






 本文深入探讨数组的理论,包括数组的随机访问、查找时间复杂度、与链表的区别,以及数组的插入、删除操作。文章指出数组的效率问题,并介绍了C++和Java中数组的访问越界问题。接着,文章转向JVM的垃圾回收机制,讲解了标记清除、复制、标记整理和分代收集等算法,为理解内存管理提供深入见解。
本文深入探讨数组的理论,包括数组的随机访问、查找时间复杂度、与链表的区别,以及数组的插入、删除操作。文章指出数组的效率问题,并介绍了C++和Java中数组的访问越界问题。接着,文章转向JVM的垃圾回收机制,讲解了标记清除、复制、标记整理和分代收集等算法,为理解内存管理提供深入见解。
引入开篇问题:
为什么在大部分编程语言中,数组都是从0开始编号。
引入线性表和非线性表:
线性表(Linear List),就是数据排成像一条线一样的结构。每个线性表上的数据最多只有前和后两个方向,包括数组,链表、队列、栈等。
什么是数组?数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
在有些编程语言中比如说python中,数组是用列表来代替的

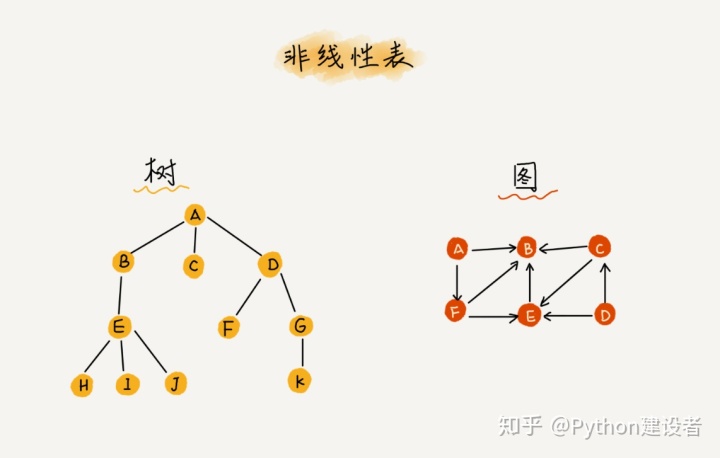
非线性表,数据之间并不是简单的前后关系,有二叉树、堆、图等,如下图:
数组实现随机访问的方法
数组使用了连续的内存空间和相同类型的数据。使得它可以“随机访问”,但同时也让数组的删除、插入等操作变得非常低效,为了保证连续性,就需要做大量的数据搬移工作。
数组是如何实现根据下标随机访问数组呢?
以一个长度为 10 的 int 类型的数组 int[] a = new int[10]为例。
计算机会给每个内存单元分配一个地址,并通过地址来访问内存中的数据。
下图中,假设计算机给数组 a[10],分配了一块连续内存空间 1000~1039,其中,内存块的首地址为 base_address = 1000。
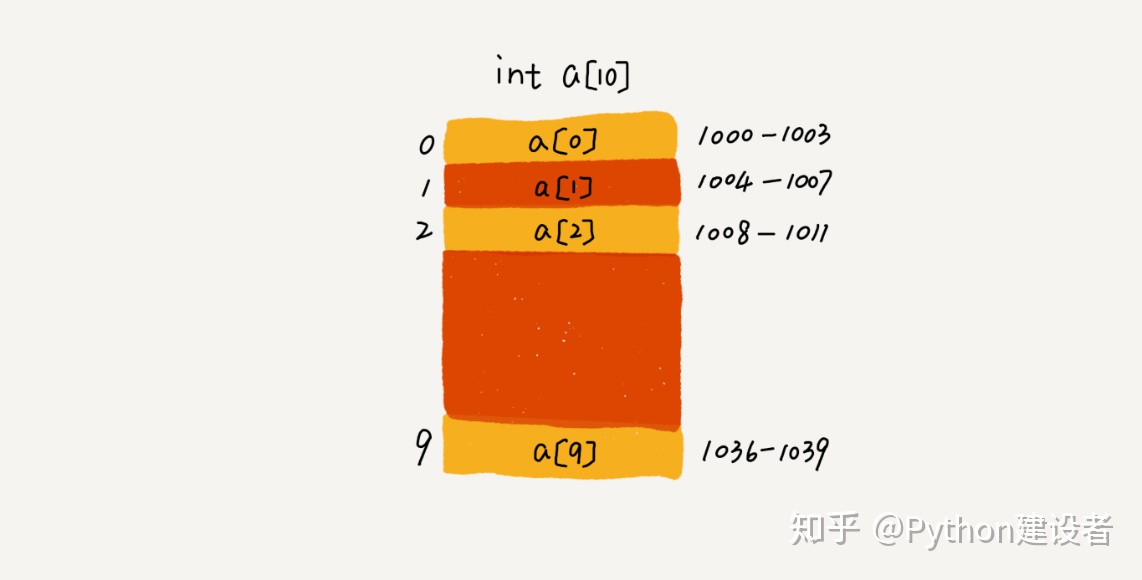
当计算机需要随机访问数组中的某个元素时,它会首先通过下面的寻址公式,计算出该元素存储的内存地址:
a[i]_address = base_address + i * data_type_size- data_type_size 表示数组中每个元素的大小。
上面的数组中存储的是 int 类型数据,所以 data_type_size 就为 4 个字节。
数组查找的时间复杂度
数组支持随机访问,根据下标随机访问的时间复杂度为 O(1)。
排好序的数组用二分查找,时间复杂度是 O(logn);
顺序查找,最好时间复杂度为 O(1),最差时间复杂度为O(n),平均时间复杂度为O(n)
均摊时间复杂度为O(n)
数组和链表的区别:
误区:很多人都回答说,“链表适合插入、删除,时间复杂度 O(1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2772
2772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









