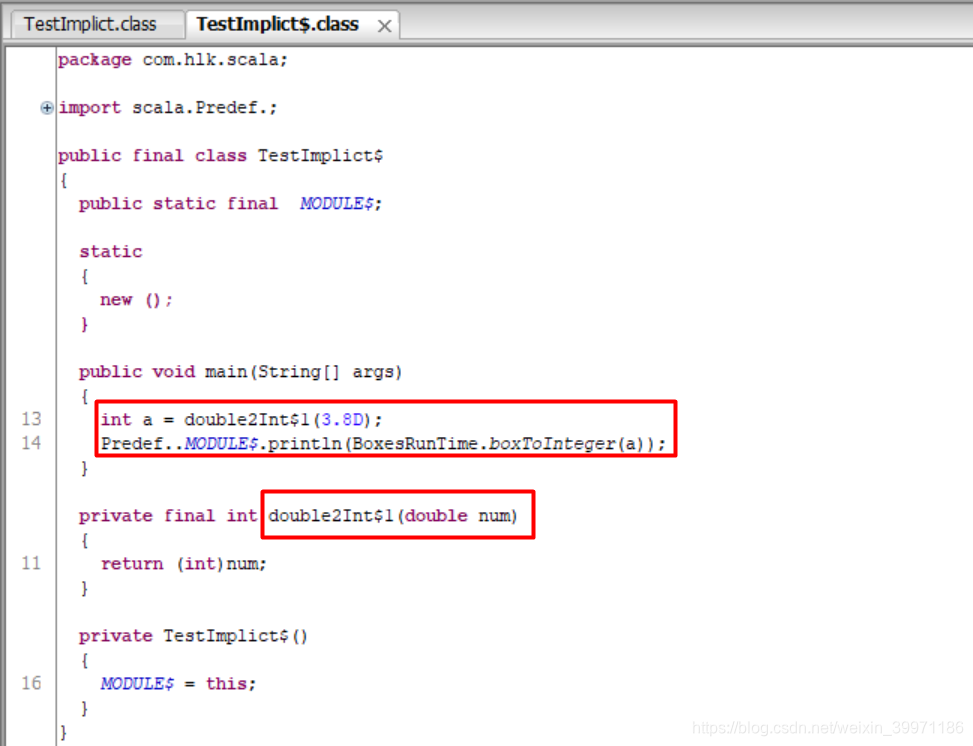
隐式转换的注意事项和细节:
① 隐式转换函数的函数名可以是任意的,隐式转换与函数名称无关,只与函数签名(函数参数类型和返回值类型)有关
② 隐式函数可以有多个,但是需要保证在当前环境下,只有一个隐式函数能被识别使用
//在当前环境中,不能存在满足条件的多个隐式函数
implicit def a(d: Double) = d.toInt
implicit def b(d: Double) = d.toInt
val num: Int = 3.5 //(X)在转换时,编译器识别出有两个方法可以被使用,不知道调用哪一个
println(num)
3.2 隐式转换动态增加功能
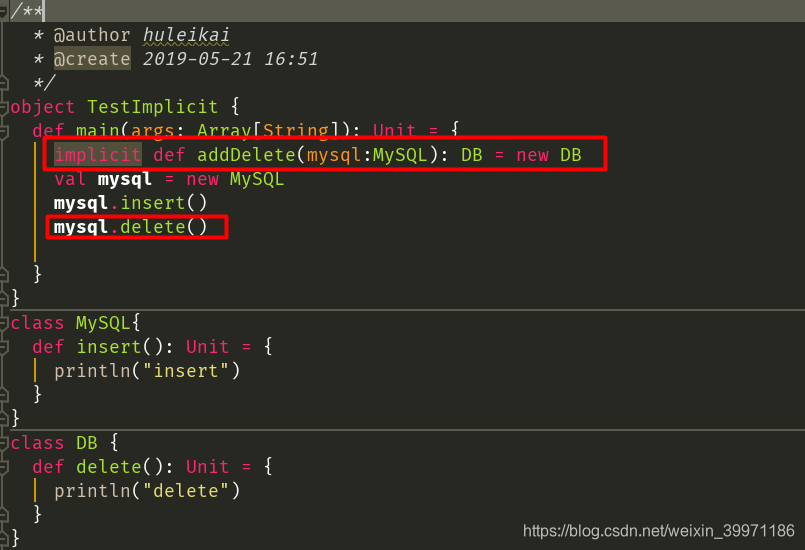
反编译后的字节码文件:
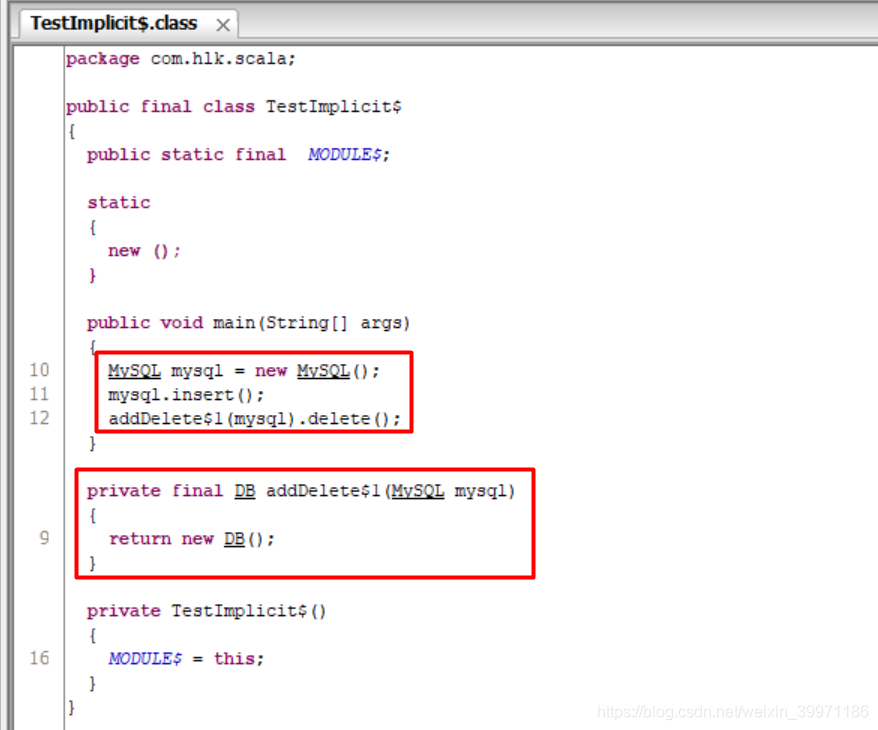
