




分享一个关于video-based person re-ID的失败的工作:Attribute-aware Identity-hard Triplet Loss for Video-based Person Re-identification。
利用视频行人属性识别辅助提升视频行人重识别性能的工作,通过充分地在视频行人重识别的过程中应用行人属性的信息,通过:1. 利用行人视频间的属性预测结果相似度改进triplet loss,减小类内距离,2. 迁移在行人属性识别过程中学习到的spatial-temporal attention到行人重识别中。我们目前的模型能够不添加任何复杂结构的ResNet-50(不要花里胡哨)上达到:
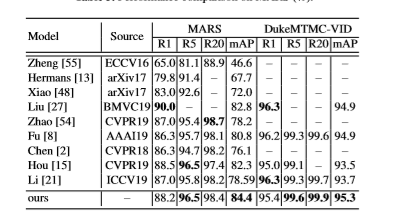
MARS:R1 88.2 mAP 84.4%
Duke:R1 95.4 mAP 95.3%代码也是在罗浩博士和高继扬博士的代码基础上进行的迭代,开源在:
https://github.com/yuange250/Video-based-person-ReID-with-Attribute-informationgithub.com工作了精力有限,整理仓促,代码里可能有遗留的bug,欢迎指正~
这也算是凝聚了自己从研二一年所有心血的工作,但结局实在是凄惨。经历了ICCV2019狗血临头的review然后大改,随后CVPR2020加这次ECCV2020依然不被审稿人认可,现在虽然心有不甘,但接二连三的失利也实实确确地让自己认识到了这篇文章的完成度和novelty确实达不到顶会的要求。
而目前毕业了,客观条件已经不允许我再去完善这一篇工作或者提升工作的novelty,所以就在这里简单地介绍一下,同时开源。video-based person reid 是一个大家都不太喜欢开源的方向,和之前开源的baseline一样,如果自己的工作能让更多希望继续这个方向上的做点东西(虽然并不建议)出来的师弟师妹们有所帮助,那这个工作便不会那么没有意义。
论文挂在了arxiv:
https://arxiv.org/pdf/2006.07597.pdfarxiv.org同时对于需要一个相对比较高且可复现的baseline的同学,参见之前开源的baseline:
陈志远:视频行人重识别的一个不太强的baselinezhuanlan.zhihu.com
行人属性辅助视频行人重识别
为什么做这个topic?因为没人做过,唯一类似的是CVPR2019的Attribute-Driven Feature Disentangling and Temporal Aggregation for Video Person Re-Identification做了迁移学习,利用在RAP库上学习到的属性注意力迁移到视频行人重识别中。而我们第一次用了MARS和Duke精准到视频为单位的属性标注,当然也是我们自己标注的,具体标注数据开放在:
http://irip.buaa.edu.cn/mars_duke_attributes/index.htmlirip.buaa.edu.cn要用的话,记得引用一下哦(标注的时候看行人视频看到我眼都花了):
@InProceedings{
author="Chen, Zhiyuan and Li, Annan and Wang, Yunhong",
