





Ross B. Girshick在2016年提出了新的Faster RCNN,目前已经在 github 上有 xinlei chen 的 Tensorflow 版本代码,本文结合该代码梳理下Faster RCNN的原理。
Faster RCNN github : https://github.com/endernewton/tf-faster-rcnn
Faster CNN基本结构
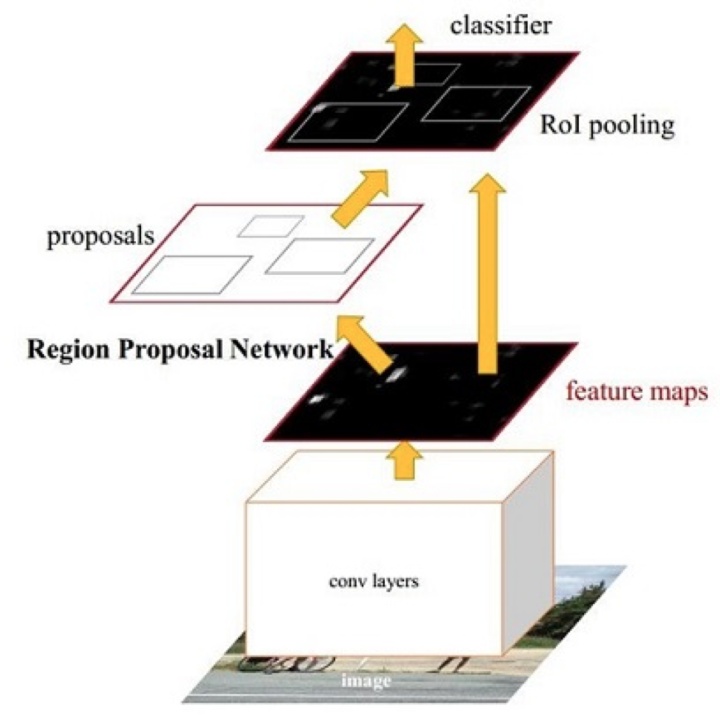
这幅图比较简单明了的说明了它的结构,Faster RCNN可以分为4个主要内容:
1. Conv layers。 Faster RCNN首先使用一组基础的conv+relu+pooling层提取image的feature maps。该feature maps被共享用于后续RPN网络和分类网络,这一部分可以理解为基础网络部分,通常使用VGG或resnet。
2. Region Proposal Networks。RPN网络用于生成region proposals。该部分判断anchors属于foreground或者background,RPN网络里面的前景和背景的网络就相当于一个‘注意力’机制,再利用bounding box regression修正anchors获得比较精确的proposals。
3. Roi Pooling。该层使用基础网络输出的feature maps和proposals(rois),生成固定大小的proposal feature maps,送入后续分类网络判定目标类别。
4. Classification。 所有的RCNN系列的方法都把检测的问题转换为对图片的局部区域的分类问题,利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置。
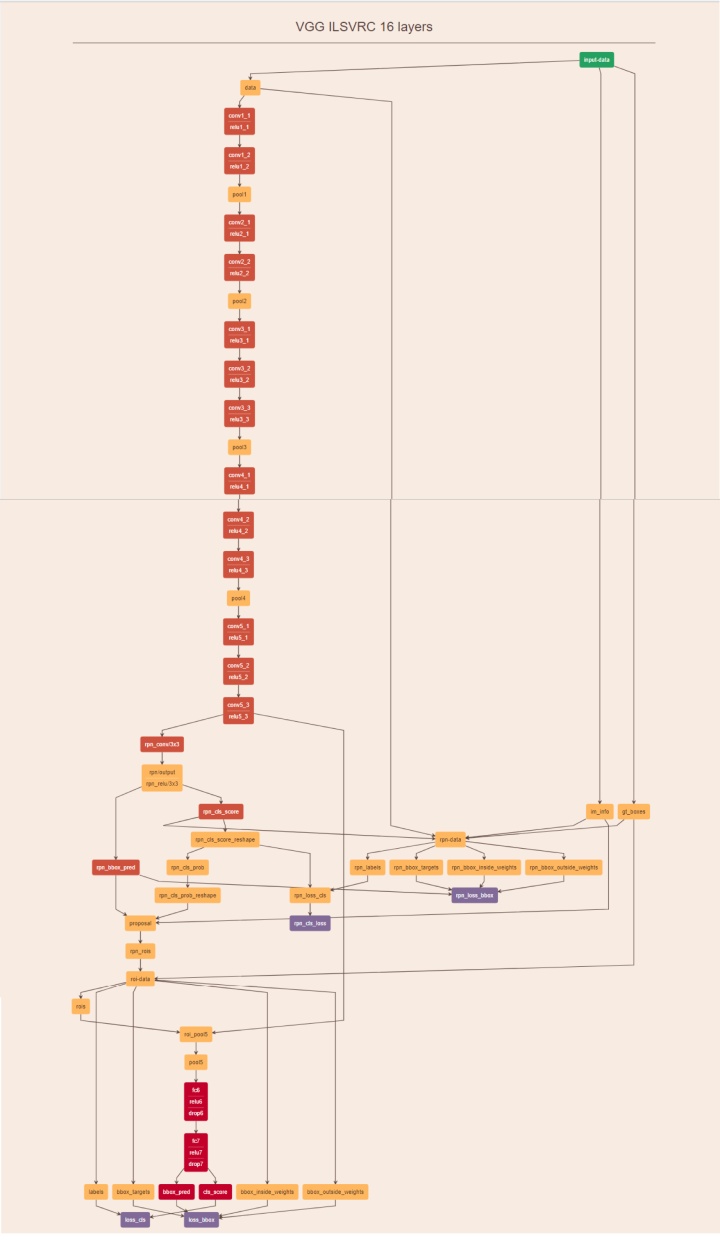
更加具体的Caffe 版本的Faster-RCNN网络结构图如下所示,理解该图对理解整个流程极为重要:
再结合这幅网络结构说明图,可以看的更加清楚:
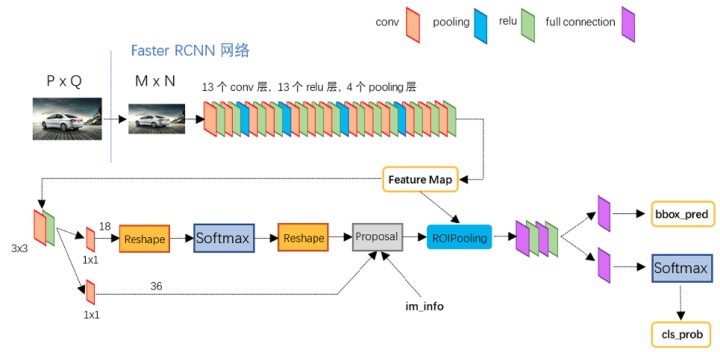
可以看到,经过了基础网络部分之后得到的 feature map,然后被分为两支,进而得到 proposal,最后通过ROI层得到固定大小的feature,最终进行分类。
