







1.问题引入
通常的编码方式有固定长度编码和不定长度编码两种。哈夫曼编码是不定长度编码的一种,它利用字符的使用频率来编码,经常使用的字符编码较短,不常使用的字符编码较长。目的是为了总的编码长度最短,空间效率最高,它是由数学家Huffman在1952年提出的。

不定长编码需要解决两个关键问题:
编码尽可能短:让使用频率高的字符编码较短,使用频率低的编码较长,这种方法可以提高压缩率,节省空间,也能提高运算和通信速度。
不能有二义性:任何一个字符的编码不能是另一个字符的前缀,即前缀码特性,例如不能有“10”和“101”这样的编码。
2.算法设计
哈夫曼编码的基本思想是以字符的使用频率作为权值构建一颗哈夫曼树,然后利用哈夫曼树对字符进行编码。构造一棵哈夫曼树,是将要编码的字符作为叶子节点,该字符在文件中的使用频率作为叶子节点的权值,以自底向上的方式,通过n-1次的“合并”运算后构造出一棵树。核心思想是权值越大的叶子离根越近。
哈夫曼编码采取的贪心策略是每次从树的集合中取出没有父节点且权值最小的两棵树作为左右子树,构造一棵新树,新树根节点的权值为其左右孩子节点权值之和,将新树插入到树的集合中,继续使用贪心策略进行选择,直到树的集合中只剩一棵树时结束。
3.算法图解
假设现在有一些字符和它们的使用频率
表1 字符频率
字符
a
b
c
d
e
f
频率
0.05
0.32
0.18
0.07
0.25
0.13
我们可以把每一个字符作为叶子,它们对应的频率作为其权值,为了方便,可以对其同时扩大100倍,得到a~f分别对应5, 32, 18, 7, 25, 13
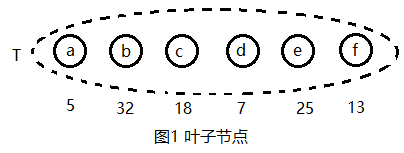
(1) 初始化:构建单结点树集合T = {a, b, c, d, e, f},如图1所示。
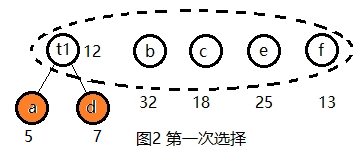
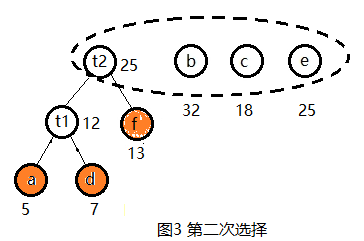
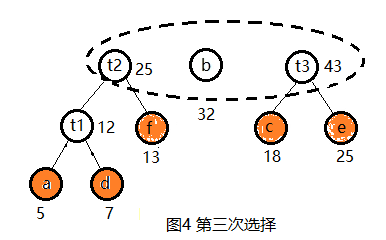
(2) 选择,具体过程见图2~图6
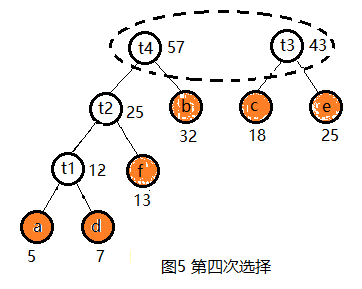
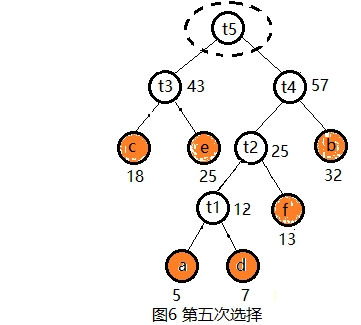
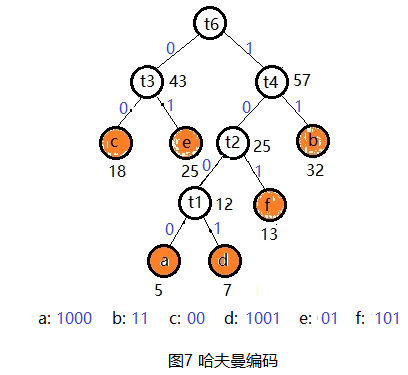
(3) 哈夫曼树构造成功后,约定左分支编码为0,右分支编码为1,如图7所示。
4.代码实现
//贪心实现Huffman编码
#include
#include
#include
const int INF = 1e7;
using namespace std;
// 定义存储Huffman节点的结构体
struct HNode{
double weight; // 权值
int parent; // 父节点id
int lchild; // 左孩子id
int rchild; // 右孩子id
char sign; // 该节点标识
};
// 定义存储Huffman编码的结构体
struct HCode {
char sign; // 当前的字符标识
string codeStr; // 存储编码的字符串
};
// 构造Huffman树
vector HuffmanTree(int n) {
// 定义Huffman结点,n个字符需要构造哈夫曼树2 * n - 1
vector tree(2 * n - 1);
// 初始化
for (int i = 0; i < 2 * n - 1; i++) {
tree[i].weight = 0;
tree[i].parent = -1;
tree[i].lchild = -1;
tree[i].rchild = -1;
}
cout << "请分别输入" << n << "个节点的标识和权值(以空格隔开):" << endl;
for (int i = 0; i < n; i++) {
cin >> tree[i].sign >> tree[i].weight;
}
// 构建二叉树(n-1次合并)
for (int i = 0; i < n - 1; i++) {
int node1 = -1, node2 = -1; // node1和node2是要找的权值最小和次小的树的根节点
double wet1 = INF, wet2 = INF; // 上述node1和node2对应的权值
// 每次循环时都会有新的节点生成,n+i表示当前所有树的总结点
for (int j = 0; j < n + i; j++) {
if (tree[j].weight < wet1 && tree[j].parent == -1) {
node2 = node1;
wet2 = wet1;
node1 = j;
wet1 = tree[j].weight;
}
else if (tree[j].weight < wet2 && tree[j].parent == -1) {
node2 = j;
wet2 = tree[j].weight;