title="A Temporal Attentive Approach for Video-Based Pedestrian Attribute Recognition",
booktitle="Pattern Recognition and Computer Vision",
year="2019"
}要解决的问题
1. 视频行人重识别Triplet Loss收敛后类内距离过大的问题

Batch-hard Triplet Loss收敛之后,每个anchor到对应的正样本的距离都大于到负样本的距离,此时Loss已经全为0,不再更新,但anchor到每个正样本之间的距离,即类内距离还有可能很大,每个anchor行人视频还是更倾向于接近与其观察角度、外表更接近的正样本。这种情况就不太利于模型剥离对观察角度相近性的依赖,不利于进一步的收敛。
解决方法
利用属性相似度在anchor的正样本中确定类内negative(类内属性预测结果相似度最大,即观察角度、外表相似度与anchor最接近)和类内positive(类内属性预测结果相似度最小,即观察角度、外表相似度与anchor最不接近),在类内再做一次triplet loss,保证每个anchor到类内positive和类内negative的特征距离要尽可能的一致。配合正常的Batch-hard Triplet Loss,模型能够正常收敛,同时类内差距的问题能得到一定的缓解,也能得到更好的Re-ID结果。具体细节如下图:

为什么不用特征距离来确定类内的positive和negative,因为特征这种高维语义用来确定类内正负样本很容易受噪音影响,导致过拟合(强行解释一波)。你要问我怎么证明,我也只能用实验来证明。ablation study里对比了一下用属性相似度和特征距离来确定类内正负样本之间带来的性能差异,结果是属性相似度更好,有兴趣的同学可以翻一下论文。
2. 迁移属性识别过程中学习到的spatial-temporal attention到行人重识别过程中
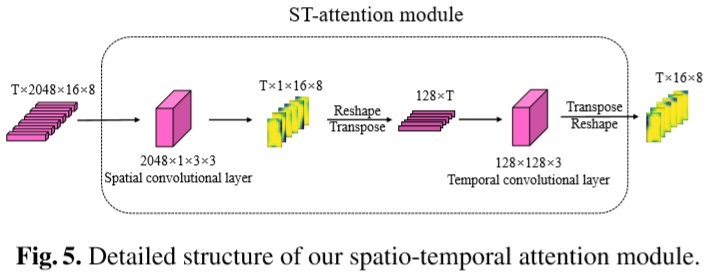
俗不可耐老生常谈的attention部分来了,你要问它有没有用,肯定有用啊,加了额外的参数和额外的监督信息,你要说他怎么产生的效果,那我肯定给你摆实验结果,外加看几张attention热力图啊。没办法,这个点是一定要做的,但我又实在被这个模块俗到了,所以就简单提一下,大家有兴趣可以看看论文和代码实现,没兴趣就跳过吧~就是把迁移属性识别过程中学习到的spatial-temporal attention到行人重识别过程中
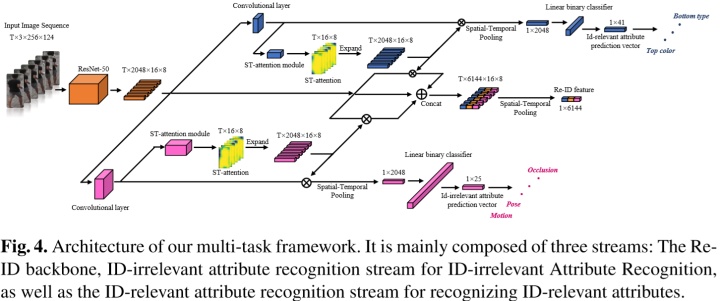
ST-Attention模块
老铁们,简简单单搭个积木!
实验结果
跟sota的比对
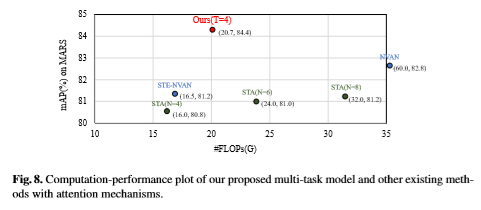
速度优势
没做fancy的模型结构改造,就加了属性信息,所以就一个朴素的ResNet-50(当然也加了一个小的self spatial-temporal attention模块,参数量可忽略不计)。
消融实验
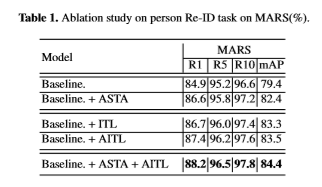