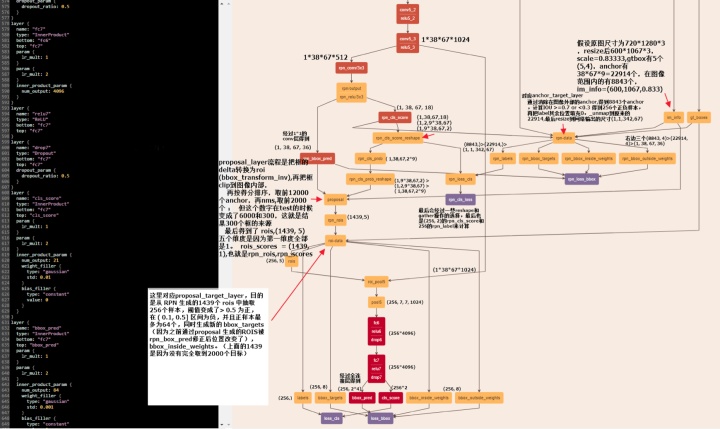
为了更加具体的了解网络的前馈以及训练过程,我把该图的前面抽取特征的基础网络部分略去,把后面部分每个节点的计算以及数据维度做了一个标注,图片如下:
为了更好理解代码结构,我画了个代码的结构图:
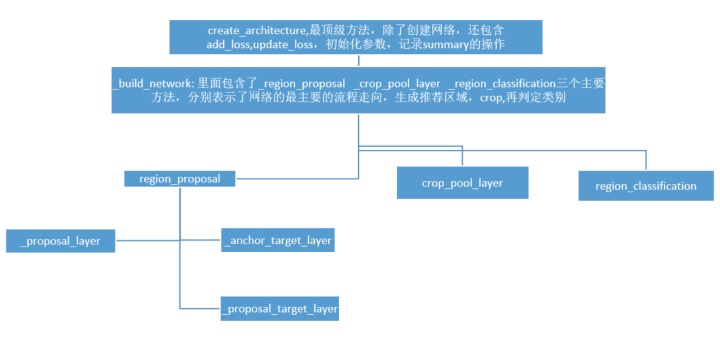
下面将通过代码的_build_network 方法下的3个主要网络层函数进行说明,分别是 _region_proposal ,_crop_pool_layer ,_region_classification,它们分别表示了方法的最主要的流程走向,生成推荐区域,crop, 再判定类别。同时,也对网络的其他必要部分细节做补充说明。
一.基础网络部分细节:
1. 代码中主要使用了两种尺寸,一个是原始图片尺寸,一个是压缩之后的图片尺寸;原始图片进入基础网络之前会被压缩到MxN,但MxN 并不是固定的尺寸,而是把原始图片等比例resize之后的尺寸,源代码里面设置的是压缩到最小边长为600,但是如果压缩之后最大边长超过2000,则以最大边长2000为限制条件。
2. 有博客文章资料写到还会有第三种尺寸,那就是还会把图片压缩到 VGG的224*224的尺寸,但是实际上这个步骤在tensorflow的版本中并没有用到,基础网络直接使用MxN的图片而并不需要再压缩到224*224,也许你会好奇这样不会影响后续的结果吗,实际上是不会的,因为这里并不需要像传统的分类网络那样最后接固定的数量的分类层,所以即便基础卷积部分最终出来的特征图大小不一致也没有影响。
3. 基础网络部分的说明,其中pooling层kernel_size=2,stride=2。这样每个经过pooling层的MxN矩阵,都会变为(M/2)*(N/2)大小,那么,一个MxN大小的矩阵经过Conv
layers中的4次pooling之后尺寸变为(M/16)x(N/16)。那么假设原图为720*1280,MxN为600*1067,基础网络最终的conv5_3 输出为1*38*67*1024。
4. 在代码中经常用到的im_info是什么?