}
}
// 更新树(n+i为新树的根id)
tree[n + i].lchild = node1;
tree[n + i].rchild = node2;
tree[node1].parent = n + i;
tree[node2].parent = n + i;
// 新节点的权值
tree[n + i].weight = wet1 + wet2;
//cout << tree[node1].sign << " and " << tree[node2].sign << " " << endl;
}
return tree;
}
// Huffman编码(从树自底向上得到每个叶节点的Huffman编码)
vector HuffmanCode(vector& tree, int n ) {
// 定义存储各个字符编码的HCode数组
vector codes;
int cur, p; // 当前节点的id和当前节点的父id
for (int i = 0; i < n; i++) {
HCode hc;
hc.sign = tree[i].sign;
// 初始化cur和p
cur = i;
p = tree[cur].parent;
while (p != -1) {
// 判断当前节点属于左孩子还是右孩子
if (tree[p].lchild == cur) {
hc.codeStr.insert(hc.codeStr.begin(), '0');
}
else
hc.codeStr.insert(hc.codeStr.begin(), '1');
// 更新cur和p
cur = p;
p = tree[cur].parent;
}
codes.push_back(hc);
}
return codes;
}
// 打印各个字符的Huffman编码
void PrintHuffmanCode(vector& codes) {
cout << endl;
for (const auto & a : codes) {
cout << a.sign << " 的Huffman编码为: " << a.codeStr << endl;
}
}
int main() {
int n;
cout << "请输入要编码的字符的个数:" << endl;
cin >> n;
vector tree = HuffmanTree(n);
vector codes = HuffmanCode(tree, n);
PrintHuffmanCode(codes);
return 0;
}
5.实验结果
请输入要编码的字符的个数:
6
请分别输入6个节点的标识和权值(以空格隔开):
a 0.05
b 0.32
c 0.18
d 0.07
e 0.25
f 0.13
a 的Huffman编码为: 1000
b 的Huffman编码为: 11
c 的Huffman编码为: 00
d 的Huffman编码为: 1001
e 的Huffman编码为: 01
f 的Huffman编码为: 101
D:\projects\test\x64\Release\test.exe (进程 12116)已退出,返回代码为: 0。
6.算法优化分析
当前的算法时间复杂度为O(n^2),主要小号在构建哈夫曼树的方法上,函数HuffmanTree找两个权值时可以使用优先队列,时间复杂度为logn,因此总的时间复杂度可以降为O(nlogn)。
7.代码实现(改进后)
//优先队列改进Huffman算法
#include
#include
#include
#include
const int INF = 1e7;
using namespace std;
// 定义存储Huffman节点的结构体
struct HNode{
int id; // 当前节点id(新加)
double weight; // 权值
int parent; // 父节点id
int lchild; // 左孩子id
int rchild; // 右孩子id
char sign; // 该节点标识
HNode() {}
HNode(int _id, double _weight, int _lchild, int _rchild): id(_id), weight(_weight), lchild(_lchild), rchild(_rchild){}
// 自定义比较规则
bool operator > (const HNode& node) const{
return this->weight > node.weight;
}
};
// 定义存储Huffman编码的结构体
struct HCode {
char sign; // 当前的字符标识
string codeStr; // 存储编码的字符串
};
// 构造Huffman树
vector HuffmanTree(int n) {
// 定义Huffman结点,n个字符需要构造哈夫曼树2 * n - 1
vector tree(2 * n - 1);
// 初始化
for (int i = 0; i < 2 * n - 1; i++) {