如上案例,MySQL类只有一个已经存在的 insert 方法,如果现在需要在不更改源代码的前提下,动态的给MySQL类增加一个delete方法,就可以使用我们Scala中的隐式转换动态增加功能,这个有点类似Spring框架中的AOP。
3.3 隐式值
隐式值也叫隐式变量,即将某个形参变量标记为implicit,编译器会在方法省略隐式参数的情况下去搜索作用域内的隐式值作为缺省参数。
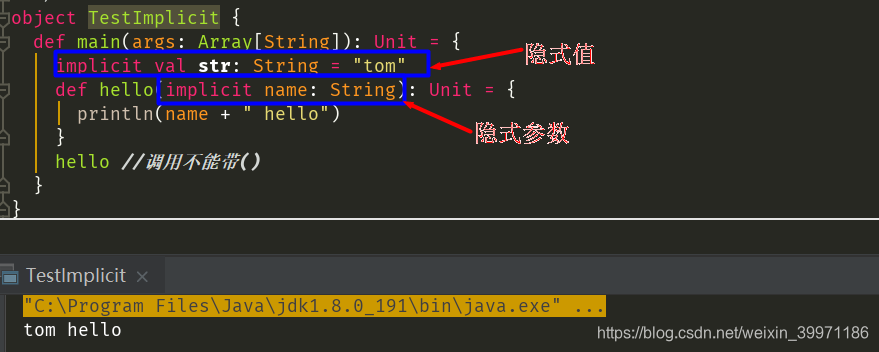
注意:形参的默认值的优先级是低于使用implicit声明的变量的,如果声明了一个隐式值,同时也在形参上给了默认值,那么最终的值就是优先级高的隐式值。
3.4 隐式类
在 Scala2.10 后提供了隐式类,可以使用 implicit 声明类,隐式类的非常强大,同样可以扩展类的功能,比前面使用隐式转换动态增加功能更加的方便,在集合中隐式类发挥着重要的作用。
隐式类使用特点:
① 隐式类所带的构造参数有且只能有一个
② 隐式类必须被定义在 " 类 " 或 " 伴生对象 " 或 " 包对象 " 里,即隐式类不能是顶级的(top-level objects)