blobs['im_info'] = np.array([im_blob.shape[1], im_blob.shape[2],im_scales[0]]可以看到,它里面包含了三个元素,图片的width,height,以及im_scales,也就是图片被压缩到600最小边长尺寸时候被压缩的比例,比如以3中提到的为例,它就是0.8333。
5. Blobs 是什么? 它里面包含了groundtruth 框数据,图片数据,图片标签的一个字典类型数据,需要说明的是它里面每次只有一张图片的数据,Faster RCNN 整个网络每次只处理一张图片,这是和我们以前接触的网络按照batch处理图片的方式有所区别的;同时,代码中涉及到的 batch_size 不是图片的数量,而是每张图片里面提取出来的框的个数;mini_batch 是从一张图上提取出来的256个anchor,不同的是,caffe 版本的代码是使用2张图片,每张图片128个anchor进行训练。
6. imdb分别是什么?
imdb是一个类,它对所有图片名称,路径,类别等相关信息做了一个汇总,以及如下主要函数功能:
gt_roidb :获取roidb ,_load_pascal_annotation将 xml文件信息存储为pkl,
_do_python_eval :计算mAP
_write_voc_results_file : 写结果文件
append_flipped_images:但是这里并没有翻转图片,只是把GTbox的x坐标用width翻转。
7. Roidb是什么?
# A roidb is a list of dictionaries, each with the following keys:
# boxes
# gt_overlaps
# gt_classes
# flipped
"""Enrich the imdb's roidb by adding some derived
quantities that are useful for training. This function precomputes the maximum overlap,
taken over ground-truth boxes, between each ROI and each ground-truth box. The
class with maximum overlap is also recorded."""
