






 这篇博客展示了如何使用Python进行文本处理,包括读取文本、使用jieba进行分词、统计词频、去除标点符号、转换为小写、过滤常见无语义词汇,并输出出现频率最高的20个词。
这篇博客展示了如何使用Python进行文本处理,包括读取文本、使用jieba进行分词、统计词频、去除标点符号、转换为小写、过滤常见无语义词汇,并输出出现频率最高的20个词。
q = open('遇见.txt', 'r', encoding='utf-8').read()
wordsls = jieba.lcut(q)
wcdict = {}
for word in wordsls:
if len(word) == 1:
continue
else:
wcdict[word] = wcdict.get(word, 0) + 1
wcls = list(wcdict.items())
wcls.sort(key=lambda x: x[1], reverse=True)
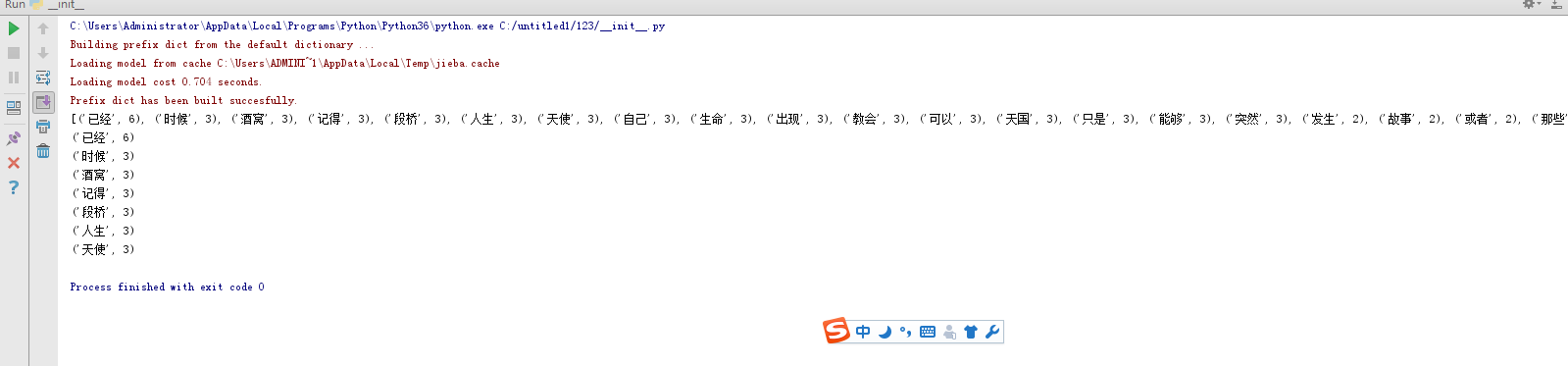
print(wcls)
for i in range(7):
print(wcls[i])
#准备utf-8编码的文本文件,通过文件读取字符串str
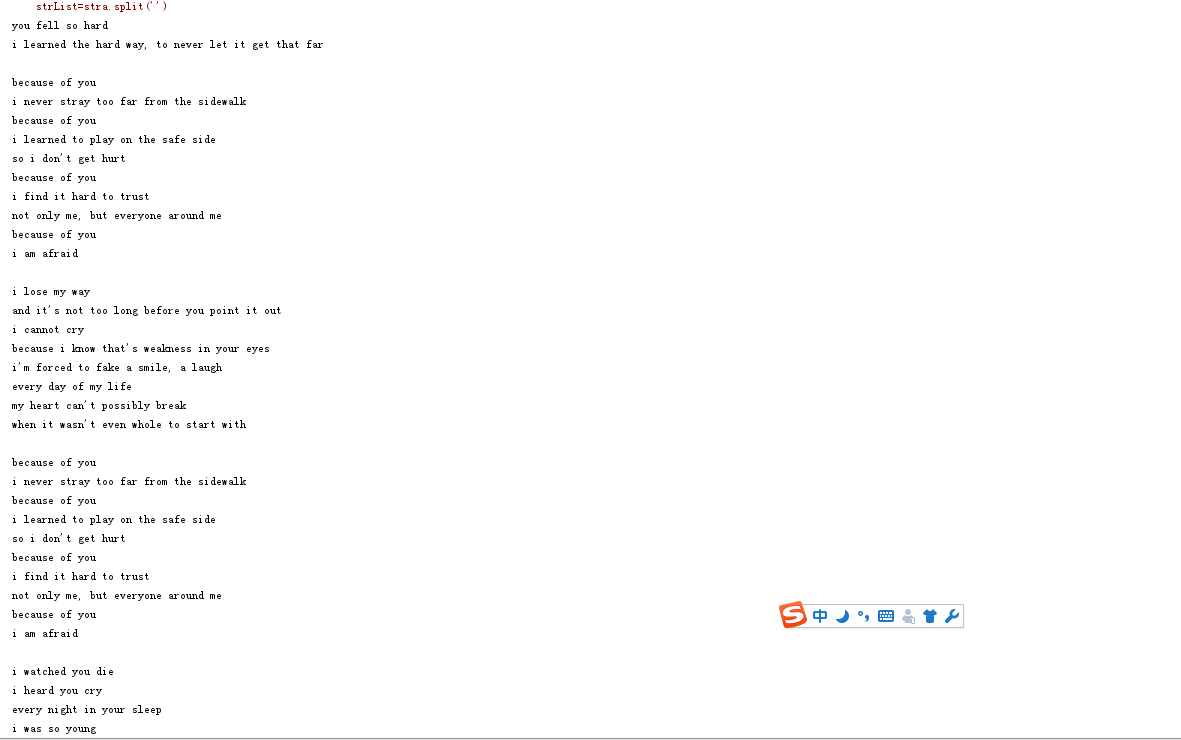
fo=open('because of you.txt','r',encoding='utf-8')
stra = fo.read().lower()
fo.close()
print(stra)
sep=',.;!'
for ch in sep:
stra = stra.replace(ch,'')#进行预处理,清除掉sep中存在的标点符号
print(stra)
strList=stra.split('')
print(len(strList),strList)#分解提取单词,转化为列表list
strSet = set(strList)
print(len(strSet),strSet)#转化为集合
strDict={}
for world in strSet:
strDict[world] = strList.count(world)
print(len(strDict),strDict)#转化为字典,计算上一个集合中每个单词出现的次数
wcList=list(strDict.items())
print(wcList)#将字典中的目录转化为列表输出
wcList.sort(key=lambda x:x[1],reverse= True)
print(wcList) #按降序输出
e = {'a','the','an','and','i','or','of'}
strSet = strSet - e
print(len(strSet),strSet) #排除语法型词汇,代词、冠词、连词等无语义词
for i in range(20):
print(wcList[i]) #TOP20输出




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