ASTA是迁移属性学到的时许注意力到baseline的结果,可以看到明显提升。ITL使用特征距离确定类内正负样本对的结果,AITL是利用行人视频间的属性识别结果的相似度确定类内正负样本对,可以看到用属性相似度得到的结果相对更好。这里的实验中,baseline还没有调到之前的开源的https://zhuanlan.zhihu.com/p/96823244中的结果,不过相对也算比较高的了。
属性时空注意力机制都注意到了啥:
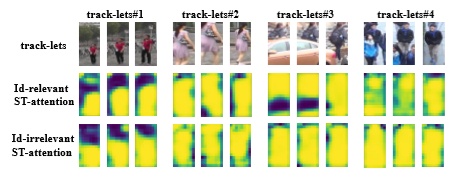
上图是属性的注意力heatmap,我们将行人属性分为了身份相关属性(衣服颜色,性别等)和身份无关属性(行人对摄像头角度,行人运动状态等),可以看到不同类型的属性对行人不同区域的关注是不同的。(其实我觉得CV任务CNN里的attention很难说明白是参数增多带来的信息增益,还是本身attention机制让网络关注到了重要的部分,因为多层叠加的卷积层感受野足够大,本身自带attention)但是通过利用行人属性增加信息量,从增大信息量的角度出发解释属性attention对re-ID带来的提升还是讲得通的,只是我除了实验的手段无法证明这一点。
然后我们也探究了不同类型属性对Re-ID的增益效果,总体来看还是身份相关属性对行人重识别的增益最大,如下图:
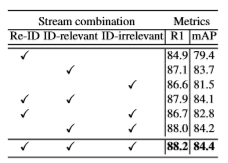
类内triplet loss为什么带来了性能提升
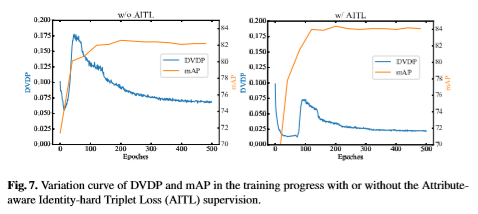
我们记录了没用AITL(基于属性预测结果相似度的类内Triplet Loss) 和用了之后的DVDP和mAP在训练中的变化曲线,解释一下DVDP( Distance Variance among Different Positives):就是Batch-hard Triplet Loss训练过程中,对于每个anchor,找到与其距离最小的同类特征距离和与其距离最大的同类特征距离,计算两个距离的差值,对同batch中此差值求和,即DVDP。衡量的是每个anchor到其所有正样本距离的均匀程度。
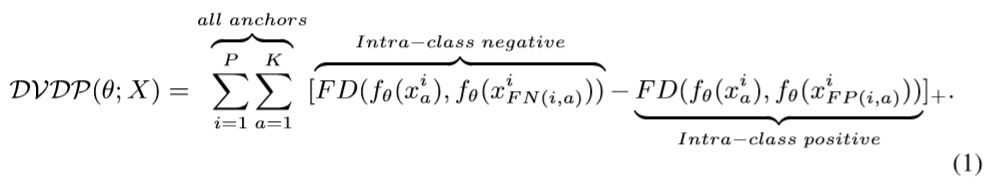
可以看到,用了AITL之后,DVDP明显下降带来的也就是性能提升。
跨个库看看吧
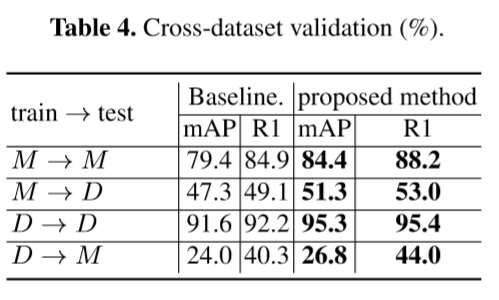
就那么回事吧,没有提升多少,但至少引入了上面两个点后,没有带来过拟合。
后记
说实话,这个领域做了一年半,净tm调参了,真正扎实有用对学界有一定贡献的工作可能就是标了两个属性数据库。。。。毕业了这个方向可能就暂时告一段落了吧,这里先画个句号,未来戒骄戒躁,踏踏实实在工作面向的领域学点有用的东西。
最后说点没用的。
不要因为看到两篇明显靠运气中的顶会就抱侥幸心理,觉得顶会不过如此,然后拿着不够格的作品去跃跃欲试,然后没别人那个运气就怨天尤人(曾经的我)。踏踏实实,步步为营,对得起大家,也对得起自己。做学术如此,工作如此,做人亦是如此吧。加油!

















 2308
2308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