③ 隐式类不能是 case class 样例类
④ 作用域内不能有与之相同名称的标识符
隐式类案例:
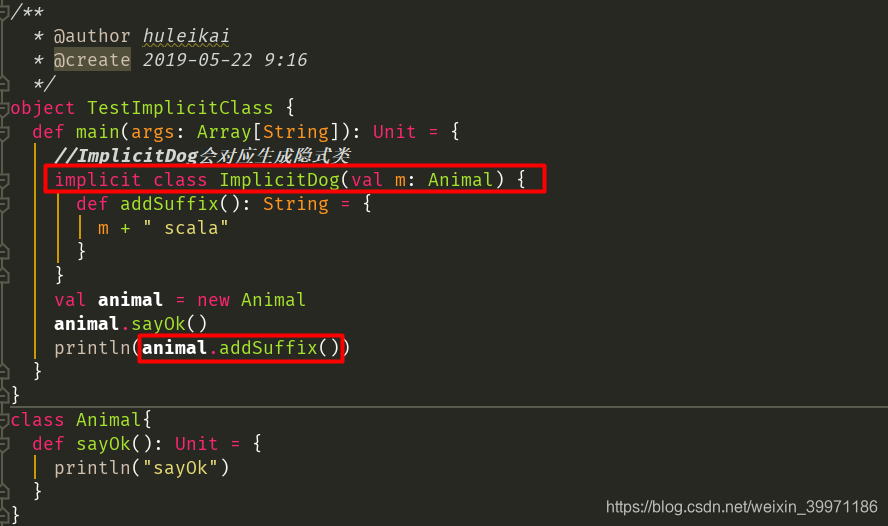
运行后结果:
反编译后的底层源码:
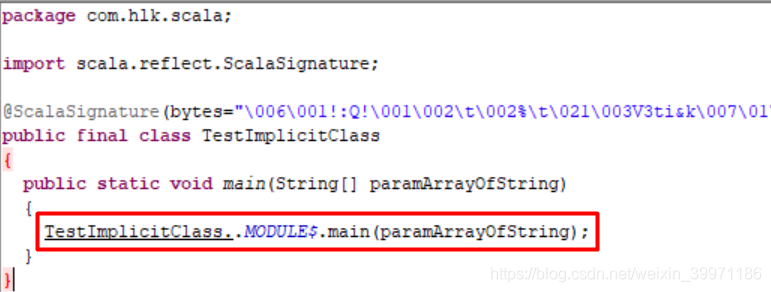
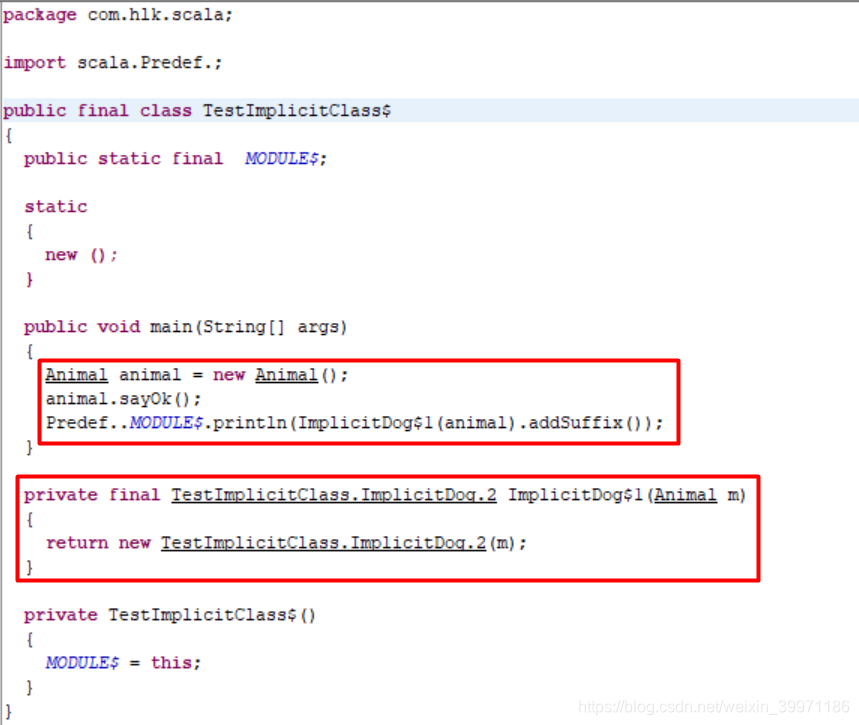
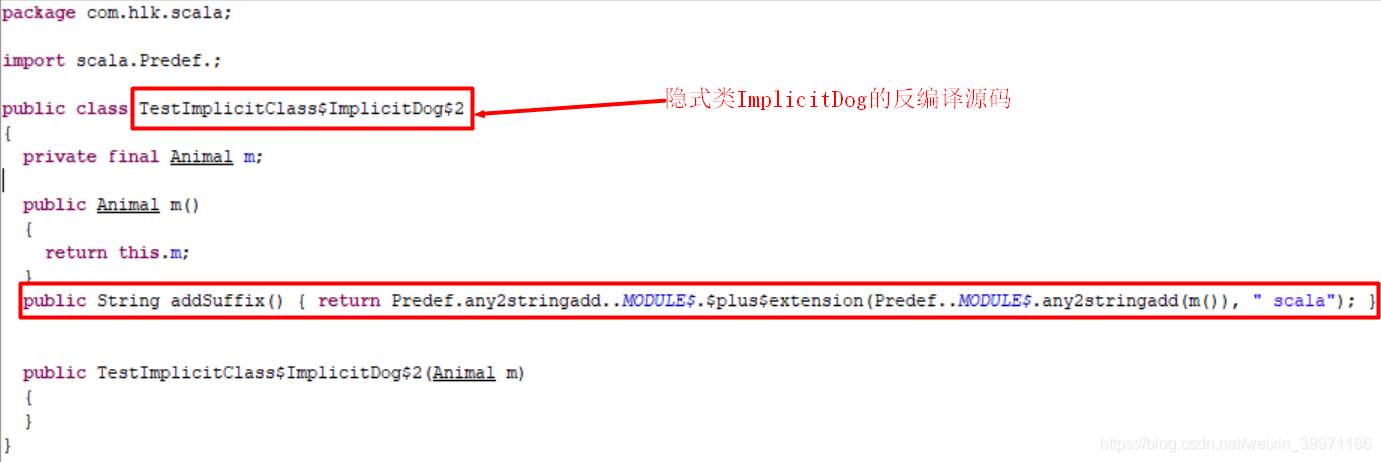
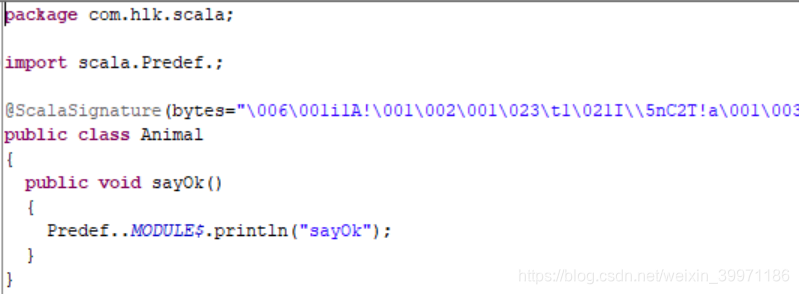
可能小伙伴看的有点乱,下面来简单总结哈,上面我们写了一个object TestImplicitClass 伴生对象,对应反编译之后的两个文件TestImplicitClass 和 TestImplicitClass$,在Scala中当我们只写一个伴生对象时,编译器自动会帮我们生成对应的伴生类,即TestImplicitClass就是编译器生成的伴生类,而TestImplicitClass$则是我们写的伴生对象,我们在object中写的所有代码最终都是在TestImplicitClass$中,而调用是在TestImplicitClass伴生类的main方法中,伴生类和伴生对象之间使用 MODULE$ 进行调用。当上面案例中的代码执行到 println(animal.addSuffix()) 之前,编译器则会调用TestImplicitClass$伴生对象中的ImplicitDog$1(Animal m) 方法,将 val animal = new Animal 的animal对象传入 ImplicitDog$1(animal),而这个ImplicitDog$1方法中则会调用隐式类 public TestImplicitClass$ImplicitDog$2(Animal m){} 的构造器,返回一个隐式类的对象,所以我们在不知不觉的情况下就进行了隐式类型转换,animal对象就可以调用自己没有的方法,如果不看底层源码是不是感觉还是很神奇呢!
