





 本文探讨了图数据结构的应用场景,如好友系统,并介绍了图的基础知识,包括顶点、边、度、无向图和有向图。讨论了图的存储方式,如邻接矩阵和邻接表,分析了它们的优缺点。接下来的文章将介绍图的遍历算法——广度优先遍历和深度优先遍历。
本文探讨了图数据结构的应用场景,如好友系统,并介绍了图的基础知识,包括顶点、边、度、无向图和有向图。讨论了图的存储方式,如邻接矩阵和邻接表,分析了它们的优缺点。接下来的文章将介绍图的遍历算法——广度优先遍历和深度优先遍历。
其实关于图我一直在思考用什么样的方式来分享比较好,因为图是我觉得比较复杂的一个数据结构。其他的数据结构可以认为是线性的数据结构,而图是一个非线性的数据结构。思考了几天,认为还是循序渐进比价好,即使是有基础的小伙伴经过时间的洗礼或许也忘了一些。刚好借着这篇文章,来一起慢慢回忆起来。
应用场景
我们先看看图的生活应用场景,比如好友系统。无论什么软件大部分都有一套自己的好友系统,对于IM系统(即时通讯系统,例如微信和QQ等)来说,好友系统更是重中之重。那应该用什么数据结构保存实现好友系统呢?
关系型数据库
比如Mysql,这很明显的是一个多对多的关系。我们可以构建一个关系表,把每一条关系都维护在里面。这显然可以做到且没有大问题。但是现在很多的IM系统都有好友推荐系统,而且推荐准确率还挺高,基于关系型数据库该如何实现这种推荐功能呢?答案是很困难,几乎没有哪个厂商给出一套完整简洁的实现方案。
图数据库
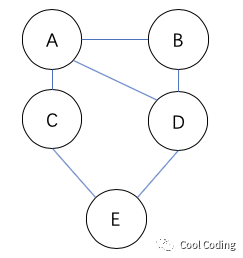
假如我们按上图来保存关系,一个连线链接的两个端点表示是好友关系。可以看出BCD都是A的好友,并且E是CD的好友,那么大概率E也是A认识的人,基于这个图,系统就会给A推荐E。
可以看出用图来描述关系网络是一个很好的选择,简洁清晰,做推荐和预测可以用很好的效果。目前JAVA也有一套成熟的框架叫做Neo4J。
图的基础知识点
顶点:
就是图上的每个点,ABCDE这五个点都称作是图的端点。
边:
连接两个顶点的线称为边。
度:
每个顶点边的数量。
无向图:
边不带方向的图。
有向图:
边带方向的图。
出度,入度:
每有一条指向该顶点的有向边则入度+1;
每有一条从该顶点出发指向别的顶点的有向边则出度+1.
权值:
边的权重。
比如有ABC三个城市,A到B长度为100公里,A到C为200公里,那么可以简单地认为AB的边权重为1,AC的边权重为2。
图的存储
邻接矩阵
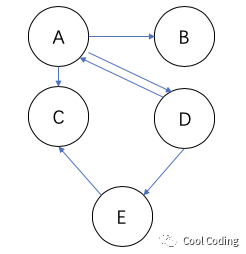
假如我们来保存如上的有向图,我们可以用下面的表格来描述这个图。我们按表头->表列来描述从某个节点到某个节点的关系,1表示有边,0表示没有。比如表格第二列,分别描述A到A没有路径,A到B有路径,A到C有路径,A到D有路径,A到E没路径。后面的列以此类推。
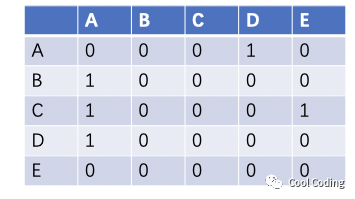
我们知道这就是矩阵,而矩阵的本质就是一个二维数组,因此我们可以用Array[0][0] = 0表示A到A没有路径,Array[0][1] = 1表示A到B有路径。以此类推我们就用一个二维数组存储了图,而这个二维数组就称作邻接矩阵。
邻接表
邻接表本质就是链表,链表的表头就是该节点,后续的节点表示该节点可以访问到的节点。比如A->B->C->D描述A可以到达BCD节点。
孰优孰劣,其实这个我们在数组和列表中已经说过,邻接矩阵空间占用大,扩容困难,但是访问快。邻接表则空间占用少,扩容方便,但是访问慢(相对邻接矩阵)。大家可以根据实际情况来选择用什么来保存图。
本次分享到此为止。下次我们分享图的两种遍历方式,广度优先遍历和深度优先遍历。
The end

Cool Coding
喜欢就关注我,和我一起玩吧~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