roidb = get_training_roidb(imdb)
return imdb.roidb从这句代码和上面的两段信息来看,roidb是imdb的一个属性,里面是一个字典,包含了它的GTbox,以及真实标签和翻转标签
8. anchor 是什么?这里借用一点知乎作者马塔的回答:
anchor的本质是什么,本质是将相同尺寸的 conv5_3 层的输出,倒推得到不同尺寸的输入。接下来是anchor的窗口尺寸,详细说下这个尺寸的来源,最基本的anchor只有一个尺寸,是16*16的尺寸,然后设定了基本的面积scale是(8,16,32),用这三个scale乘以16就得到了三个面积尺寸(128^2,256^2,512^2),然后在每个面积尺寸下,取三种不同的长宽比例(1:1,1:2,2:1).这样一来,我们得到了一共9种面积尺寸各异的anchor。示意图如下:
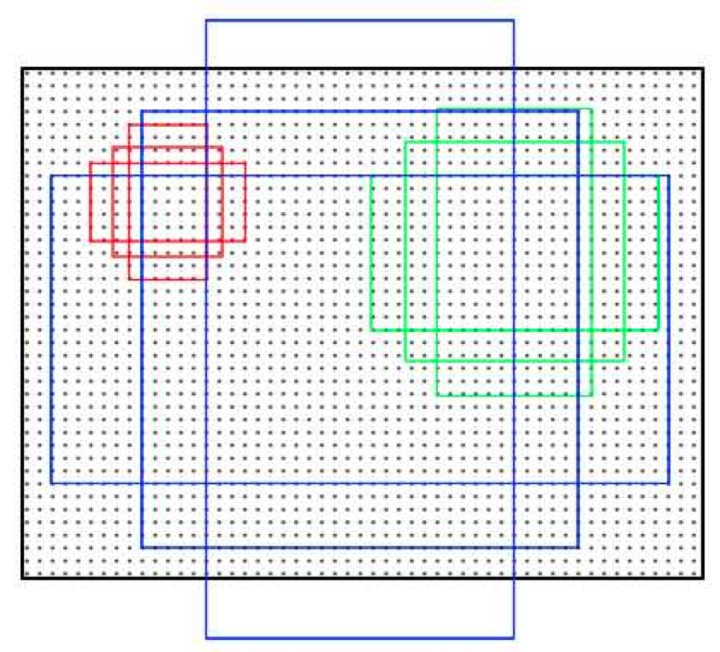
不过这个示意图其实比较有误导性,首先它图中的9个框并不是在同一个中心点的,而实际上,是应该在每个特征图的每个点作为中心点生成9 个框; 其次,生成的 anchor 尺寸大小不是以特征图为基准的,甚至毫无关系,而是以 anchor ratio 和 anchor scale 得到最终的大小,并且其最大的 anchor 也基本和 resize 之后的图大小相当。
在 generate_anchors 代码文件中,可以看到如下数据,
# anchors =
# -83 -39 100 56
# -175 -87 192 104
# -359 -183 376 200
# -55 -55 72 72
# -119 -119 136 136
# -247 -247 264 264
# -35 -79 52 96
# -79 -167 96 184
# -167 -343 184 360这就是生成的最基本的9个anchor,这个anchor的坐标是xyxy类型的,它表示了图片的左上角的第1个9个anchor的坐标,后面用到的所有anchor都是用它在特征图上平移得到的(它代表的坐标是resize 后的图片坐标而不是原图)。
至于这个anchor到底是怎么用的,这个是理解整个问题的关键。
上面我们已经得到了基础网络最终的conv5_3 输出为1*38*67*1024(1024是层数),在这个特征参数的基础上,通过一个3x3的滑动窗口,在这个38*67的区域上进行滑动,stride=1,padding=2,这样一来,滑动得到的就是38*67个3x3的窗口。
对于每个3x3的窗口,计算这个滑动窗口的中心点所对应的原始图片的中心点。然后作者假定,这个3x3窗口,是从原始图片上通过SPP池化得到的,而这个池化的区域的面积以及比例,就是一个个的anchor。换句话说,对于每个3x3窗口,作者假定它来自9种不同原始区域的池化,但是这些池化在原始图片中的中心点,都完全一样。这个中心点,就是刚才提到的,3x3窗口中心点所对应的原始图片中的中心点。如此一来,在每个窗口位置,我们都可以根据9个不同长宽比例、不同面积的anchor,逆向推导出它所对应的原始图片中的一个区域,这个区域的尺寸以及坐标,都是已知的。而这个区域,就是我们想要的 proposal。所以我们通过滑动窗口和anchor,成功得到了 38*67x9 个原始图片的proposal。接下来,每个proposal我们只输出6个参数:每个 proposal 和 ground truth 进行比较得到的前景概率和背景概率(2个参数)(对应 cls_score);由于每个 proposal 和 ground truth 位置及尺寸上的差异,从 proposal 通过平移放缩得到 ground truth 需要的4个平移放缩参数(对应 bbox_pred)。
加上一点我的理解,anchor 是用来做多尺度的目标检测的,它是用来代替图像金字塔和特征金字塔的,它为什么可以达到这样的目的?可以看看它的最后一层的输出是 M*N*(9*2), 如果我们只看它在特征图 M*N 个特征点的第一个点的第一个卷积核,它代表了什么含义?它相当于用这个卷积核去综合图片该点附近(3*3,上一步进行了3*3的卷积)的信息,判断有没有第一个尺寸的目标,也就是说每个卷积核都负责了一个尺寸的目标检测,那么18个卷积核,每2个负责一个任务,就达到了多尺度目标检测的目的,很巧妙的一个思路,从最终的效果来看,它实际上就是一个多尺度的目标热力图,或者用作者的话说,就相当于一个‘注意力’机制。
另外值得提出的是这里使用的是全卷积结构(3*3的卷积,然后接1*1的卷积),也就是说 M*N 也是一个二维结构,和原图的像素二维结构是对应的,那么我们就能相应的判断出该特征点对应的原图是否存在目标。 个人感觉,理解了这里的全卷积结构和 anchor 的机制,整个 faster rcnn 就明晰很多了。