tree[i].id = i;
tree[i].weight = 0;
tree[i].parent = -1;
tree[i].lchild = -1;
tree[i].rchild = -1;
}
cout << "请分别输入" << n << "个节点的标识和权值(以空格隔开):" << endl;
for (int i = 0; i < n; i++) {
cin >> tree[i].sign >> tree[i].weight;
}
// 建立优先队列存储树的根节点的集合
std::priority_queue < HNode, std::vector, std::greater> q;
for (int i = 0; i < n; i++) {
//将所有节点(可看成时只有一个根节点的树)加入优先队列,按权值大小进行排序
q.push(tree[i]);
}
int diff = 0; // diff表示新加入节点的个数
while (q.size() > 1) {
HNode node1 = q.top(); q.pop();
HNode node2 = q.top(); q.pop();
// 将新树的根节点加入到优先队列中
q.push(HNode(n + diff, node1.weight + node2.weight, node1.id, node2.id));
// 更新tree
tree[node1.id].parent = n + diff;
tree[node2.id].parent = n + diff;
tree[n + diff].weight = node1.weight + node2.weight;
tree[n + diff].lchild = node1.id;
tree[n + diff].rchild = node2.id;
diff += 1;
//cout << tree[node1.id].sign << " and " << tree[node2.id].sign << " " << endl;
}
return tree;
}
// Huffman编码(从树自底向上得到每个叶节点的Huffman编码)
vector HuffmanCode(vector& tree, int n ) {
// 定义存储各个字符编码的HCode数组
vector codes;
int cur, p; // 当前节点的id和当前节点的父id
for (int i = 0; i < n; i++) {
HCode hc;
hc.sign = tree[i].sign;
// 初始化cur和p
cur = i;
p = tree[cur].parent;
while (p != -1) {
// 判断当前节点属于左孩子还是右孩子
if (tree[p].lchild == cur) {
hc.codeStr.insert(hc.codeStr.begin(), '0');
}
else
hc.codeStr.insert(hc.codeStr.begin(), '1');
// 更新cur和p
cur = p;
p = tree[cur].parent;
}
codes.push_back(hc);
}
return codes;
}
// 打印各个字符的Huffman编码
void PrintHuffmanCode(vector& codes) {
cout << endl;
for (const auto & a : codes) {
cout << a.sign << " 的Huffman编码为: " << a.codeStr << endl;
}
}
int main() {
int n;
cout << "请输入要编码的字符的个数:" << endl;
cin >> n;
vector tree = HuffmanTree(n);
vector codes = HuffmanCode(tree, n);
PrintHuffmanCode(codes);
return 0;
}
8.实验结果(改进后)
请输入要编码的字符的个数:
6
请分别输入6个节点的标识和权值(以空格隔开):
a 0.05
b 0.32
c 0.18
d 0.07
e 0.25
f 0.13
a 的Huffman编码为: 1000
b 的Huffman编码为: 11
c 的Huffman编码为: 00
d 的Huffman编码为: 1001
e 的Huffman编码为: 01
f 的Huffman编码为: 101
D:\projects\test\x64\Release\test.exe (进程 11768)已退出,返回代码为: 0。

我是lioney,年轻的后端攻城狮一枚,爱钻研,爱技术,爱分享。
个人笔记,整理不易,感谢阅读、点赞和收藏。
文章有任何问题欢迎大家指出,也欢迎大家一起交流后端各种问题!

















 2398
2398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