隐式转换的时机:
① 当方法中的参数的类型与目标类型不一致时
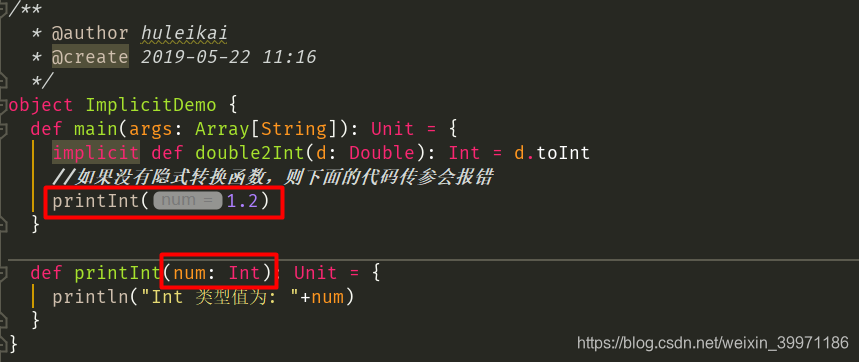
② 当对象调用所在类中不存在的方法或成员时,编译器会根据类型自动将对象进行隐式转换
隐式解析机制:
即编译器是如何查找到缺失信息的,解析具有以下两种规则:
1)首先会在当前代码作用域下查找隐式实体(隐式方法、隐式类、隐式对象、隐式值)(一般是这种情况)
2)如果按照第一条规则查找隐式实体失败,则会继续在隐式参数的类型的作用域里查找。类型的作用域是指与该类型相关联的全部伴生对象,一个隐式实体的类型T它的查找范围如下(第二种情况范围广且复杂在使用时,应当尽量避免出现):
① 如果T被定义为T with A with B with C,那么A、B、C都是T的部分,在T的隐式解析过程中,它们的伴生对象都会被搜索
② 如果T是参数化类型,那么类型参数和与类型参数相关联的部分都算作T的部分,比如List[String]的隐式搜索会搜索List的伴生对象和String的伴生对象
③ 如果T是一个单例类型p.T,即T是属于某个p对象内,那么这个p对象也会被搜索
④ 如果T是个类型注入S#T,那么S和T都会被搜索
隐式转换注意事项:
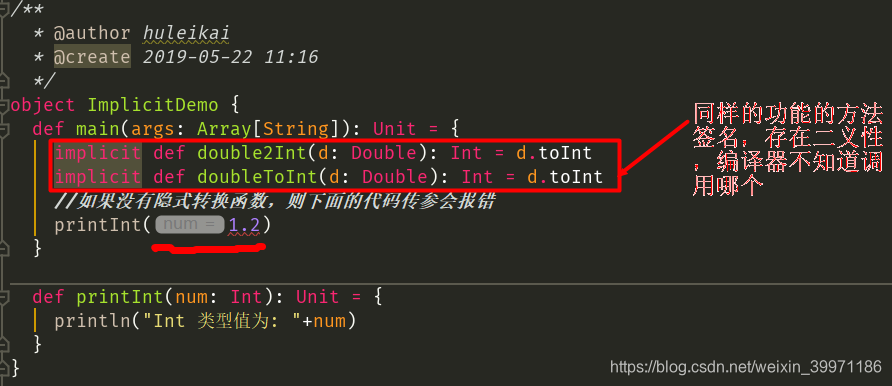
① 隐式转换不能存在二义性
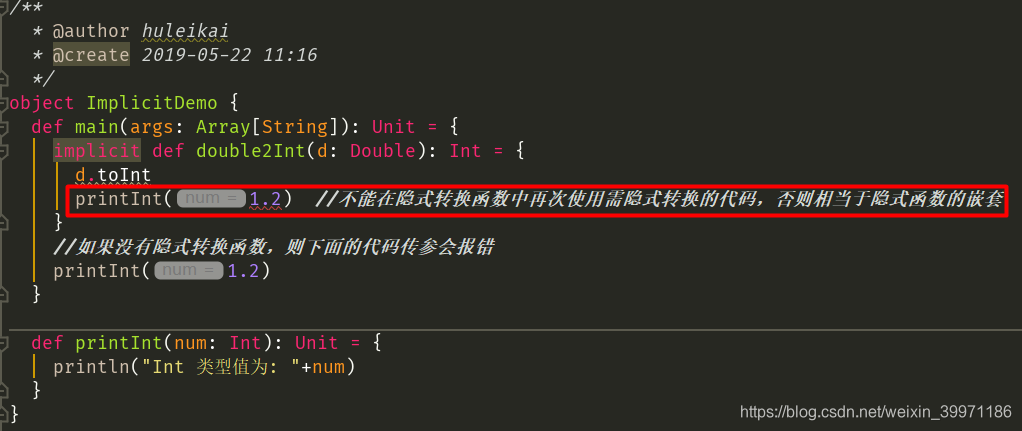
② 隐式操作不能嵌套使用

















 171
171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