如果上述你都没看懂,那我用大白话解释一下,其实很简单,anchor就是预先在每个可能的位置都画了很多框,然后通过RPN和后续的分类网络一次一次的筛选,最后得到比较准确的框,他就是从开始就假定可能存在要检测目标的那个区域。
最后明确的一点就是在代码中,anchor,proposal,rois ,boxes 代表的含义其实都是一样的,都是推荐的区域或者框,不过有所区别的地方在于这几个名词有一个递进的关系,最开始的是锚定的框 anchor,数量最多有约20000个(根据resize后的图片大小不同而有数量有所变化),然后是RPN网络推荐的框 proposal,数量较多,train时候有2000个,最后是实际分类时候用到的 rois 框,每张图片有256个;最后得到的结果就是 boxes。
二._region_proposal 部分(RPN)
1. _region_proposal 的下面有三个主要的方法:
- _proposal_layer
- _anchor_target_layer
- _proposal_target_layer
第一个主要生成推荐区域proposal和前景背景得分 rpn_scores, 第二个主要生成第一次anchor的label,rpn_bbox_targets,以及前景背景的label,rpn_labels。第三个生成256个rois的label, 以及这些rois的label,bbox_targets;有点绕,我们仔细梳理下:
2. _anchor_target_layer 主要功能是计算获得属于rpn网络的label。
通过对所有的anchor与所有的GT计算IOU,由此得到 rpn_labels, rpn_bbox_targets, rpn_bbox_inside_weights, rpn_bbox_outside_weights这4个比较重要的第一次目标label,通过消除在图像外部的 anchor,计算IOU >=0.7 为正样本,IOU <0.3为负样本,得到在理想情况下应该各自一半的256个正负样本(实际上正样本大多只有10-100个之间,相对负样本偏少)。
3. _proposal_layer 有二个主要功能。 1使用经过rpn网络层后生成的rpn_box_prob把anchor位置进行第一次修正. 2按照得分排序,取前12000个anchor,再nms,取前面2000个(但是这个数字在test的时候就变成了6000和300,这就是最后结果300个框的来源)。最终返回
proposals , scores,也就是rois, roi_scores。
4. _proposal_target_layer主要功能是计算获得属于最后的分类网络的label。
使用上一步得到的 proposals , scores,生成最后一步需要的labels, bbox_targets, bbox_inside_weights, bbox_outside_weights。
因为之前的anchor位置已经修正过了,所以这里又计算了一次经过 proposal_layer 修正后的的box与 GT的IOU来得到label, 但是阈值不一样了,变成了大于等于0.5为1,小于为0,并且这里得到的正样本很少,通常只有2-20个,甚至有0个,并且正样本最多为64个,负样本则有比较多个;相应的也重新计算了一次bbox_targets。
另外,这个函数的另外一个重要功能就是从RPN网络出来的2000余个rois中挑选256个:
labels, rois, roi_scores,bbox_targets, bbox_inside_weights = _sample_rois(all_rois, all_scores,gt_boxes, fg_rois_per_image, rois_per_image, _num_classes)三._crop_pool_layer 部分(替换Roi Pooling)
这一部分,作者使用了ROIpooling的另外一种实现形式,核心代码如下:
x1 进入的是:conv5_3 输出为1*38*67*1024, 以及256个rois代表的位置。
输出的是:
Tensor("resnet_v1_101_3/pool5/crops:0",shape=(256, 7, 7, 1024), dtype=float32)这里可以看到先对rois进行了一个转换操作,h,w是resize后的图像大小,把rois除以h,w就得到了rois在特征图上的位置,然后把conv5_3先crop,就是把roi对应的特征crop出来,然后resize到14*14的大小,resize是为了后面的统一大小,这个操作很有创意,也比较有意思,直接使用了tensorflow的图像处理方法 crop_and_resize 来进行类似 ROI 的操作,最后再做了一个减半的pooling操作,得到7*7的特征图。
四.其他细节理解
1.什么是NMS?
NMS是用来去掉冗余的框的。
NMS的原理是抑制和当前分数最大的框IOU较高的框。如果阈值设置为0.3, 那么就是所有与当前分数最大的框box的iou小于阈值的得到保留,而大于阈值的box被这个框吸收,也就是被剔除,而只保留当前分数最大的框,然后在下一次重复这个过程,通过去掉当前最大分数的box的可以吸收的box,来一步一步缩减box规模,所以阈值越小,吸收掉的框越多,阈值越大,保留的框越多
2. 回归框的位置的label和框的位置修正是怎么进行的?
bbox_transfrom计算回归label的过程就是一个计算的dx,dy,dw,dh的过程,只是dx,dy要除以宽和高,dw,dh
要做log操作,也就是说,计算的xy回归量是二个框中心的差值相对于原图宽和高的比例,是与宽和高的具体数值无关的,而wh的回归量也是在log空间内GT相对于原有宽和高的比例。
bbox_transform_inv从这里可以看出,修正框的位置又把上面的操作转回来了,中心乘以宽和高, dw,dh做e为底的幂运算。
需要注意的是,框的位置的回归仅仅针对框的位置进行小范围的修正,而不能进行大范围的修正; 另外,经过框的位置修正后,能有效提高框的位置的精确性,论文提到可以提高3%的mAP。
3.框box 的信息什么时候是resize后的图的坐标,xyxy or yxyx? 什么时候是delta? xywh?
rois一直都是resize的图的坐标,而回归得到的结果都是delta,也就是现在的框和真实框之间的平移量。
所有的target和预测得到的结果都是xywh格式的数据,也就是说所有的delta都是xywh格式的,每次计算_compute_targets(rois[:, 1:5],gt_boxes ) 之后就得到xywh格式的数据,因为它的里面是执行的bbox_transform,同样的,在 bbox_transform_inv 之后得到的就是xyxy格式数据,那么,可以知道所有的 bbox_pred, bbox_targets就都是xywh 格式的数据了。
4.batch_size 的区别?
有两个batch size,一个是__C.TRAIN.RPN_BATCHSIZE = 256,这是用在RPN网络里面的,
num_fg 另外一个是:
# Minibatch size (number of regions of interest [ROIs])
__C.TRAIN.BATCH_SIZE = 256
rois_per_image = cfg.TRAIN.BATCH_SIZE / num_images这个是用在最后的分类网络的,二者的数量都是256,但是后者的正样本比例更少,最多使用 1/4 的 正样本,即64个。
# Fraction of minibatch that is labeled foreground (i.e. class > 0)
__C.TRAIN.FG_FRACTION = 0.255.RPN的样本选取规则和最终Roi Pooling样本选取规则有何不同?
RPN网络样本选取规则:
- 对每个标定的真值候选区域,与其重叠比例最大的anchor记为前景样本
- 对a)剩余的anchor,如果其与某个标定重叠比例大于0.7,记为前景样本;如果其与任意一个标定的重叠比例都小于0.3,记为背景样本;正负样本共256个,最多各占一半
- 对a),b)剩余的anchor,弃去不用
- 跨越图像边界的anchor弃去不用
Roi Pooling样本选取规则:
- 从 RPN 生成的rois中抽取256个样本
- 阈值变成了> 0.5 为正, 在 ( 0, 0.5] 区间为负
- 正样本最多为64个
6.与原版caffe 代码有什么其他细节的区别?
- 去掉了小的的proposal(原图尺寸上的边长小于16个像素),但这样会损失模型在小物体检测上的精度,因此,这里并没有这个操作。
- 把bias的学习率乘以2,加倍。
for - biases不加入正则化过程,不进行weight_decay.
biases_regularizer = tf.no_regularizer7. anchor的box_target计算和proposal的box_target的计算的过程有一个细小的差异:
if cfg.TRAIN.BBOX_NORMALIZE_TARGETS_PRECOMPUTED:
# Optionally normalize targets by a precomputed mean and stdev
targets = ((targets - np.array(cfg.TRAIN.BBOX_NORMALIZE_MEANS)) / np.array(cfg.TRAIN.BBOX_NORMALIZE_STDS))proposal的box_target多一个标准化的过程,BBOX_NORMALIZE_MEANS是全0,没有影响,除以BBOX_NORMALIZE_STDS(0.1,0.1,0.2,0.2)相当于把box_target扩大了10倍和5倍。
同时有:
if 同样的,在测试的时候把这个扩大了10倍的预测框的值修正过来了。
8. bbox_inside_weights, bbox_outside_weights 这两个权重具体是什么意思?
# Deprecated (outside weights)
所以可以看出,bbox_inside_weights 它实际上就是控制回归的对象的,只有真正是前景的对象才会被回归。
# Give the positive RPN examples weight of p * 1 / {num positives}
可以看出,bbox_outside_weights 也是用1/N1, 2/N0 初始化,对前景和背景控制权重,比起上面多了一个背景的权重,从第二步来看, positive_weights ,negative_weights有互补的意味。
这两个参数都是在 _smooth_l1_loss 里面使用,
rpn_loss_box 可以看出,bbox_outside_weights 就是为了平衡 box_loss,cls_loss 的,因为二个loss差距过大,所以它被设置为 1/N 的权重。
论文提到的 _smooth_l1_loss 相当于一个二次方函数和直线函数的结合,但是为什么要这样呢?不太懂,论文说它比较鲁棒,没有rcnn中使用的L2 loss 那么对异常值敏感,当回归目标不受控制时候,使用L2 loss 会需要更加细心的调整学习率以避免梯度爆炸?_smooth_l1_loss消除了这个敏感性。
9. 其他
- 每个网络都有一个 .yml 设置文件,里面的设置会覆盖通用设置
- 该代码没有使用 caffe 的循环的迭代训练,即先训练 RPN,再训练分类网络,而是直接一步到位的训练方式
- 代码作者提到有两种测试模式 top 和 nms, # Testing mode, default to be 'nms', 'top' is slower but better。 但实际经过测试,top 并没有表现更好。
- 中间产生的结果都保存为 pickle 文件
- stepsize 是控制学习率的参数
- 有人问到,在训练的时候,前面的基础网络(比如 VGG 或者 resnet)的参数是否也会更新,实际上是会的
- 另外,代码中对网络的输入第一层的通道顺序做了一个转换,是因为 cv2读入的图片的通道顺序是 BGR,和通常的 RGB的顺序相反,所以作者把模型的参数的第三维的顺序也调换了
五.待解答
不过,有个地方我一直没想明白的:
在 test.py 文件的 im_dect() 函数中, 95行有 :
boxes 为什么 rois 要先除以 im_scales[0]? 它这样操作后会导致 boxes 是在原图尺寸上的,但是 bbox_transform_inv 时候使用的 box_deltas 应该是在 resize 的图片尺寸上的,因为 box_target 就是在 resize 之后的图片上计算的,应该如何理解这种矛盾,我能想到的唯一的解释是 box_deltas 在两种图片尺寸上都是一样的效果,为了验证这个解释,我先进行bbox_transform_inv,再除以im_scales[0],得到的效果却明显不同,框的位置明显偏移,因此这个解释行不通,这个地方希望有懂的人不吝赐教。

















 451
451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









